《中兴优招》专题
-
说一下 JVM 调优的工具?
本文向大家介绍说一下 JVM 调优的工具?相关面试题,主要包含被问及说一下 JVM 调优的工具?时的应答技巧和注意事项,需要的朋友参考一下 JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。 jconsole:用于对 JVM 中的内存、线程和类等进行监控; jvisualvm:JDK 自带的全能分析工具,可
-
优化使用between子句的SQL
问题内容: 考虑以下两个表: 表A中的每条记录都精确映射到表B中的1条记录。这意味着表B没有重叠的时间段。表A中的许多记录可以映射到表B中的同一记录。 我需要一个返回所有A.id,B.id对的查询。就像是: 我正在使用MySQL,但无法优化此查询。表A中有约980条记录,表B中有130.000条记录,这是永远的事。我知道必须执行980个查询,但是在功能强大的计算机上花费超过15分钟的时间却很奇怪。
-
优化休眠序列ID生成
问题内容: 尝试将Hibernate与SAP HANA内存数据库连接时遇到一些性能问题,该数据库不支持AUTO_INCREMENT(http://scn.sap.com/thread/3238906)。 因此,我将Hibernate设置为使用序列进行ID生成。 但是,当我插入大量记录(例如40000)时,Hibernate首先会生成ID。看起来像: 并且只有在生成所有ID之后,它才开始实际插入。
-
SQLite 性能优化实例分享
本文向大家介绍SQLite 性能优化实例分享,包括了SQLite 性能优化实例分享的使用技巧和注意事项,需要的朋友参考一下 最早接触 iOS 开发了解到的第一个缓存数据库就是 SQLite,后面一直也以 SQLite 作为中坚力量使用,以前没有接触到比较大量数据的读写,所以在性能优化方面关注不多,这次对一个特定场景的较多数据批量读写做了一个性能优化,使性能提高了十倍。 大致应用场景是这样: 每次程
-
Java界面松耦合的优点?
有人能帮我吗,我读了一些Java紧耦合和松耦合的文章。我看了好几段YouTube视频和文章,对松散耦合有一定的怀疑,但仍然无法理解某些要点。我会解释我所理解的和让我困惑的。 在松散耦合中,我们限制类之间的直接耦合。但在紧密耦合中,我们注定要去上课。让我们举个例子。我有一个主类和另一个名为Apple的不同类。我在Main类中创建了这个类的一个实例 让我们看看松耦合 如果我将松散耦合中的方法签名从“喝
-
优化Postgres删除孤立记录
以以下两个表格为例: 和 主键和。 我需要删除任何没有相关的。大约有3MM和25MM记录。 我正在尝试以下两个问题: 正如您所看到的,即使不删除任何记录,两个查询都会在大约3分钟内显示类似的性能。 服务器磁盘I/O峰值达到100%,因此我假设数据正在溢出到磁盘,因为对和都进行了顺序扫描。 服务器是EC2r3.large(15GB RAM)。 我能做些什么来优化这个查询呢? 在为两个表运行并确保设置
-
通过反射打破JIT优化
在处理高度并发的单例类的单元测试时,我偶然发现了以下奇怪的行为(在JDK 1.8.0\U 162上测试): main()方法的最后两行在INSTANCE的值上不一致-我猜JIT完全摆脱了该方法,因为该字段是静态final。删除final关键字可以使代码输出正确的值。 撇开你对单例的同情(或缺乏同情)不谈,暂时忘记像这样使用反射是在自找麻烦——我的假设是正确的吗?JIT优化是罪魁祸首?如果是这样的话
-
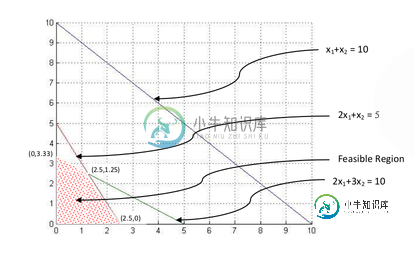 优化:种植小麦和水稻
优化:种植小麦和水稻这是问题陈述 一位印度农民有一片农田,比如说1平方公里长,他想种小麦或水稻,或者两者兼有。农民有有限的F公斤肥料和P公斤杀虫剂。 每平方公里的小麦需要F1公斤化肥和P1公斤杀虫剂。每平方公里的水稻种植需要F2公斤化肥和P2公斤杀虫剂。假设S1是出售从一平方公里收获的小麦获得的价格,S2是出售从一平方公里收获的水稻获得的价格。 你必须通过选择种植小麦和/或水稻的地区来找到农民可以获得的最大总利润。
-
是否允许此浮点优化?
我试图检查在哪里失去了准确表示大整数的能力。所以我写了这个小片段: 这段代码似乎适用于所有编译器,除了clang。Clang生成一个简单的无限循环。戈德博尔特。 这是允许的吗?如果是,这是QoI问题吗?
-
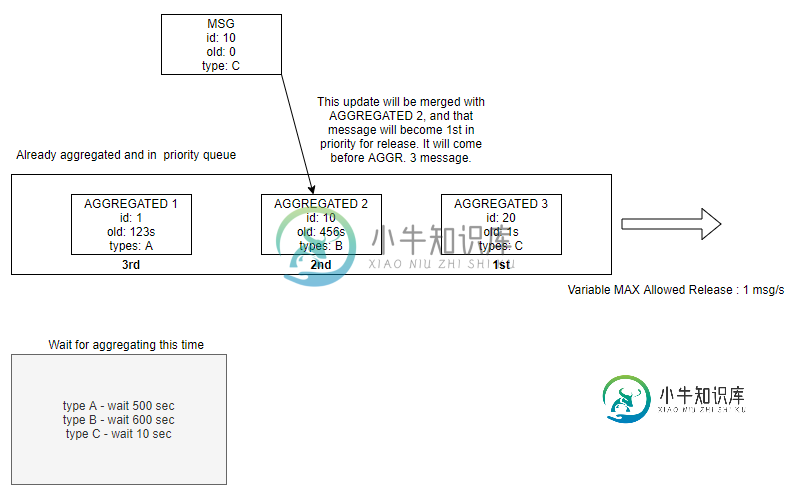 Spring集成-优先级聚合器
Spring集成-优先级聚合器我有以下应用程序要求: 从RabbitMq接收消息,然后根据一些更复杂的规则进行聚合,例如基于属性(具有预先给定的类型时间映射)和基于消息在队列中等待的现有时间(属性) 正如您在图中看到的一个用例:三条消息已经聚合并等待下一秒发布(因为当前速率为),但就在那时,以到达,并更新了,使其成为优先级最高的第一条消息。因此,在下一个选项中,我们不再发布聚合3,而是发布聚合2,因为它现在具有更高的优先级。
-
Java优先级队列比较器
假设我实现了一个HashMap,其中字符被分配了一个值的ArrayList。 我已经在HashMap中创建了这些字符的PriorityQueue,但我希望能够根据此优先级删除这些字符: {a,b,c} {a,b}删除c,因为它的ArrayList中包含一个值,该值决定必须首先删除它。 对此最好的方法是什么?
-
哪个优先:logback.xml还是logback-test.xml?
我是一个很新的登录。如果我的Spring启动项目包含这两个文件- :位于*src/main/resources/下 :位于*src/test/resources/下 哪一个装货?还是?
-
氢汽车加油模型优化
我目前正在尝试确定使用GEKKO的氢气(H2)车辆加油过程的最佳流入条件。下面是耦合的常微分方程,用于控制H2和燃油箱壁的温度如何随加油时间变化。 哪里 这里,是储罐中H2的初始质量,是H2进入储罐的质量流量,是H2的比热比,是H2的流入温度,其他变量是中间变量/储罐参数。通过加油过程,被认为是恒定的(但未知),因此储罐中H2随时间的质量定义为: 此外,罐内H2的压力可以用真实的气体状态方程来计算
-
Dijkstra算法的优先级队列
我正在为Dikjstra算法做一个优先级队列。我目前在插入方法上有麻烦。我包含了整个类的代码,以防你需要更好地了解我想完成的事情。我将堆索引放在一个数组列表(heapIndex)中,堆放在另一个数组列表中。 那是我运行程序后的输出(值,优先级,堆索引)。*(-1)表示heapIndex中的空单元格。
-
可以跳过Stream.peek()进行优化
我在声纳中发现了一条规则,它说: 与其他中间流操作的一个关键区别是,为了优化目的,流实现可以跳过对< code>peek()的调用。这可能会导致< code>peek()仅针对流中的某些元素或不针对流中的任何元素被意外调用。 另外,Javadoc中提到了它,它说: 此方法主要用于支持调试,您希望在元素流经管道中的某个点时看到这些元素 这种情况下可以跳过吗?和调试有关吗?