《中兴优招》专题
-
Git 与 TFS 的优势 [已关闭]
< b >想改进这个问题?通过编辑此帖子更新问题,使其只关注一个问题。 我注意到一个流行词“我们应该将Git用于TFS”。我的理解是,Git 只是 DVCS。 TFS 支持从分支、标记、合并、签入、签出、上架等所有内容。 有人可以帮助我了解团队应该在什么情况下使用Git或TFS吗? 除了本地存储库和分布式之外,它还能为团队提供什么好处? 它对分支和合并有更好的支持吗?据我所知,开发人员可以在他/她
-
广度优先搜索:有向图
我正在尝试在有向图上实现BFS。我完全确定我的算法是正确的,但是,下面的代码段返回错误: 图表。CPP文件: 以及在以下方面的实际BFS实施: 因此,除了源节点之外,队列中的其他节点都给出了错误的邻接列表。虽然队列顺序运行良好,但队列中的节点给出了错误的邻接。 我不确定为什么会发生这种情况,虽然我怀疑这是由于按值复制节点而不是引用。 这是我在很长一段时间后的CPP计划,所以如果我错过了什么,请启发
-
非递归深度优先搜索:
在这篇文章中,biziclop为非递归深度优先搜索算法插入了伪代码。 如果我们想使用递归DFS算法来检查节点的适当性,我们可以利用两个变体:pre-order(当一个节点在其子节点之前检查时)和post-order(当子节点在节点之前检查时),加上仅针对二叉树的第三个变体(顺序:左子树,然后节点,然后右子树)。 如果可能的话,我对这三个变体都很感兴趣,所以我试图修改biziclop的伪代码,以便获
-
Python是否优化尾部递归?
我有以下代码失败,错误如下: RuntimeError:超出最大递归深度 我试图重写它以允许尾部递归优化(TCO)。我相信,如果发生了TCO,那么这段代码应该是成功的。 我应该得出结论,Python不做任何类型的TCO,还是我只需要以不同的方式定义它?
-
使用AI技术优化参数
我知道我的问题很笼统,但我对人工智能领域还不熟悉。我用一些参数做了一个实验(几乎6个参数)。每一个都是独立的,我想找到输出函数最大或最小的最优解。然而,如果我想用传统的编程技术来实现,这将需要很多时间,因为我将使用六个嵌套循环。 我只是想知道用哪种人工智能技术来解决这个问题?遗传算法?神经网络?机器学习? 实际上,这个问题可能有不止一个评估函数。它将有一个功能,我们应该最小化它(成本)和另一个功能
-
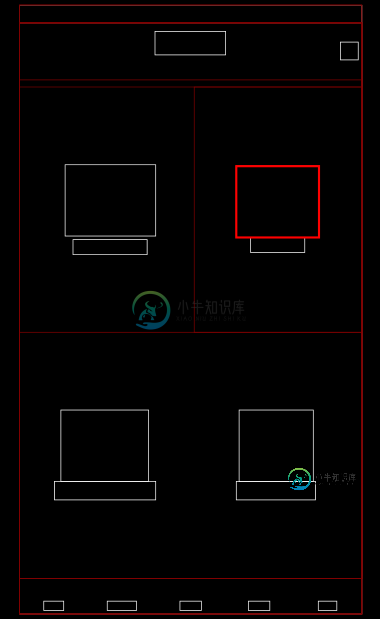 我如何优化这个布局?
我如何优化这个布局?我试图通过扁平化视图层次结构来优化Android应用程序中的布局。这里有一个特别难的问题! 此布局有一个主线布局,用于容纳顶行和底行(它们本身就是水平的子线布局)。中间的四个项目中的每一个都是使用LayOut权重来展开的垂直相对性(以适应图像视图和文本视图)。包含两个项目的每一行也是一个水平线性布局。 不用说,这种布局效率非常低,在绘制时会导致许多“编排者跳过了帧”的消息。我想删除这些嵌套的布局,
-
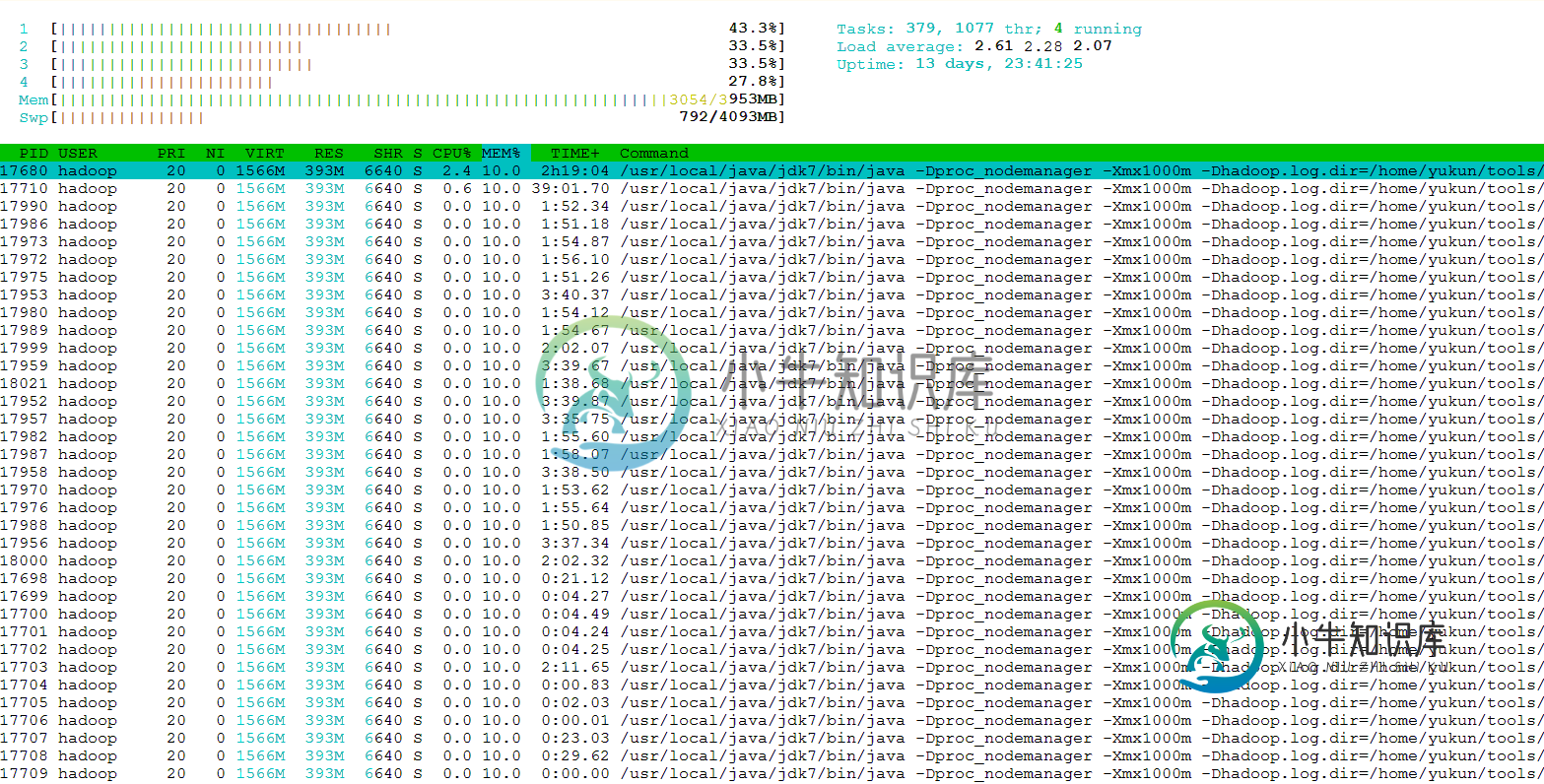 hadoop纱单节点性能调优
hadoop纱单节点性能调优我在我的Ubuntu VM上有hadoop 2.5.2单模式安装,它是:4核,每个核3GHz;4G内存。这个VM不是用于生产的,只用于演示和学习。 然后,我使用python编写了一个vey简单的map-reduce应用程序,并使用该应用程序处理49个XML。所有这些xml文件都很小,每个文件都有数百行。所以,我期待一个快速的过程。但是,big22令我惊讶的是,它花了20多分钟才完成这项工作(该工作
-
spring-boot 2优雅关机腹板
null 我正在尝试做一个优雅的关闭Rest应用程序和SCS(Kafka消费者和生产者)应用程序
-
如何查看gcc优化选项?
我试图找出关键的优化选项。首先,用 -Q-v列出了启用的标志(-faggressive loop optimizations-falign labels-fasynchronous unwind tables等)。然后,如果将这些标志直接提供给gcc而不是-O3,那么如果禁用了优化,则生成的程序的性能将降低。 gcc文件指出 并不是所有的优化都由一个标志直接控制 会是这个问题还是我错过了其他的?
-
不可见的GCC优化标志?
我正在使用GCC4.4.2构建一些大型项目。因为我想构建它以供发布,所以我使用了GCC优化标志,但不幸的是,它在某种程度上弄乱了我的代码,最终的二进制文件没有按照预期工作,当使用标志(或没有优化)构建时,一切都很好。我之前的项目也有类似的问题,当时是标志在优化级别上造成了问题,我通过搜索本文档中提到的所有标志,就优化级别而言,设法发现它是由该特定标志引起的: http://gcc.gnu.org/
-
构造函数重载的优点
-
Repast Simphony调度方法优先级
我有一个模型,大约有10种调度方法。现在我对控制它们的执行有点困惑。我希望这些调度方法按照一定的顺序执行。 我怎么能有ScheduleParameters。第一优先级,计划参数。第二优先级,调度参数。第三优先权。。。,和调度参数。最后一个优先事项。
-
大型表的MySQL查询优化
我有一个需要50秒的查询 security_tasks中的记录=841321 relations中的记录=234254 我能做些什么让它快一点,比如快1秒或2秒 有什么想法吗?
-
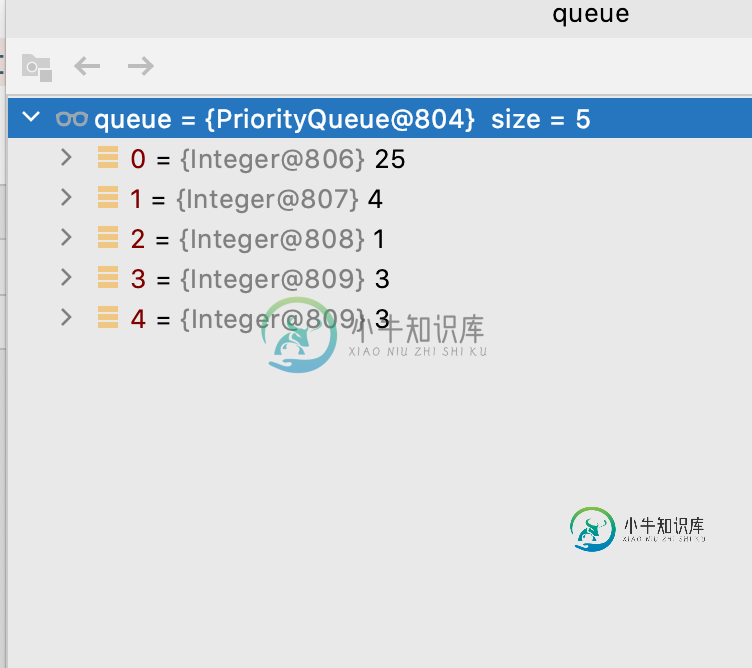 最大优先级队列函数
最大优先级队列函数我定义最大优先级队列如下: 我需要理解这是如何工作的,特别是当1只得到2的索引(而不是4)时? 多谢了。
-
如何优化列表操作?(CodeFights)
所以我有一个函数,在小列表上执行得很好。它的功能是检查从序列中删除一个元素是否会使该序列成为严格的递增序列: 但我需要它来处理长达10万个元素的列表。我可以做什么样的优化来更快地工作?现在,在10万个元素的列表中,它的速度非常慢,一秒钟要处理几千个元素。