
Python数据集切分实例

在处理数据过程中经常要把数据集切分为训练集和测试集,因此记录一下切分代码。
''' data:数据集 test_ratio:测试机占比 如果data为numpy.numpy.ndarray直接使用此代码 如果data为pandas.DatFrame类型则 return data[train_indices],data[test_indices] 修改为 return data.iloc[train_indices],data.iloc[test_indices] ''' def split_train(data,test_ratio): shuffled_indices=np.random.permutation(len(data)) test_set_size=int(len(data)*test_ratio) test_indices =shuffled_indices[:test_set_size] train_indices=shuffled_indices[test_set_size:] return data[train_indices],data[test_indices]
测试代码如下:
import numpy as np import pandas as pd data=np.random.randint(100,size=[25,4]) print(data)
结果如下:

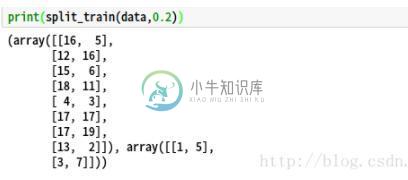
从上图可以看出,原数据集按照5:1被随机分为两部分。但是此种方法存在一个缺点–每次调用次函数切分同一个数据集切分出来的结果都不一样,因此常在np.random.permutation(len(data))先调用np.random.seed(int)函数,来确保每次切分来的结果相同。
因此将上述函数改为:
def split_train(data,test_ratio): np.random.seed(43) shuffled_indices=np.random.permutation(len(data)) test_set_size=int(len(data)*test_ratio) test_indices =shuffled_indices[:test_set_size] train_indices=shuffled_indices[test_set_size:] return data[train_indices],data[test_indices]
这个函数np.random.seed(43)当参数为同一整数时产生的随机数相同。
以上这篇Python数据集切分实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
参数: dataSet key -- string switchDataSet API可以切换地球表面呈现的数据集,该API只有通过addData API添加了一个data group之后才能生效。 // "large" 是一个数据集的"key" controller.switchDataSet("large");
-
在机器学习中,通常将所有的数据划分为三份:训练数据集、验证数据集和测试数据集。它们的功能分别为 训练数据集(train dataset):用来构建机器学习模型 验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数 测试数据集(test dataset):用来评估训练好的最终模型的性能 不断使用测试集和验证集会使其逐渐失去
-
本文向大家介绍利用python实现数据分析,包括了利用python实现数据分析的使用技巧和注意事项,需要的朋友参考一下 1:文件内容格式为json的数据如何解析 2:出现频率统计 3:重新加载module的方法py3 4:pylab中包含了哪些module from pylab import * 等效于下面的导入语句:
-
本文向大家介绍python集合用法实例分析,包括了python集合用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python集合用法。分享给大家供大家参考。具体分析如下: 希望本文所述对大家的Python程序设计有所帮助。
-
本文向大家介绍对python数据切割归并算法的实例讲解,包括了对python数据切割归并算法的实例讲解的使用技巧和注意事项,需要的朋友参考一下 当一个 .txt 文件的数据过于庞大,此时想要对数据进行排序就需要先将数据进行切割,然后通过归并排序,最终实现对整体数据的排序。要实现这个过程我们需要进行以下几步:获取总数据行数;根据行数按照自己的需要对数据进行切割;对每组数据进行排序 最后对所有数据进行
-
本文向大家介绍python 划分数据集为训练集和测试集的方法,包括了python 划分数据集为训练集和测试集的方法的使用技巧和注意事项,需要的朋友参考一下 sklearn的cross_validation包中含有将数据集按照一定的比例,随机划分为训练集和测试集的函数train_test_split 得到的x_train,y_train(x_test,y_test)的index对应的是x,y中被抽取