《大数据分析》专题
-
Spark数据帧的分区数
有人能解释一下将为Spark Dataframe创建的分区数量吗。 我知道对于RDD,在创建它时,我们可以提到如下分区的数量。 但是对于创建时的Spark数据帧,看起来我们没有像RDD那样指定分区数量的选项。 我认为唯一的可能性是,在创建数据帧后,我们可以使用重新分区API。 有人能告诉我在创建数据帧时,我们是否可以指定分区的数量。
-
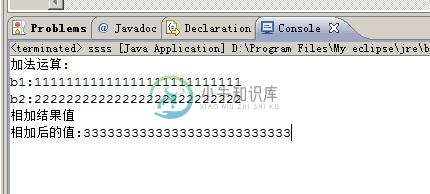 java中最大的整数用法分析
java中最大的整数用法分析本文向大家介绍java中最大的整数用法分析,包括了java中最大的整数用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了java中最大的整数用法。分享给大家供大家参考,具体如下: 8种基本数据类型中,long类型所能表示的整数范围是最大的,但还是有限的。另外,基本数据类型中的整数还有一个问题,那就是不是每个数都能够正确的取负数。例如,对int型而言,“-2147483648”取负就不
-
插入sql数据库时处理大量数据
问题内容: 在我的代码中,用户可以上传一个excel文档,希望其中包含电话联系人列表。作为开发人员,我应阅读excel文件,将其转换为dataTable并将其插入数据库。问题是某些客户拥有大量的联系人,例如说5000个和更多的联系人,而当我尝试将这种数据量插入数据库时,它崩溃了,并给了我一个超时异常。避免这种异常的最佳方法是什么?它们的任何代码都可以减少insert语句的时间,从而使用户不必等
-
将大量数据加载到Oracle SQL数据库
问题内容: 我想知道是否有人对我即将从事的工作有任何经验。我有几个csv文件,它们的大小都在一个GB左右,我需要将它们加载到oracle数据库中。虽然加载后我的大部分工作都是只读的,但我仍需要不时加载更新。基本上,我只需要一个很好的工具即可一次将多行数据加载到数据库中。 到目前为止,这是我发现的内容: 我可以使用SQL Loader来完成很多工作 我可以使用批量插入命令 某种批量插入。 以某种方式
-
数据科学家,数据工程师,数据分析师之间的区别。
本文向大家介绍数据科学家,数据工程师,数据分析师之间的区别。,包括了数据科学家,数据工程师,数据分析师之间的区别。的使用技巧和注意事项,需要的朋友参考一下 数据科学家,数据工程师和数据分析师是信息技术公司中的各种职位档案。 数据科学家 数据科学家是一个非常特权的工作,负责监督整体功能,提供监督以及对信息,数据的未来显示的关注。 数据工程师 数据工程师专注于技术优化,以所需格式构建数据等。 数据分析
-
了解TCP数据包大小限制和UDP数据包大小限制
我正在使用在我的客户端应用程序中执行以及 最大数据包大小限制也存在于中,即?但是我可以使用中的发送大于最大数据包大小的数据块 这是怎么运作的?这是因为是基于流的,负责在较低层创建数据包吗?有什么方法可以增加UDP中的最大数据包大小吗? 当我在客户端读取时,我从服务器端发送的UDP数据包的一些字节是否可能丢失?如果是,那么有没有办法只检测UDP客户端的损失?
-
 上海银行大数据开发(数仓)数据一面
上海银行大数据开发(数仓)数据一面离线数仓项目介绍 hdfs读流程 hdfs 中datanode怎么与namenode交互 mr过程 hive数据倾斜,介绍原因和解决方案 介绍一下网络结构,tcp在哪一层 java有哪些集合类 介绍java接口 MySQL索引 数据结构(B+树) 反问 上海银行数仓技术框架
-
Spring数据r2dbc和分组依据
我正在使用DatabaseClient执行sql查询,我不知道如何通过以下方式进行分组:
-
从多维数组中放大数据
问题内容: 我是PHP的新手,我需要针对以下问题的快速解决方案,但似乎无法提出一个解决方案: 我有一个像这样的多维数组 我想使用来以某种方式返回包含逗号的字符串分隔字符串,像这样。 通过上述功能有可能达到这种效果吗?如果没有,请提出替代解决方案。 问题答案: 非常简单: 以及php v5.5.0中的新功能:
-
 数分各大厂面经奉上
数分各大厂面经奉上#软件开发笔面经#
-
 SqlServer 数据库 三大 范式
SqlServer 数据库 三大 范式本文向大家介绍SqlServer 数据库 三大 范式,包括了SqlServer 数据库 三大 范式的使用技巧和注意事项,需要的朋友参考一下 1 概述 一般地,在进行数据库设计时,应遵循三大原则,也就是我们通常说的三大范式,即第一范式要求确保表中每列的原子性,也就是不可拆分;第二范式要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,
-
neo4j中的大数据导入
我正在导入大约1200万个节点和1300万个关系的数据。 是否可以在短时间内直接从sql导入这些数据,因为neo4j以其快速处理大数据而闻名?有什么建议或帮助吗? 以下是CSV使用的加载(数字上的索引(num)):
-
Postgres数据库大小命令
查找所有数据库大小的命令是什么? 我可以使用以下命令找到特定数据库的大小:
-
 蔚来大数据笔试 7.17
蔚来大数据笔试 7.17第一题合并两个二叉树lc617 第二题爬楼梯,多少种爬法,10000级楼梯 第三题滑动窗口的最大值lc239 #蔚来提前批笔试#
-
 京东方大数据面试
京东方大数据面试7.22一面 spark的底层原理 spark yarn client和yarn cluster的区别 dataframe如何创建 数仓项目中用了几个节点,各个组件如何部署的 HA介绍一下 数仓分层介绍 hadoop的一些命令 hadoop如何更改文件所有者 kafka的监控 linux命令,vim编译器的命令 集群间节点是如何通信的 core-site文件一般配置什么内容 ranger权限管理的