《数据分析师面经》专题
-
词法分析 Tokenizer
上一篇文章讲到了状态机和词法分析的基本知识,这一节我们来分析Jsoup是如何进行词法分析的。 代码结构 先介绍以下parser包里的主要类: Parser Jsoup parser的入口facade,封装了常用的parse静态方法。可以设置maxErrors,用于收集错误记录,默认是0,即不收集。与之相关的类有ParseError,ParseErrorList。基于这个功能,我写了一个PageEr
-
8.4 格网分析
提示: ●格网形状:正方形、六边形。 ●格网边长:200至50000米。 ●统计方式包含:计数、密度、求和、平均值、比值。 注意: ①在分析图层下有格网指标计算公式。 ②分析出的格网数据会在新的图层显示,图层名称叫"格网分析"。 操作步骤: ①选择"统计分析"模块。 ②点击"格网分析"。 操作动图: [查看原图]
-
8 空间分析
亿景智图除了提供简便丰富的可视化功能,还提供了分析功能供决策者使用,目前已提供的分析功能有: ● 汇总区域内标注数据 ● 缓冲区分析 ● 分析标注属于哪个区域 ● 格网分析
-
2.统计分析
统计分析 点面互查 缓冲区分析 高级筛选
-
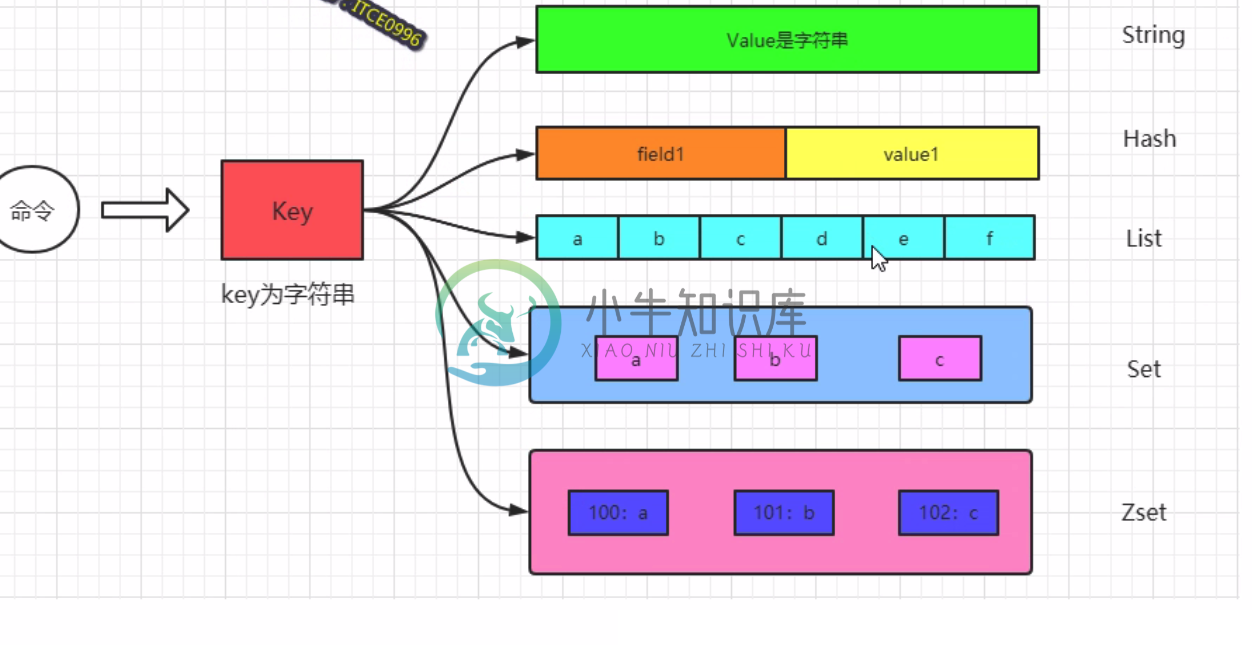 Redis底层分析
Redis底层分析主要内容:1.上帝视角,2.disctEntry,3.redisObject,4.string的type和3大编码转换,5.Redis底层的数据结构Redis为kv的,而Redis底层又是由c语言写成的,一切皆字典dict,和java的一切皆对象Object Redis的key类型一般为字符串,value为redis类型RedisObject这里的kv称为dictEntry 相当与java中的Map<String, redisObject> bitmap底层为String类型,hyperlogl
-
H.264 分析器
H.264分析器可以用来分析学习H.264码流结构。可以比较详细的列出H.264码流中NAL的信息。
-
 剑心互娱开发工程师一面面经
剑心互娱开发工程师一面面经新鲜出炉的面经,面试官迟到了几分钟,不会是早餐没吃完吧(bushi),这次居然没有录音,吐了,每次录音都会有幺蛾子。 先自我介绍一下 为什么投游戏公司 那先问一下基础的吧,遍历相同长度的数组和链表哪个更快?为什么? 答:和CPU缓存有关,数组是内存连续的所以CPU缓存命中率会高,所以遍历数组会更快。 问:为什么遍历数组,CPU缓存命中率会高? 答:CPU缓存机制具体我不太了解,我知道一般内存是以页
-
 百度 一面面经 开发测试工程师
百度 一面面经 开发测试工程师#百度##测试#小度质量部 072面试1h 1. 自我介绍 2. 项目具体情况 3. 实习情况 4. 工作中遇到多进程/多线程的问题 5. 序列号生成的方式 6. Python多线程和多进程的性能问题 (告知面试官自己理论方面是对Java更多了解一些 7. Java的数据类型有哪些 8. 整型占几个字节、int型数据范围 9. Java中String类直接赋值一个常量和直接new一个新的对象的区别
-
 库洛产品测试工程师 一面面经
库洛产品测试工程师 一面面经工作流程,从测试评审开始 活动更新时,需要下载吗 活动的实现,是h5还是什么代码 需不需要更新客户端 客户端用什么抓包,怎么测性能测试 热更时, 有没有用fidder抓过包 jmeter用过什么元件 对jmeter的了解 了解sdk吗 对水杯进行测试用例 自动化有多了解(回答了python的slumun的操作过程) 有没有做过接口自动化 知不知道数据库索引是干什么的 反问环节(可以关注一下程序如何
-
 东方财富 测试工程师 一面面经
东方财富 测试工程师 一面面经SQL中delete和drop的区别 OSI七层模型是什么 实习经历+项目经历 测试一个ATM机 对测试的看法 未来的方向(有没有打算往测开发展) 还有啥我实在是忘了面了好多天了 一面过了等待二面中,写面经攒人品
-
 字节跳动Android工程师面经|一、二面
字节跳动Android工程师面经|一、二面一面 1. 抽象类和接口的区别 1)抽象类需要使用extends关键字继承,而接口需要使用implements实现。 2)抽象类的权限可以为public、protected、default,而接口权限必须为public。 3)抽象类既可以做方法申明也可以进行方法实现,而接口只能做方法申明。 可能有坑(面试官可能会问Java8新特性中的接口的默认方法) 4)抽象类中的变量为普通变量,而接口中只能有被
-
 OPPO安卓工程师一、二面面经(社招)
OPPO安卓工程师一、二面面经(社招)我11月顺利拿到了OPPO公司Android工程师offer,我有三年多的工作经验,这次面试历经两轮,终于是拿到了offer,一面是以项目来展开的,简历上的东西一定要熟悉,面试官就是通过简历去问,然后会针对项目中遇到的问题,让你现场给你解决方案。 二面是由部门的主管负责面试,主要也是询问工作上的一些事,大头当然还是项目上的经历,遇到的难点和解决办法,还针对团队合作问题上提了一些问题,类似于结构化面
-
 蔚来 前端工程师 技术一面 面经
蔚来 前端工程师 技术一面 面经面试岗位:前端工程师,base上海 面试时间:9.9,24分钟 面试题目: 1、自我介绍 2、什么时候开始学前端 3、为什么想找前端工作 4、怎么学前端的 5、简历上的某个项目的登录功能是怎么做的 6、还有别的方式可以实现登录功能吗 7、浏览器存储方式,以及它们的区别(Cookie、localStorage、sessionStorage) 8、Vue2和Vue3的区别 9、分页功能怎么实现,前端和
-
 沐瞳 前端工程师 技术一面 面经
沐瞳 前端工程师 技术一面 面经面试岗位:前端工程师,base上海 面试时间:9.6,39分钟 面试题目: 没有自我介绍 1、介绍一下你的专业 2、为什么搞前端 3、怎么学习前端的,每天花多少时间学前端 4、详细聊了一下简历上的几个项目 5、项目来源,有参考借鉴吗 6、聊了一下实习 7、实习学习到的规范包括哪些 8、项目和实习中的难点 9、哪里用到了TS泛型 10、哪里用到了call、apply、bind改变this指向 11、
-
 奇安信 前端工程师 HR三面 面经
奇安信 前端工程师 HR三面 面经面试岗位:前端工程师,base武汉 面试时间:10.7,29分钟 面试题目: 1、自我介绍 2、呆在实验室的时间,要打卡吗 3、硕士阶段主要做了哪些事情 4、几年的硕士 5、奖学金 6、哪里人,为什么投武汉 7、对奇安信有哪些了解 8、个人爱好 9、为什么想做前端 10、职业规划 11、找工作看中哪些东西 12、对前两轮面试官的评价 反问: 1、应届生培养 2、工作强度 3、什么时候出结果 面试感