
词法分析 Tokenizer
上一篇文章讲到了状态机和词法分析的基本知识,这一节我们来分析Jsoup是如何进行词法分析的。
代码结构
先介绍以下parser包里的主要类:
ParserJsoup parser的入口facade,封装了常用的parse静态方法。可以设置
maxErrors,用于收集错误记录,默认是0,即不收集。与之相关的类有ParseError,ParseErrorList。基于这个功能,我写了一个PageErrorChecker来对页面做语法检查,并输出语法错误。Token保存单个的词法分析结果。Token是一个抽象类,它的实现有
Doctype,StartTag,EndTag,Comment,Character,EOF6种,对应6种词法类型。Tokeniser保存词法分析过程的状态及结果。比较重要的两个字段是
state和emitPending,前者保存状态,后者保存输出。其次还有tagPending/doctypePending/commentPending,保存还没有填充完整的Token。CharacterReader对读取字符的逻辑的封装,用于Tokenize时候的字符输入。CharacterReader包含了类似NIO里ByteBuffer的
consume()、unconsume()、mark()、rewindToMark(),还有高级的consumeTo()这样的用法。TokeniserState用枚举实现的词法分析状态机。
HtmlTreeBuilder语法分析,通过token构建DOM树的类。
HtmlTreeBuilderState语法分析状态机。
TokenQueue虽然披了个Token的马甲,其实是在query的时候用到,留到select部分再讲。
词法分析状态机
现在我们来讲讲HTML的词法分析过程。这里借用一下http://ued.ctrip.com/blog/?p=3295里的图,图中描述了一个Tag标签的状态转移过程,
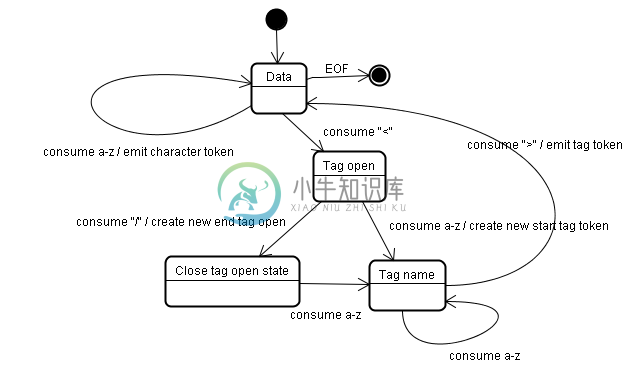
这里忽略了HTML注释、实体以及属性,只保留基本的开始/结束标签,例如下面的HTML:
<div>test</div>
Jsoup里词法分析比较复杂,我从里面抽取出了对应的部分,就成了我们的miniSoupLexer(这里省略了部分代码,完整代码可以看这里MiniSoupTokeniserState):
enum MiniSoupTokeniserState implements ITokeniserState {
/**
* 什么层级都没有的状态
* ⬇
* <div>test</div>
* ⬇
* <div>test</div>
*/
Data {
// in data state, gather characters until a character reference or tag is found
public void read(Tokeniser t, CharacterReader r) {
switch (r.current()) {
case '<':
t.advanceTransition(TagOpen);
break;
case eof:
t.emit(new Token.EOF());
break;
default:
String data = r.consumeToAny('&', '<', nullChar);
t.emit(data);
break;
}
}
},
/**
* ⬇
* <div>test</div>
*/
TagOpen {
...
},
/**
* ⬇
* <div>test</div>
*/
EndTagOpen {
...
},
/**
* ⬇
* <div>test</div>
*/
TagName {
...
};
}
参考这个程序,可以看到Jsoup的词法分析的大致思路。分析器本身的编写是比较繁琐的过程,涉及属性值(区分单双引号)、DocType、注释、HTML实体,以及一些错误情况。不过了解了其思路,代码实现也是按部就班的过程。
下一节开始介绍语法分析部分。