《中兴优招》专题
-
什么是广度优先搜索?
本文向大家介绍什么是广度优先搜索?相关面试题,主要包含被问及什么是广度优先搜索?时的应答技巧和注意事项,需要的朋友参考一下 类似树的按层遍历,其过程为:首先访问初始点Vi,并将其标记为已访问过,接着访问Vi的所有未被访问过可到达的邻接点Vi1、Vi2……Vit,并均标记为已访问过,然后再按照Vi1、Vi2……Vit的次序,访问每一个顶点的所有未被访问过的邻接点,并均标记为已访问过,依此类推,直到图
-
7.16.深度优先搜索分析
深度优先搜索的一般运行时间如下。 dfs 中的循环都在 $$O(V)$$ 中运行,不计入dfsvisit 中发生的情况,因为它们对图中的每个顶点执行一次。 在dfsvisit 中,对当前顶点的邻接表中的每个边执行一次循环。 由于只有当顶点为白色时,dfsvisit 才被递归调用,所以循环对图中的每个边或 $$O(E)$$ 执行最多一次。 因此,深度优先搜索的总时间是 $$O(V + E)$$。
-
7.15.通用深度优先搜索
骑士之旅是深度优先搜索的特殊情况,其目的是创建最深的第一棵树,没有任何分支。更一般的深度优先搜索实际上更容易。它的目标是尽可能深的搜索,在图中连接尽可能多的节点,并在必要时创建分支。 甚至可能的是,深度优先搜索将创建多于一个树。当深度优先搜索算法创建一组树时,我们称之为深度优先森林。与广度优先搜索一样,我们的深度优先搜索使用前导链接来构造树。此外,深度优先搜索将在顶点类中使用两个附加的实例变量。新
-
7.10.广度优先搜索分析
在继续使用其他图算法之前,让我们分析广度优先搜索算法的运行时性能。首先要观察的是,对于图中的每个顶点 $$|V|$$ 最多执行一次 while 循环。因为一个顶点必须是白色,才能被检查和添加到队列。这给出了用于 while 循环的 $$O(V)$$。嵌套在 while 内部的 for 循环对于图中的每个边执行最多一次,$$|E|$$。原因是每个顶点最多被出列一次,并且仅当节点 u 出队时,我们才检
-
7.9.实现广度优先搜索
通过构建图,我们现在可以将注意力转向我们将使用的算法来找到字梯问题的最短解。我们将使用的图算法称为“宽度优先搜索”算法。宽度优先搜索(BFS)是用于搜索图的最简单的算法之一。它也作为几个其他重要的图算法的原型,我们将在以后研究。 给定图 G 和起始顶点 s,广度优先搜索通过探索图中的边以找到 G 中的所有顶点,其中存在从 s 开始的路径。通过广度优先搜索,它找到和 s 相距 k 的所有顶点,然后找
-
性能 & 优化 - 数据本地性
Spark 是一个并行数据处理框架,这意味着任务应该在离数据尽可能近的地方执行(既 最少的数据传输)。 检查本地性 检查任务是否在本地运行的最好方式是在 Spark UI 上查看 stage 信息,注意下面截图中的 "Locality Level" 列显示任务运行在哪个地方。 调整本地性配置 你可以调整 Spark 在每个数据本地性阶段(data local --> process local -
-
8 使用Python的优化模式
由于 PLY 从文档字串中获取信息,语法解析和词法分析信息必须通过正常模式下的 Python 解释器得到(不带 有-O 或者 -OO 选项)。不过,如果你像这样指定 optimize 模式: lex.lex(optimize=1) yacc.yacc(optimize=1) PLY 可以在下次执行,在 Python 的优化模式下执行。但你必须确保第一次执行是在 Python 的正常模式下进行,一旦
-
23.1 性能优化 平均负载
什么平均负载 简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。 所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断
-
第15章 优化应用结构
本文翻译自The Flask Mega-Tutorial Part XV: A Better Application Structure 这是Flask Mega-Tutorial系列的第十五部分,我将使用适用于大型应用的风格重构本应用。 Microblog已经是一个初具规模的应用了,所以我认为这是讨论Flask应用如何在持续增长中不会变得混乱和难以管理的好时机。 Flask是一个框架,旨在让你选
-
最优化算法 - 拟牛顿法
设f(x)是二次可微实函数,又设$x^{(k)}$是f(x)一个极小点的估计,我们把f(x)在$x^{(k)}$处展开成Taylor级数, 并取二阶近似。 上式中最后一项的中间部分表示f(x)在$x^{(k)}$处的Hesse矩阵。对上式求导并令其等于0,可以的到下式: 设Hesse矩阵可逆,由上式可以得到牛顿法的迭代公式如下 (1.1) 值得注意 , 当初始点远离极小点时,牛顿法
-
MySQL查询优化-内部查询
问题内容: 这就是整个查询… 如果… 和… 有明显的理由吗? 正在服用? 扩展说明 问题答案: 您可以始终使用EXPLAIN或EXPLAIN EXTENDED 来查看MySql对查询所做的操作 您也可以用稍微不同的方式编写查询,是否尝试过以下方法? 看看效果如何会很有趣。我希望它会更快,因为目前,我认为MySql将为您拥有的每个节目运行内部查询1(这样一个查询将运行多次。联接应该更有效。) 如果希
-
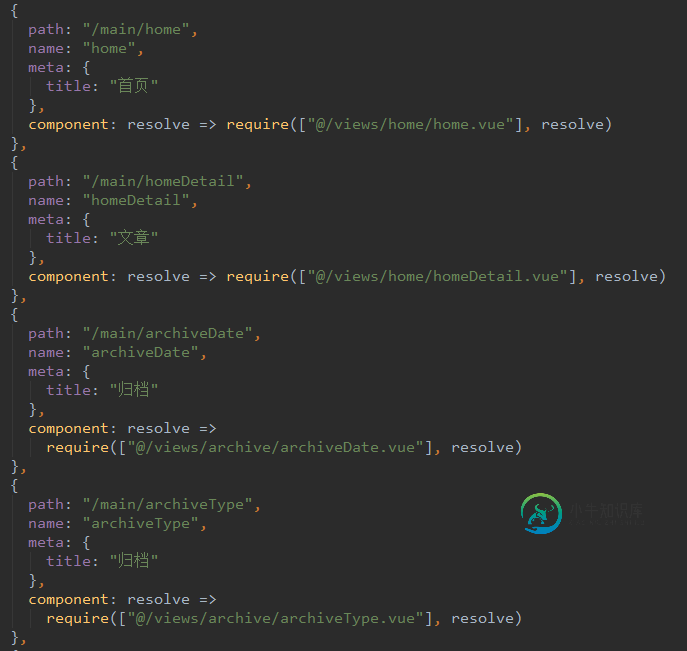 浅谈vue加载优化策略
浅谈vue加载优化策略本文向大家介绍浅谈vue加载优化策略,包括了浅谈vue加载优化策略的使用技巧和注意事项,需要的朋友参考一下 vue.js是一个比较流行的前端框架,与react.js、angular.js相比来说,vue.js入手曲线更加流畅,不管掌握多少都可以快速上手。但是单页面应用也都有其弊病,有时候首屏加载慢的让人捏舌。今天我们以vue cli3.x来说一说如何行之有效的缓解此问题! 方法一 路由懒加载 首屏
-
JavaScript6 let 新语法优势介绍
本文向大家介绍JavaScript6 let 新语法优势介绍,包括了JavaScript6 let 新语法优势介绍的使用技巧和注意事项,需要的朋友参考一下 最近看国外的前端代码时,发现ES6的新特性已经相当普及,尤其是 let,应用非常普遍 虽然 let 的用法与 var 相同,但不管是语法语义上,还是性能上,都提升了很多,下面就从这两方面对比一下 语法>> 这是一个常见的嵌套循环,都定义了变量
-
SQL Server:如何优化“赞”查询?
问题内容: 我有一个查询,使用带通配符的“ like”来搜索客户端。例如: 它还可以在“ where”子句中使用较少的参数,例如: 谁能说出优化这种查询性能的最佳方法是什么?也许我需要创建一个索引?该表在生产中最多可以有1000K条记录。 问题答案: 要在模式具有表单的位置上做很多事情,您需要查找SQL Server的全文本索引功能,并使用代替。照原样,您正在执行全表扫描,因为普通索引对搜索以通配
-
优化日期之间的陈述
问题内容: 我需要优化使用该子句和字段的PostgreSQL查询的帮助。 我有2张桌子: 包含约3394行 包含约4000000行 在PK和FK和上都有btree索引。 我想执行类似的查询: 该查询在大约7秒钟内检索到大约1.700.000行。 解释分析报告下报告: 未使用时间戳列上的索引。如何优化此查询? 问题答案: 查询将在不到一秒钟的时间内执行。其他6+秒用于服务器和客户端之间的流量。