
hadoop纱单节点性能调优

我在我的Ubuntu VM上有hadoop 2.5.2单模式安装,它是:4核,每个核3GHz;4G内存。这个VM不是用于生产的,只用于演示和学习。
然后,我使用python编写了一个vey简单的map-reduce应用程序,并使用该应用程序处理49个XML。所有这些xmlhtml" target="_blank">文件都很小,每个文件都有数百行。所以,我期待一个快速的过程。但是,big22令我惊讶的是,它花了20多分钟才完成这项工作(该工作的输出是正确的。)。以下是输出指标:
作为hadoop的新手,对于这种疯狂的不合理表现,我有几个疑问:
-
null
实际上,我在谷歌上搜索过这个问题,我得到了一堆名字,比如Ganglia/Nagios/Vaidya/Ambari。我想知道,哪种工具最能分析“为什么做这么简单的工作要花20分钟?”这样的问题。
即使没有作业在我的hadoop上运行,我也在我的VM上找到了大约100个hadoop进程,如下所示(我使用htop,并按内存对结果进行排序)。这对hadoop正常吗?还是我对某些环境配置不正确?
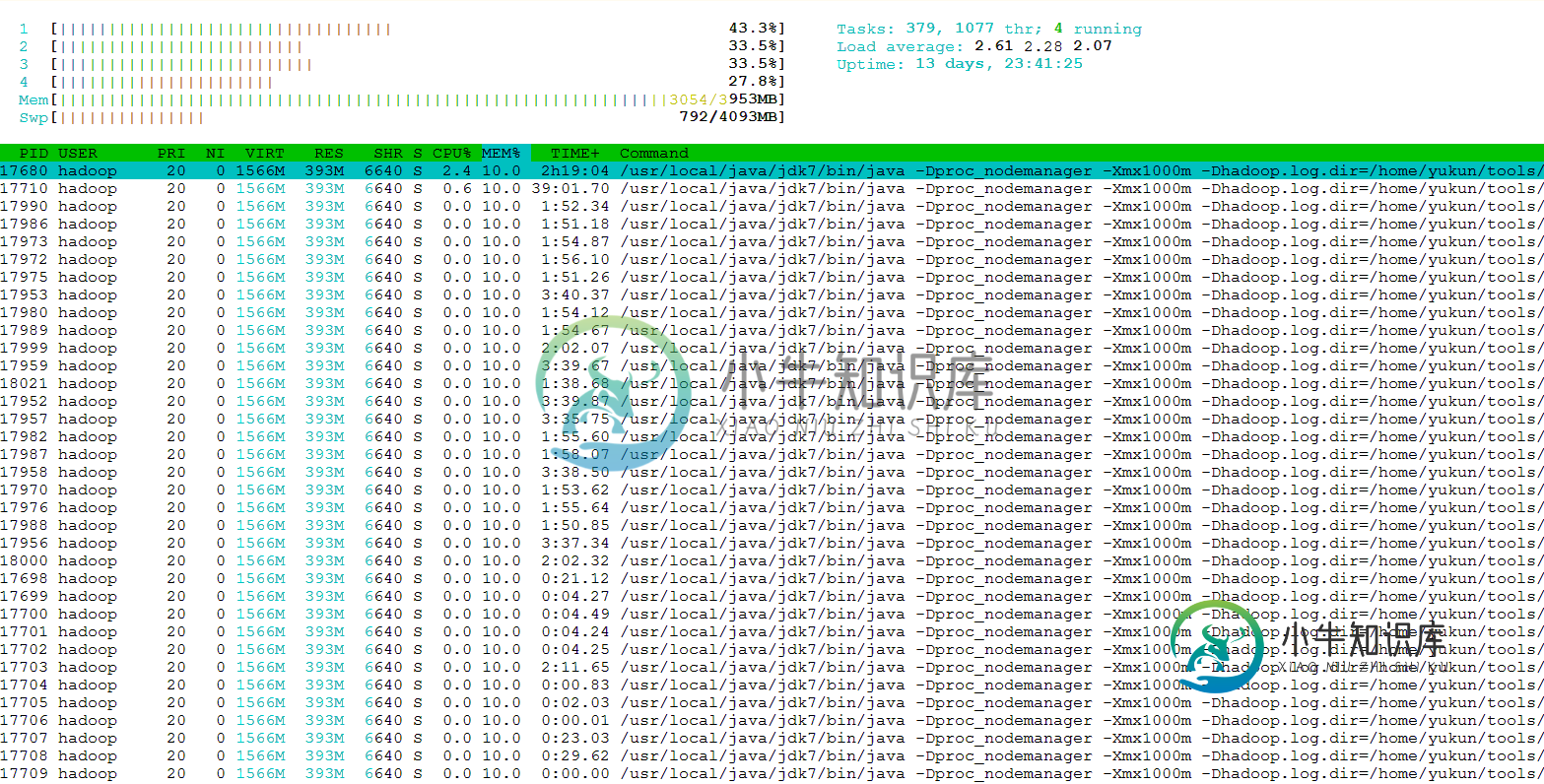
共有1个答案

- 您不必更改任何内容。
默认配置是针对小型环境进行的。你可以改变它,如果你成长的环境。Ant有很多参数和很多时间进行微调。
但我承认你的配置比通常的测试配置要小。
-
null
- 更改nodemanager的可用内存(改为3Gio,以便为系统设置1 Gio)
- 更改hadoop服务可用的内存(hadoop-env.sh,yarn-env.sh中的-xmx)(系统+每个hadoop服务(namenode/datanode/ressourcemanager/nodemanager)<1 gio。
- 更改映射任务的内存(512 Mio?)。它越小,就可以在同一时间内执行更多任务。
- 将yarn.scheduler.minimum-allocation-MB更改为yar-site.xml中的512,以允许内存少于1 Gio的映射器。
我希望这能对你有所帮助。
-
本文向大家介绍Hadoop性能调优?相关面试题,主要包含被问及Hadoop性能调优?时的应答技巧和注意事项,需要的朋友参考一下 调优可以通过系统配置、程序编写和作业调度算法来进行。 hdfs的block.size可以调到128/256(网络很好的情况下,默认为64) 调优的大头:mapred.map.tasks、mapred.reduce.tasks设置mr任务数(默认都是1) mapred.ta
-
前面说过, 一台普通计算机的TPS 理论上限约为7千TPS。 如果要让整个系统的TPS更高,一种方式是使用高性能的计算机,另一种就是将单计算机处理改为多计算机处理。 本系统使用多链方式,链与链可以并行处理,所以可以将不同的链的处理放到不同的计算机上,实现并行处理,避免单节点的硬件、网络等瓶颈。 这样就能够做到系统性能根据链的增加而线性增长。 如果某个节点性能不足,可以新增一个计算机,将部分链的处理
-
我有几个关于向HDFS提交作业和Hadoop中的YARN架构的问题: 所以我的问题是在HDFS中纱线的组成部分是如何协同工作的:? 因此,YARN由NodeManager和Resource Manager组成。在这两个组件中:NodeManager是否运行在每个DataNode上,而ResourceManager是否运行在每个集群的每个NameNode上?因此,当任务跟踪器(在每个DataNode
-
需要一些帮助。虽然有很多不同的答案可用,我也尝试了他们,但不能使它工作。我在mac os中本地插入了hadoop,当我尝试编译java程序时,我得到了以下错误。我知道问题出在设置正确的类路径上,但在五月的情况下,提供类路径并没有使其工作。我已经在/usr/local/cellar/hadoop/1.2.1/libexec下安装了hadoop lineindexer.java:6:包org.apac
-
这些是我机器里的端口。tcp 0 0 0.0.0.0:8088 0.0.0.0:*侦听1001 50434 5765/Java tcp 0 0 0.0.0.0:*侦听1001 45587 5461/Java tcp 0 0 0.0.0.0:*侦听1001 45594 5461/Java tcp 0 0 0.0.0.0:*侦听1001 47365 5765/Java tcp 0 0 0.0.0.0:
-
有人能帮我了解以下情况吗?我有1个工人配置如下: 如果我将“最大当前工作流任务可执行文件大小”和“最大当前活动可执行文件大小”设置为 1024,则工作线程开始工作太慢。我认为增加这两个选项将有助于处理更多的活动和工作流任务,但它的工作方式不同。工作线程具有足够的 CPU/RAM,并且他根本没有过载。 从临时UI中,我能够捕捉到一些工作流在这样的历史状态下冻结了一段时间: 我还调整了这样的匹配参数: