
Repast聚合数据集,但在Repast Simphony中分别针对每个实例

我正在使用Repast Simphony框架进行模拟。假设我有以下类:
public class Generator {
private String name;
private Random random;
public Generator(String name) {
this.name = name;
this.random = new Random();
}
public double getValue() {
return random.nextDouble();
}
}
然后我创建了这个类的几个实例,将它们添加到上下文中并运行模拟:
public class Builder implements ContextBuilder<Object> {
@Override
public Context build(Context<Object> context) {
context.add(new Generator("Gen1"));
context.add(new Generator("Gen2"));
context.add(new Generator("Gen3"));
return context;
}
}
是否有任何方法可以收集聚合数据,但对于类的每个实例分别?我想找出每个生成器的所有生成值的平均值,因此输出统计信息应采用以下格式:
Name,Mean
Gen1,0.458
Gen2,0.512
Gen3,0.463
如果我使用方法数据源Generator.getValue创建新的聚合(均值)数据集并重复每个刻度,我会得到大量的值列表:
Tick,Mean
1,0.365
2,0.456
3,0.728
4,0.091
...
其中每个值都是平均值,但所有生成器的指定刻度值的平均值,而不是一个生成器的所有刻度值的平均值。有没有什么方法可以用Repast Simphony做到这一点?
编辑:当我想使用自定义数据源时,添加类生成器实现AggregateDataSource和添加方法:
@Override
public String getId() {
return name;
}
@Override
public Class<?> getDataType() {
return Double.class;
}
@Override
public Class<?> getSourceType() {
return Generator.class;
}
@Override
public Object get(Iterable<?> objs, int size) {
return 7.0; // Not mean, only mock value for testing.
}
@Override
public void reset() {
// TODO Auto-generated method stub
}
出现错误:
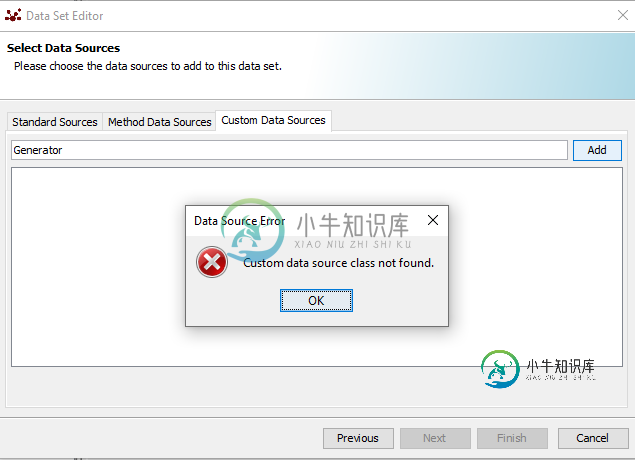
共有1个答案

我认为您可以通过定义自定义聚合数据源来做到这一点。您可以通过自定义数据源选项卡添加一个,提供一个实现Aggregate DataSource的类。
https://repast.github.io/docs/api/repast_simphony/repast/simphony/data2/AggregateDataSource.html
在get()方法中,遍历所有生成器对象并按名称获取平均值。每个生成器都需要AggregateDataSource实现。如果您使用一些静态变量,您可能可以对其进行编码,这样您只需要迭代一次,就可以得到该刻度的所有生成器的平均值。不过,在你让它工作之前,我会一直这样做。
更新:
您应该为CustomDataSource创建一个不同的类,以避免混淆。get中的iterable应该允许您迭代生成器的所有实例。此外,当您需要提供完全限定的名称(包名和类名)时,例如x.y.MyCustomDataSource
-
我试图在集合的子数组中对字段进行计数,我希望每个月都这样做。我曾在Mongo 2.6中使用过此功能,但最近升级到3.0.12导致查询中出现一些错误结果。这几个查询的总和似乎没有重置。 因此,目前我正在异步执行12个查询,并等待它们全部完成。这同样适用于2.6。我的表格结构如下: 这是我的代码: 因此,从本质上讲,第一个月包含的数据是正确的,但总和似乎继续包含前几个月的数据。如果我分解查询,则会在日
-
我有一个窗口化的每小时聚合的数据流。 Datastreamds=.....
-
我有以下方案的数据: 我想从这些数据中计算出几个聚合字段,并具有以下模式: 在RDD的快乐日子里,我可以使用,定义{ip-的映射 在Dataset/Dataframe聚合中不再可用,而是可以使用UDAF,不幸的是,从我使用UDAF的经验来看,它们是不可变的,这意味着它们不能使用(必须在每次映射更新时创建一个新实例)示例解释在这里 一方面,从技术上讲,我可以将数据集转换为RDD、聚合等,然后返回数据
-
我有一个java POJO 我有一个火花 我的数据集有一个值列表,但有重复的Ids。如何组合重复的帐户Ids并使用Spark group pBy将Key值对聚合到一个Map中。谢谢你的帮助。 所以我有: 我需要这个:
-
概述 MongoDB可以执行数据聚合,比如按指定Key分组,计算总数,求不同分组的值。 使用aggregate()方法执行一个基于步骤的聚合操作(类似于Linux管道)。aggregate()接收一个步骤数组成为它的参数,每个步骤描述对数据处理的操作。 db.collection.aggregate( [ <stage1>, <stage2>, ... ] ) 按字段分组并计算总数 使用$grou
-
问题内容: 我想过滤出字段“ A”等于“ a”的文档,并且我想同时考虑字段“ A”,当然不包括先前的过滤器。我知道您可以将过滤器“置于查询之外”,以便在不应用该过滤器的情况下获得构面,例如: elasticsearch 单反 这非常好,但是如果我有多个滤镜和构面,每个滤镜和构面应该互相排斥,会发生什么?例: 也就是说,对于方面AI,希望保留除A:a以外的所有过滤器,对于方面B希望保留除B:b以外的