《数据分析》专题
-
jqgrid中带有数组数据的分页问题
问题内容: 我在具有18条记录的数组数据的jqgrid中遇到分页问题,但是即使我指定了pagination:true,pager:jQuery(’#pager1’),记录也不会显示在页面中。您能帮我实现分页而不是滚动吗? 问题答案: 您的主要问题是添加大量行后应重置。线 在代码末尾将解决此问题。我建议您添加行 直接在定义jqGrid之后。然后,您不仅将具有数据分页,还具有数据过滤(搜索)和刷新
-
获取一个数据frame的当前分区数
是否有任何方法可以获得一个DataFrame的当前分区数?我检查了DataFrame javadoc(spark 1.6)但没有找到一个方法,或者我只是错过了它?(对于JavaRDD,有一个getNumPartitions()方法。)
-
分组数据框并获得总和和计数?
问题内容: 我有一个看起来像这样的数据框: 如何求和并计算,以得到一个看起来像这样的新数据框? 我知道如何求和 或 计数: 但不是两者都要做! 问题答案: 尝试这个: 或者如果您不想重置索引: 要么 演示:
-
转换后保留Spark数据帧的分区数
我正在查看代码中的一个错误,其中一个数据框被分成了太多的分区(超过700个),当我试图将它们重新分区为48个时,这会导致太多的洗牌操作。我不能在这里使用coalesce(),因为我想在重新分区之前首先拥有更少的分区。 我正在寻找减少分区数量的方法。假设我有一个 spark 数据帧(具有多个列),分为 10 个分区。我需要根据其中一列进行 orderBy 转换。完成此操作后,生成的数据帧是否具有相同
-
使用Pandas数据帧进行多参数分组
我有一个数据帧,我想按两个参数分组(1)相同的第一列中的连续编号和(2)第二列中的匹配值 数据帧: 组1包括前2行,因为30和31是连续的,第二列匹配。创建组2是因为Col1中的31和35不是连续的。创建组3是因为H和E不匹配。 在pandas groupby中对列表中的行进行分组 我很感谢你给我的建议
-
无分页计数的Spring数据存储库QueryDslPredicateExecutor
我试图创建一个spring数据存储库,它使用一个方法列出一页实体和一个QueryDSL谓词,使用以下内容: 正如这里提到的禁用从PageRequest获取总页数的计数查询的方法,我尝试使用“技巧”用“FindAllby”命名方法。 如何在不发出count查询的情况下使用Pageable创建QueryDSL存储库?在最后一页之后执行额外的查询以获取下一页,而不是对每个页面请求发出额外的计数查询,这样
-
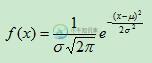 Python数据可视化正态分布简单分析及实现代码
Python数据可视化正态分布简单分析及实现代码本文向大家介绍Python数据可视化正态分布简单分析及实现代码,包括了Python数据可视化正态分布简单分析及实现代码的使用技巧和注意事项,需要的朋友参考一下 Python说来简单也简单,但是也不简单,尤其是再跟高数结合起来的时候。。。 正态分布(Normaldistribution),也称“常态分布”,又名高斯分布(Gaussiandistribution),最早由A.棣莫弗在求二项分布的渐近公
-
 (可内推)百词斩商业分析/数据分析实习生面经
(可内推)百词斩商业分析/数据分析实习生面经工作地点:成都市天府软件园 1.自我介绍:无实习经历/计算机相关专业2.面试问题(45min): -自我介绍 -你在竞赛中主要是负责leader还是执行者 -如果队员出现了矛盾你如何协调 -作为商业分析师,关注的数据指标 -估算双流机场每天航班数量 -估算全国大学生数量 -估算成都出租车数量 -销量下降会如何拆分 -x宝类电商软件最关心的数据指标 -SQL是自己学的还是学校教的,为什么自学 -如何
-
 美团探索分析产品组-数据产品(分析方向)面经
美团探索分析产品组-数据产品(分析方向)面经一面 2023.1.10 着重考察个人性格能力(自驱性、积极主动性、对成长的思考)、过往项目的参与深度 自我介绍 选一段实习经历,讲一下你的工作和角色 快手这段经历干了很久,为什么要离职 你说你在快手后期是主动思考的角色,讲一个例子证明一下 你觉得这些实习经历里,让你觉得有挑战,比较困难的事情或者时刻是什么 用一句话形容你自己 你下一段实习的目标是什么,希望获得什么 面试官介绍岗位对接的业务、工作
-
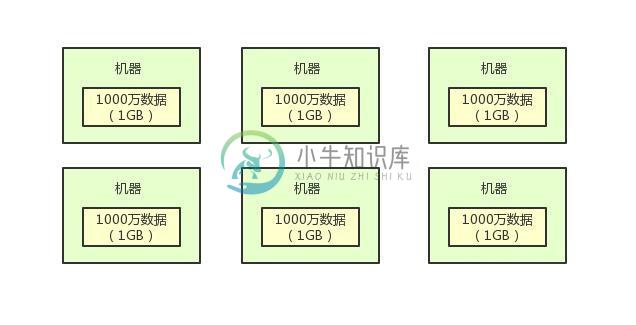 如何设计一个分布式系统去分析上亿条数据?
如何设计一个分布式系统去分析上亿条数据?主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
基于来自另一个数据帧的值将数据帧拆分为多个数据帧
我有两个数据帧df1和df2。df1就像一个具有以下值的字典 df2具有以下值: 我想基于df1数据帧中的,将df2拆分为3个新的数据帧。 日期,TLRA_权益栏应位于数据框 预期产出: > 数据帧 消费者,非周期性数据帧 请让我知道如何有效地做。我想做的是连接列名,例如,然后根据列名的前半部分分割数据帧。 代码: 但这很复杂。需要更好的解决方案。
-
将数据帧分解为新的子集/组数据帧。从其他数据框创建包含数据子集/组的新数据框
问题内容: 我有一个如下所示的pandas数据框,并通过一列保存数据组: 现在,我想创建新的数据框(名为df_w,df_x,df_y,df_z),这些数据框仅保存其原始数据中的数据,并在一些可迭代的列表(例如列表)中进行最佳组合: 有没有使用groupby,apply和/或applymap和函数来实现此目的的智能(矢量化熊猫)方法? 我当时正在考虑对数据框进行迭代,但这似乎不是很优雅。 预先感谢您
-
 Mysql数据库中数据表的优化、外键与三范式用法实例分析
Mysql数据库中数据表的优化、外键与三范式用法实例分析本文向大家介绍Mysql数据库中数据表的优化、外键与三范式用法实例分析,包括了Mysql数据库中数据表的优化、外键与三范式用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Mysql数据库中数据表的优化、外键与三范式用法。分享给大家供大家参考,具体如下: 数据表优化 将商品信息表进行优化 1.创建商品种类表: 2.将商品种类写入商品种类表中: 注意:插入另一个表的查询结果不需要加
-
熊猫在特定行将数据框拆分为两个数据框
问题内容: 我有从构成的DataFrame 。一行包含96个值,我想将DataFrame与值72分开。 以便将行的前72个值存储在Dataframe1中,并将行的后24个值存储在Dataframe2中。 我按如下方式创建我的DF: 问题是:如何拆分它们?:) 问题答案: (iloc文档)
-
ClassifierCompositeItemWriter在异常时回滚,但数据部分提交到数据库
我使用ClassifierCompositeItemWriter在一个固定长度的平面文件中插入不同类型的寄存器,并将其写入postgres数据库,其中有多个JDBCBatchItemWriter,每个都位于不同的表中,所有这些都在一个步骤中,然后坚持spring批处理作业,它工作正常,但在激活事务时,它们不会在异常情况下回滚。 例如,我有一个32行的平面文件,1行是页眉记录,然后我将其插入页眉表,