《平安》专题
-
我如何平均ArrayList中的内容?
-
如何在windows平台上使用Tarantool
我是新来Tarantool的。我想通过ODBC驱动程序在第三方应用程序如Tableau、Power BI中连接Tarantool数据库。 请回答我下面的问题。 1)我想在Windows 10平台上运行Tarantool数据库服务器。有没有可能安装Tarantool在windows平台?如果是,请提供步骤并提供链接,在那里我可以下载Windows的Tarantool,以及如何进一步创建数据库。 2)
-
Azure中的Applicatoin_Start、Init和水平缩放
在Azure中关于水平缩放的术语有点不清楚。 我们有一个“缓存刷新”特性,涉及到设置一个侦听器来订阅消息队列中的“主题”,这样它就会在接收到消息时刷新静态缓存。我们以前认为必须在HttpApplication.init事件中设置侦听器,每个实例都会调用该事件,但在意识到AppDomain中的所有HttpApplication实例都共享同一组静态变量之后,这就不再有意义了。 我的新理解是,即使在没有
-
负载平衡器后面的SpringOAuth2 SSO
我有一个非常简单的Spring Boot应用程序,具有社交单点登录功能。 看起来是这样的: 它在应用程序中有必需的条目。yml: 它在我的本地机器上运行得很好,并且只启动了一个实例。 当有多个实例隐藏在负载平衡器后面时,就会出现问题。 即使用户在第一个请求中进行身份验证,向负载均衡器发出的后续请求也会因401而被阻止。 与第一个应用程序实例相比,请求被路由到不同的应用程序实例。 我正在试图弄清楚,
-
OpenShift平台中使用MySql的Spring Webapp
我最近刚从EC2迁移到OpenShift,因为OpenShift有一些应用程序,只需点击一下就可以很快安装(他们称之为cartridges),但我现在使用这个MySql Cartridge有一个问题。 我的spring webapp部署在OpenShift中,硬编码mysql服务器的数据库URL、用户名和密码都不工作。大多数论坛建议使用环境变量来指向数据库url、用户、密码,但仍然不起作用。但我关
-
Java:平面列表到层次列表
这个问题似乎相当复杂,所以我在这里发布这个问题,寻找任何可能的解决方法。 我有地图清单。我想要一个地图列表,但要确保地图被转换成某种层次结构。 原始数据:(列表 此地图列表将转换为以下地图列表:(列表) 作为一个简单的解决方案,我试图手动处理它们(真的很无聊),所以我在寻找使用流或任何其他可能的方式来处理它们的任何高效、干净的方法。 更新朴素的解决方案如下
-
Spring靴平地机多模块应用
如有任何帮助,不胜感激。 更新 移除后 我正在犯错误
-
如何使用流平均大小数?
我想采取以下方法: 并使用Streams api更新它。这是我到目前为止得到的: 有没有办法在不流式传输两次(第二次获得计数)的情况下做到这一点?
-
使非逻辑平面结构分层
我想按标题分组,但当结构不符合逻辑时,分区就会停止。例如 输入: 输出 期望输出 样式表
-
 带igraph或ggnet2的水平树形图
带igraph或ggnet2的水平树形图我正在尝试使用 和 从维基百科中重现如下所示的概率树图。以下是我的开始, 它随机放置节点,以数字方式标记它们,并且边缘没有标签: 相反,我需要重新组织并标记边和节点,就像这样,只是将节点标签放在圆圈内:
-
无法移除Cordova中的Android平台
不确定原因,但我检查它是否至少被识别为已删除,但它没有: $科尔多瓦平台 安装的平台: android
-
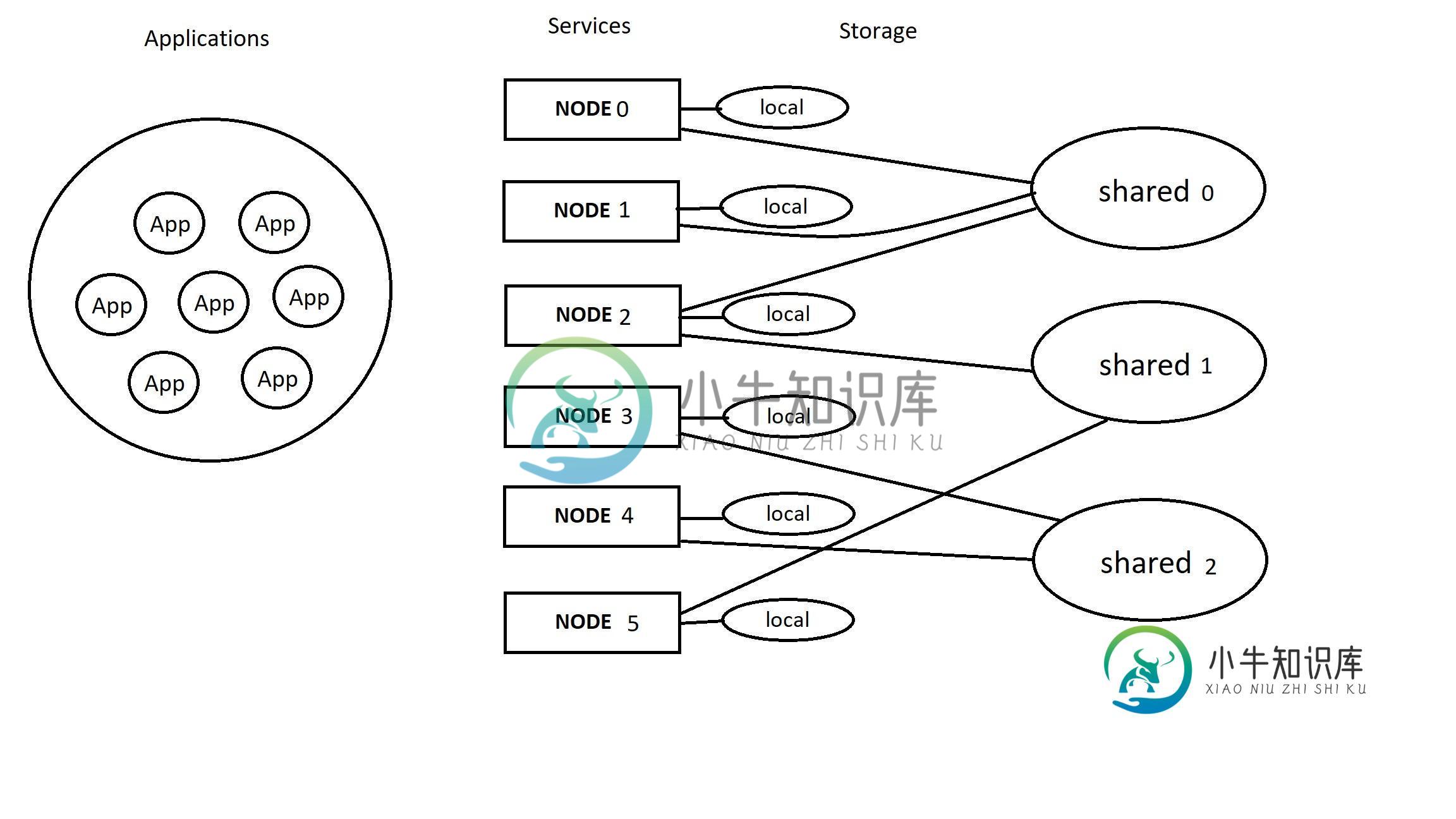 具有限制的再平衡算法
具有限制的再平衡算法请帮助解决以下问题。 给出了以下实体: < li >应用。应用程序驻留在存储上,它们通过服务节点产生流量。 < li >服务。服务分为几个节点。每个节点都可以访问本地或/和共享存储。 < li >存储。这是应用程序驻留的地方。它可以是本地的(仅连接到一个服务节点),也可以由几个节点共享。 规则: 每个应用程序都放置在某个特定的存储上。并且不能改变存储 只要新的服务节点可以访问应用程序的存储,应用程
-
MongoDB分片集合未重新平衡
我们有一个相对简单的分片MongoDB设置:4个分片,每个分片是一个副本集,至少有3个成员。每个集合都由从大量文件加载的数据组成;每个文件都被赋予一个单调递增的ID,并且根据ID的哈希完成分片。 我们的大部分产品都在按预期工作。然而,我有一个集合似乎没有正确地将块分布到各个碎片上。在创建索引之前,集合加载了大约30GB的数据,并且进行了分片,但是据我所知,这并不重要。以下是该集合的统计数据: 这个
-
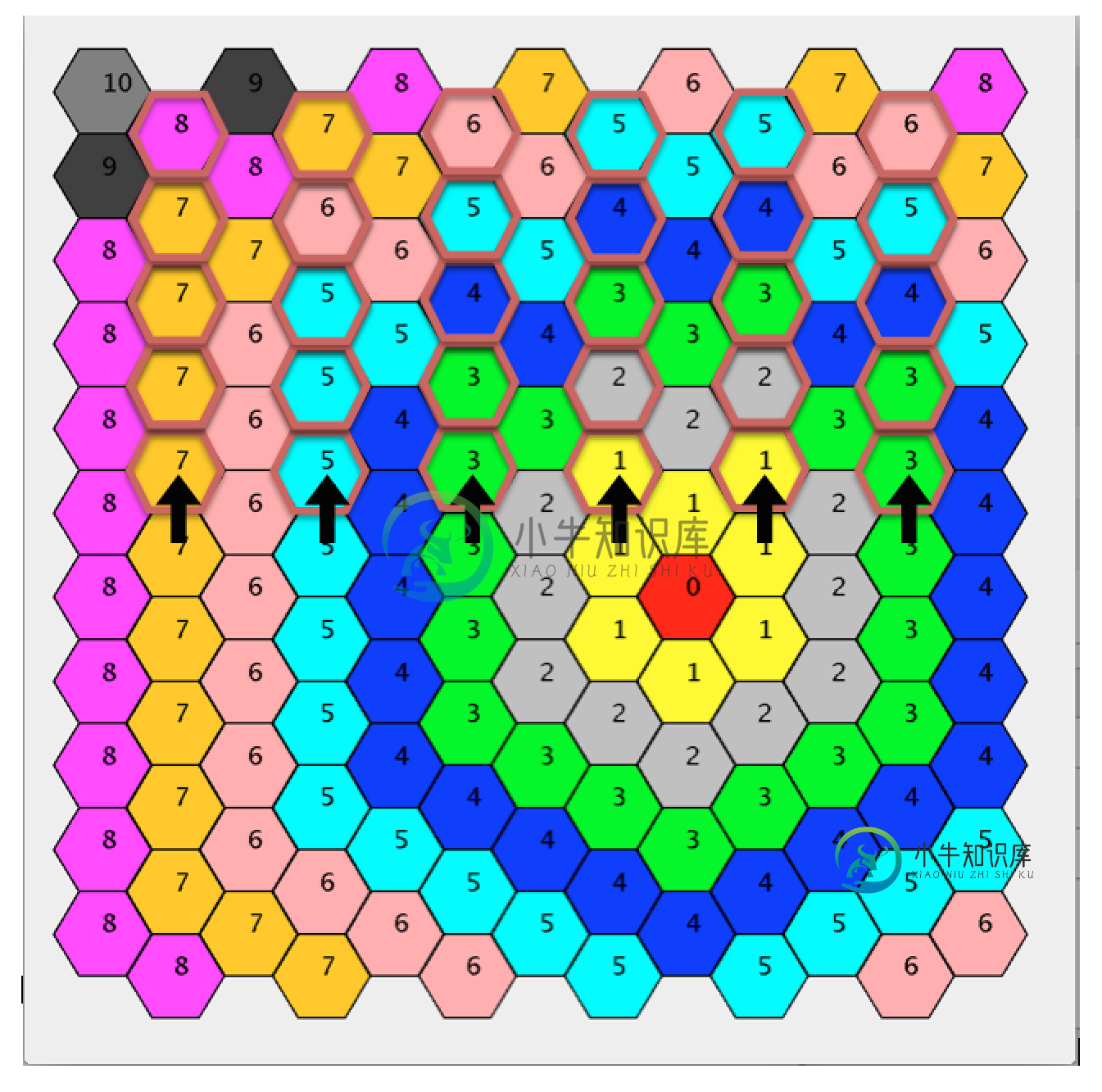 六角网格(平顶)距离计算
六角网格(平顶)距离计算改变这个.. 对此..
-
iText java-垂直和水平拆分表
我是一名iText java开发人员。我一直在处理大型表,现在我陷入了垂直拆分表的困境。 在iText In Action的第119页,尊敬的布鲁诺·洛瓦吉(我非常尊重这个家伙)解释了如何拆分一个大表,使列出现在两个不同的页面中。 我遵循了他的示例,当文档只有几行时,它工作得很好。 在我的例子中,我有100行,要求文档需要在几页中拆分100行,同时垂直拆分列。我按如下方式运行我的代码,但只显示前3