《游戏数据分析》专题
-
C语言实现三子棋小游戏详解
本文向大家介绍C语言实现三子棋小游戏详解,包括了C语言实现三子棋小游戏详解的使用技巧和注意事项,需要的朋友参考一下 在用C语言实现三子棋小游戏之前,我们应当了解三子棋的游戏规则:在九宫格棋盘上,哪一方三个棋子连成一线(一行或一列或对角线)即判定哪一方胜利。 以下为源代码: 1.首先打印出菜单。 2.创建一个二维数组board用来储存三子棋的元素,并对其进行初始化。 3.打印九宫格棋盘。 4.使用P
-
python实现的简单RPG游戏流程实例
本文向大家介绍python实现的简单RPG游戏流程实例,包括了python实现的简单RPG游戏流程实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现的简单RPG游戏流程。分享给大家供大家参考。具体如下: 希望本文所述对大家的Python程序设计有所帮助。
-
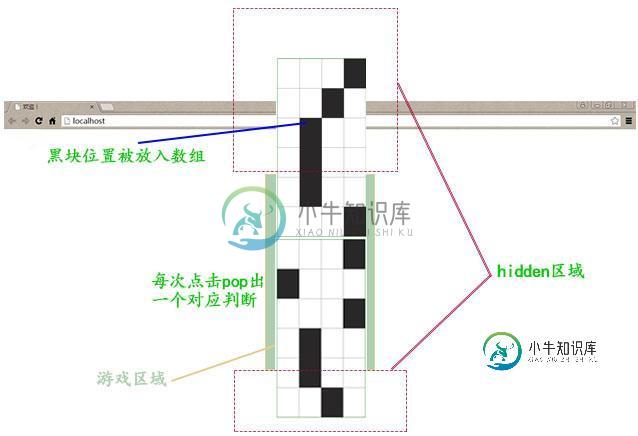 javascript实现别踩白块儿小游戏程序
javascript实现别踩白块儿小游戏程序本文向大家介绍javascript实现别踩白块儿小游戏程序,包括了javascript实现别踩白块儿小游戏程序的使用技巧和注意事项,需要的朋友参考一下 最近有朋友找我用JS帮忙仿做一个别踩白块的小游戏程序,但他给的源代码较麻烦,而且没有注释,理解起来很无力,我就以自己的想法自己做了这个小游戏,主要是应用JS对DOM和数组的操作。 程序思路:如图:将游戏区域的CSS设置为相对定位、溢出隐藏;两块“游
-
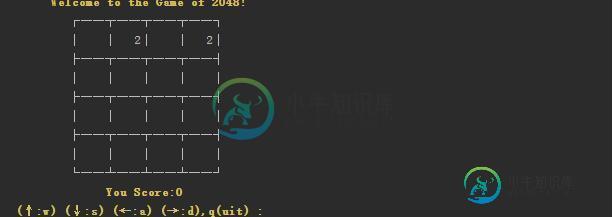 用Python写一个无界面的2048小游戏
用Python写一个无界面的2048小游戏本文向大家介绍用Python写一个无界面的2048小游戏,包括了用Python写一个无界面的2048小游戏的使用技巧和注意事项,需要的朋友参考一下 以前游戏2048火的时候,正好用其他的语言编写了一个,现在学习python,正好想起来,便决定用python写一个2048,由于没学过python里面的界面编程,所以写了一个极其简单的无界面2048。游戏2048的原理和实现都不难,正好可以拿来练手,要
-
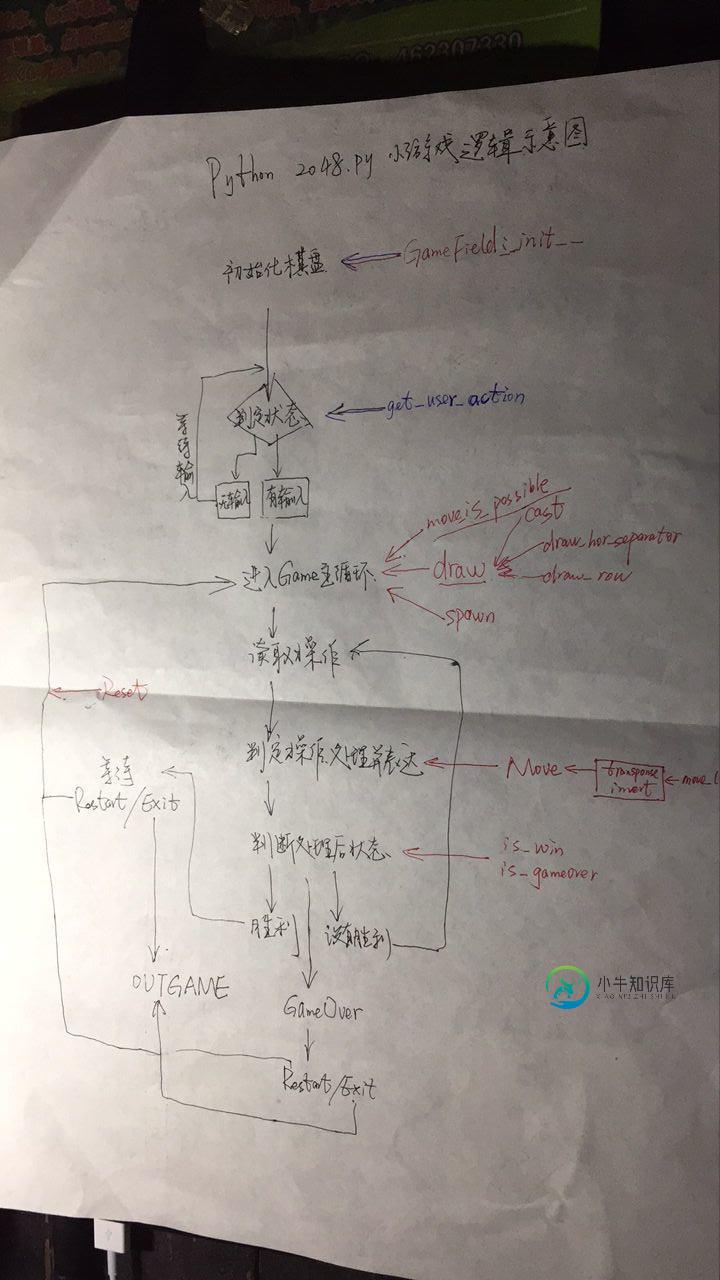 一步步教你用Python实现2048小游戏
一步步教你用Python实现2048小游戏本文向大家介绍一步步教你用Python实现2048小游戏,包括了一步步教你用Python实现2048小游戏的使用技巧和注意事项,需要的朋友参考一下 前言 2048游戏规则:简单的移动方向键让数字叠加,并且获得这些数字每次叠加后的得分,当出现2048这个数字时游戏胜利。同时每次移动方向键时,都会在这个4*4的方格矩阵的空白区域随机产生一个数字2或者4,如果方格被数字填满了,那么就GameOver了。
-
 JS小游戏之极速快跑源码详解
JS小游戏之极速快跑源码详解本文向大家介绍JS小游戏之极速快跑源码详解,包括了JS小游戏之极速快跑源码详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS小游戏的极速快跑源码,分享给大家供大家参考。具体如下: 游戏运行后如下图所示: Javascript部分代码如下: 完整实例代码点击此处本站下载。 相信本文所述对大家的javascript游戏设计有一定的借鉴价值。
-
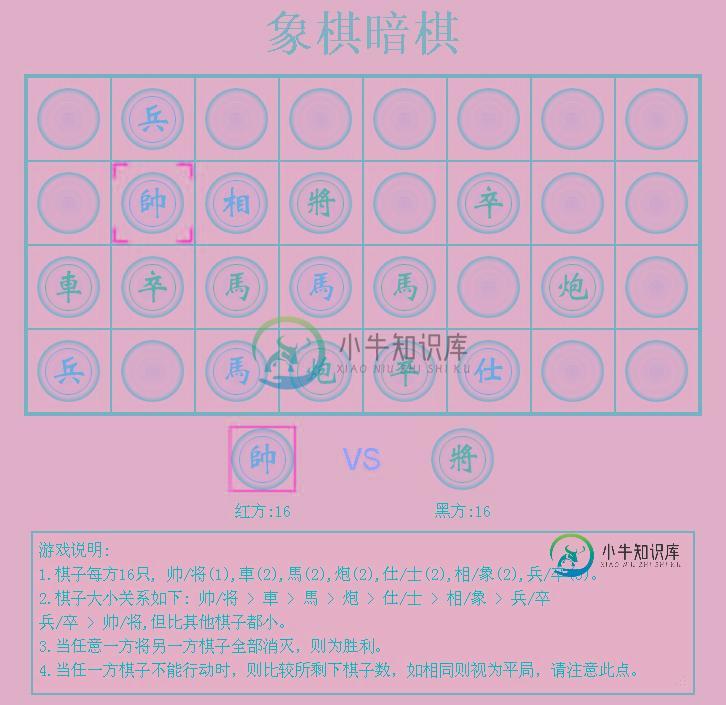 JS小游戏之象棋暗棋源码详解
JS小游戏之象棋暗棋源码详解本文向大家介绍JS小游戏之象棋暗棋源码详解,包括了JS小游戏之象棋暗棋源码详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS小游戏的象棋暗棋源码,分享给大家供大家参考。具体如下: 游戏运行后如下图所示: Javascript 部分: 完整实例代码点击此处本站下载。 相信本文所述对大家javascript游戏设计的学习有一定的借鉴价值。
-
 Android不规则图像填充颜色小游戏
Android不规则图像填充颜色小游戏本文向大家介绍Android不规则图像填充颜色小游戏,包括了Android不规则图像填充颜色小游戏的使用技巧和注意事项,需要的朋友参考一下 一、概述 近期群里偶然看到一哥们在群里聊不规则图像填充什么四联通、八联通什么的,就本身好学务实的态度去查阅了相关资料。对于这类着色的资料,最好的就是去搜索些相关app,根据我的观察呢,不规则图像填充在着色游戏里面应用居多,不过大致可以分为两种: 基于层的的填充
-
基于文本的游戏项目删除[重复]
在我的大学课程中,我们必须创建一个基于文本的游戏,在这个游戏中,你可以进出房间收集物品。我仍在尝试掌握python和一般编码的诀窍,因此我一直在努力完成这个项目。在大多数情况下,我的代码可以正常工作,但我可以多次添加一个项目。如何将其添加到库存中,然后从文件室中删除,以防止用户多次添加?
-
Python for loop打破了基于文本的游戏
我试图制作一个简单的基于文本的游戏,在这个游戏中,你在一个由“#”组成的网格周围移动“@”,并试图找到出口。我已经改变了代码,使我更容易使网格更大或更小,而无需添加或删除大量代码,它一直给我这样的输出: 我不知道这是怎么回事!只有一个“@”应该出现:(我只是python的新手,所以如果您有任何改进的建议,请不要犹豫,然后发布它们!提前感谢,
-
滑槽和梯子游戏随机放置问题
我是一名学生,正在做滑梯和梯子游戏。我正在使用一些方法来确定游戏板上应该放置多少滑槽和梯子。我在main中使用参数为每一个指定10,但我一直在获得6到11的位置。 这两种方法互相干扰是不是有什么问题? 或者我为随机放置设置for循环的方式有问题吗? 我是新来的这个网站,请让我知道,如果你需要更多的澄清,我不想把整个程序在这里。谢谢。
-
掷骰子游戏骰子掷在infinte循环中
我试图为一个游戏的掷骰子程序,其中用户输入一个下注金额和2个六面骰子滚动,如果7或11是滚动,他们赢了。如果掷2,3或12就输了,如果掷其他任何一个数字,它就显示该数字为一个点。它会继续掷骰子,直到掷7或该点为止,如果掷7就输了,否则就赢了。出于某种原因,在掷骰子时,他会掷骰子,然后再掷一次,看看他们是否赢了或输了。我不知道如何解决这个问题,任何帮助都不会附带
-
 Java实现的剪刀石头布游戏示例
Java实现的剪刀石头布游戏示例本文向大家介绍Java实现的剪刀石头布游戏示例,包括了Java实现的剪刀石头布游戏示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java实现的剪刀石头布游戏。分享给大家供大家参考,具体如下: ChoiceAnswer.java Game.java 运行结果: 更多关于java算法相关内容感兴趣的读者可查看本站专题:《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《
-
 C++基于EasyX图形库实现2048小游戏
C++基于EasyX图形库实现2048小游戏本文向大家介绍C++基于EasyX图形库实现2048小游戏,包括了C++基于EasyX图形库实现2048小游戏的使用技巧和注意事项,需要的朋友参考一下 C++ 和 EasyX 图形库,实现2048小游戏,供大家参考,具体内容如下 MainGame2048.cpp Game2048.h Game2048.cpp 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
python模拟点击玩游戏的实例讲解
本文向大家介绍python模拟点击玩游戏的实例讲解,包括了python模拟点击玩游戏的实例讲解的使用技巧和注意事项,需要的朋友参考一下 小编发现很多小伙伴都喜欢玩一些游戏,而手游因为玩的场景限制不多,所以受众的人更多。游戏里有很多重复的任务需要我们完成,虽然过程非常无聊,但是为了任务奖励还是有很多小伙伴不厌其烦的去做。那么,有没有什么方法,可以让我们从重复的操作中解放出来呢?今天小编就教大家用py