
Spring集成-优先级聚合器

我有以下应用程序要求:
- 从RabbitMq接收消息,然后根据一些更复杂的规则进行聚合,例如基于
类型属性(具有预先给定的类型时间映射)和基于消息在队列中等待的现有时间(旧属性)
正如您在图中看到的一个用例:三条消息已经聚合并等待下一秒发布(因为当前速率为1msg/sec),但就在那时,MSG以id:10到达,并更新了aggregated 2,使其成为优先级最高的第一条消息。因此,在下一个选项中,我们不再发布聚合3,而是发布聚合2,因为它现在具有更高的优先级。
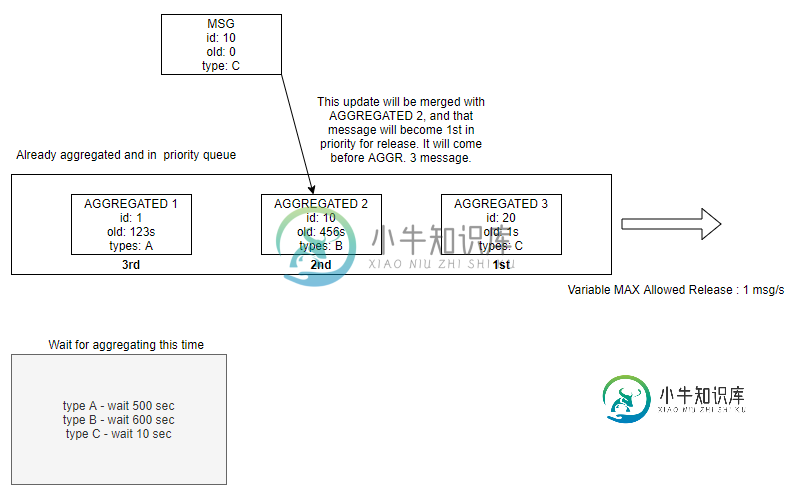
现在,问题是-我可以为此使用Spring集成聚合器吗,因为我不知道它是否支持聚合期间消息的优先级?我知道group pTimeout,但那只是调整单个消息组-不改变其他组的优先级。是否有可能使用MessageGroupStorepper在新MSG到达时按优先级调整所有其他聚合消息?
使现代化
我做了一些这样的实现——目前看来还可以——它在消息到达时聚合消息,而comparator则根据我的自定义逻辑对消息进行排序。
2021-01-18 13:52:05.277 INFO 16080 --- [ scheduling-1] ggregatorConfig$PriorityAggregatingQueue : POLL
2021-01-18 13:52:05.277 INFO 16080 --- [ scheduling-1] ggregatorConfig$PriorityAggregatingQueue : POLL
2021-01-18 13:52:05.277 INFO 16080 --- [ scheduling-1] ggregatorConfig$PriorityAggregatingQueue : POLL
2021-01-18 13:52:05.277 INFO 16080 --- [ scheduling-1] ggregatorConfig$PriorityAggregatingQueue : POLL
另外,这个有注释的doit方法是增加运行时轮询消息最大数量的正确方法吗?
@Bean
public MessageChannel aggregatingChannel(){
return new QueueChannel(new PriorityAggregatingQueue<>((m1, m2) -> {//aggr here},
Comparator.comparingInt(x -> x),
(m) -> {
ExampleDTO d = (ExampleDTO) m.getPayload();
return d.getId();
}
));
}
class PriorityAggregatingQueue<K> extends AbstractQueue<Message<?>> {
private final Log logger = LogFactory.getLog(getClass());
private final BiFunction<Message<?>, Message<?>, Message<?>> accumulator;
private final Function<Message<?>, K> keyExtractor;
private final NavigableMap<K, Message<?>> keyToAggregatedMessage;
public PriorityAggregatingQueue(BiFunction<Message<?>, Message<?>, Message<?>> accumulator,
Comparator<? super K> comparator,
Function<Message<?>, K> keyExtractor) {
this.accumulator = accumulator;
this.keyExtractor = keyExtractor;
keyToAggregatedMessage = new ConcurrentSkipListMap<>(comparator);
}
@Override
public Iterator<Message<?>> iterator() {
return keyToAggregatedMessage.values().iterator();
}
@Override
public int size() {
return keyToAggregatedMessage.size();
}
@Override
public boolean offer(Message<?> m) {
logger.info("OFFER");
return keyToAggregatedMessage.compute(keyExtractor.apply(m), (k,old) -> accumulator.apply(old, m)) != null;
}
@Override
public Message<?> poll() {
logger.info("POLL");
Map.Entry<K, Message<?>> m = keyToAggregatedMessage.pollLastEntry();
return m != null ? m.getValue() : null;
}
@Override
public Message<?> peek() {
Map.Entry<K, Message<?>> m = keyToAggregatedMessage.lastEntry();
return m!= null ? m.getValue() : null;
}
}
// @Scheduled(fixedDelay = 10*1000)
// public void doit(){
// System.out.println("INCREASE POLL");
// pollerMetadata().setMaxMessagesPerPoll(pollerMetadata().getMaxMessagesPerPoll() * 2);
// }
@Bean(name = PollerMetadata.DEFAULT_POLLER)
public PollerMetadata pollerMetadata(){
PollerMetadata metadata = new PollerMetadata();
metadata.setTrigger(new DynamicPeriodicTrigger(Duration.ofSeconds(30)));
metadata.setMaxMessagesPerPoll(1);
return metadata;
}
@Bean
public IntegrationFlow aggregatingFlow(
AmqpInboundChannelAdapter aggregatorInboundChannel,
AmqpOutboundEndpoint aggregatorOutboundChannel,
MessageChannel wtChannel,
MessageChannel aggregatingChannel,
PollerMetadata pollerMetadata
) {
return IntegrationFlows.from(aggregatorInboundChannel)
.wireTap(wtChannel)
.channel(aggregatingChannel)
.handle(aggregatorOutboundChannel)
.get();
}
共有1个答案

好的,如果有一条新的消息要组完成,它会到达聚合器,那么这样的组会立即被释放(如果您的ReleaseStrategy这样说的话)。处于超时状态的组的其余部分将继续等待计划。
可能会提出一种智能算法,利用MessageGroupStoreReaper依赖一个通用的时间表来决定我们是需要释放该部分组还是放弃它。再次强调:ReleaseStrategy应该给我们一个发布或不发布的线索,即使是部分发布。当丢弃发生时,我们希望将这些消息保留在聚合器中,我们需要在延迟一段时间后将它们重新发送回聚合器。过期后,组将从存储中删除,这发生在我们已经发送到丢弃通道时,因此最好延迟这些组并让聚合器清理这些组,这样在延迟后,我们可以安全地将它们作为新组的一部分发送回聚合器,以达到新的过期期。
您可能还可以在发布正常组后迭代存储区中的所有消息,以调整其标题中的某个时间键,以供下一个过期时间使用。
我知道这很难,但实际上没有现成的解决方案,因为它不是为了影响我们刚刚处理过的其他群体而设计的。。。
-
我想使用聚合器从两条消息中创建一条消息,但我不知道如何做到这一点。 目前,我正在从一个目录中读取两个文件,并希望将这些消息聚合为一个。 我的整个项目是这样的: 读入。拉链- 如果我可以在解压缩文件后发送一条包含两个有效负载的消息,那就太好了,但在读取后聚合就足够了。 我的拉链看起来像这样: 它将这些文件放入两个目录中,我使用FileReadingMessageSource再次从中读取它们。我还想只
-
问题内容: 像这样的组合器优先吗? (注之间的空间,并为后代组合子) 还是从左到右阅读,就像 ? 问题答案: 不,在组合器中没有优先级的概念。但是,在复杂的选择器中存在元素顺序的概念。 可以从对您有意义的任何方向读取任何复杂的选择器,但这并不意味着组合器是分布式的或可交换的,因为它们表示两个元素(例如和)之间的关系。这就是为什么元素顺序很重要的原因。 但是,根据Google的说法,浏览器实现了其选
-
在我的用例中,最简单的集成组件安排是什么: 接收来自多个来源和多种格式的消息(所有消息都是JSON序列化对象)。 将消息存储在缓冲区中最多10秒(聚合) 通过不同的类属性getter(例如class1.someId(),class2.otherId(),...) 释放所有分组的消息并转换为新的聚合消息。 到目前为止(第1点和第2点),我正在使用聚合器,但不知道3)处的问题是否有现成的解决方案或者我
-
目前,我正在与spring integration合作开发新的应用程序,并启动了poc,以了解如何处理故障案例。在我的应用程序中,spring integration将接收来自IBM mq的消息,并根据消息类型验证头信息和到不同队列的路由。传入的消息可能是批量消息,所以我使用了spring integration的拆分器和聚合器,并且对技术工作流程有很好的进展和控制。目前我面临的问题很少,我们有I
-
我正在做一个新的项目,第一次使用Spring-Boot。 传统上,在使用Spring和属性文件进行配置时,我在发行版(WAR)中提供了默认属性,并允许在某个文档位置重写它们。 例如: 这将允许我们在不丢失本地系统配置的情况下重新部署应用程序。 我喜欢Spring,因为它允许我们遵守惯例,这让我担心我可能做错了属性级联。 什么是提供包含在发行版中的外部化属性的最合适的方法,该属性具有合理的默认值(嵌
-
问题内容: 我的网页包含: 引用的样式表包含: 我在ID中有一张表格,希望单元格有一些填充。但是,引用的样式表优先于内联样式。我可以通过Firebug直观地看到这一点。如果我关闭Firebug中的指令,则向左填充将生效。 我该如何上班? 问题答案: 正如其他人提到的那样,您有一个特异性问题。当确定两个规则中的哪一个优先时,CSS引擎会计算每个选择器中的s 数量。如果一个比另一个多,就使用它。否则,