《平安》专题
-
将平面数组转换为多维
问题内容: 我有一个包含树数据的数组(按父ID)。我想将其转换为多维数组。做到这一点的最佳方法是什么?是否有任何简短功能? 源数组: 源数组中缺少某些父母。我希望缺少父项的项成为根。结果数组: 更新:删除方括号。 问题答案: 我认为PHP中没有内置函数可以做到这一点。 我尝试了以下代码,似乎可以按照您描述的方式准备嵌套数组: 我在为演示文稿SQL和PHP中的层次模型编写的PHP类中编写了类似的算法
-
具有Google IDP的GCP身份平台
我在谷歌云平台上部署了一个web应用程序 在这个网络应用程序中,我们需要在google身份上设置对用户的身份验证,并根据他们的角色对他们进行授权。 我们采用了基于SAML的方法,其中包括 创建SAML应用程序作为身份提供者 设置SAML断言使用者服务(ACS) 通过ACS使用webapp中的身份 现在,与其开发一个明确的ACS,我们可以 在GCP中启用Identity Platform 设置SAM
-
跨平台摄像机和画廊(Xamarin)
我需要在Android/Ios的xamarin中使用camera/gallery。有办法吗?
-
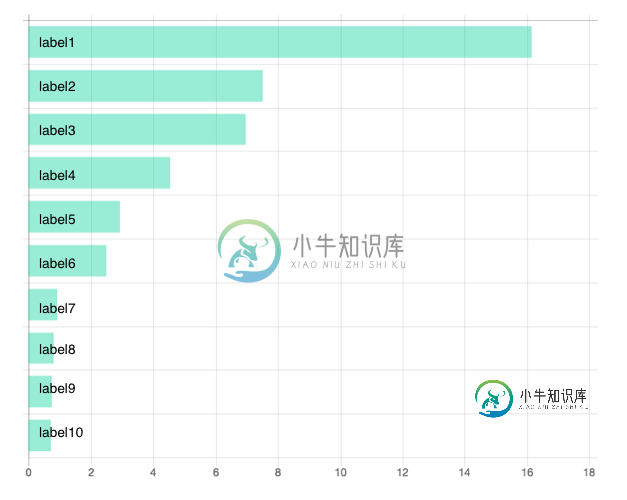 Chart.js-在水平栏内书写标签?
Chart.js-在水平栏内书写标签?在图表中。js,有没有办法在图表中的水平条内写入标签?例如: 在图表中是否有类似的情况。js? 谢谢
-
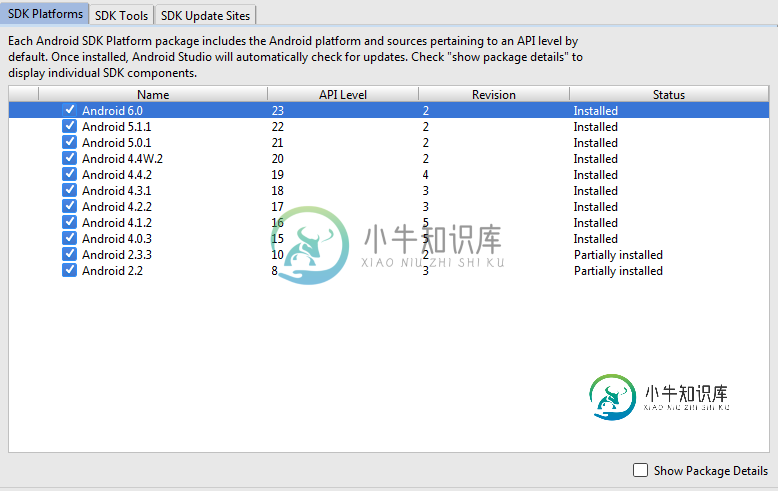 Cordova-错误:无法获取平台android
Cordova-错误:无法获取平台android我安装了cordova并创建了一个新项目。 但当我使用此命令添加android平台时: 科尔多瓦平台添加Android 出现以下错误: 这就是我创建新项目的方式: 科尔多瓦创建你好com.example.helloHelloWorld 这是我的SDK管理器: 但我可以添加ios平台(但我在Windows上工作)
-
API平台alice UserDataPerchat不使用夹具
我配置了以下UserDataPersister(直接取自教程): 和以下用户夹具: 但是我在加载这个夹具时会出现错误: 我的UserDataPersister实现与此相同。
-
循环java中Rnd Num的平均值
当我生成3个介于1和20之间的随机整数时,我一直在尝试计算平均值。我必须将平均值四舍五入到int,然后重复10000次。当我重复测试我的程序2次时,我得到以下输出: 然而,平均值应该是3个数字的平均值。这里,第二个循环将第一个循环的和与第二个循环的和相加,使得平均值错误(和:34 22=56)。我希望它是22,所以平均值是7。我注意到问题可能是这一行,sum=n,但我不知道如何将每个循环的3个数字
-
如何使用LINQ C#展平列表?
本文向大家介绍如何使用LINQ C#展平列表?,包括了如何使用LINQ C#展平列表?的使用技巧和注意事项,需要的朋友参考一下 展平列表意味着将List <List <T >>转换为List <T>。例如,让我们考虑一个List <List <int >>,它需要转换为List <int>。 LINQ中的SelectMany用于将序列的每个元素投影到IEnumerable <T>,然后将所得序列展
-
Linux平台mysql开启远程登录
本文向大家介绍Linux平台mysql开启远程登录,包括了Linux平台mysql开启远程登录的使用技巧和注意事项,需要的朋友参考一下 开发过程中经常遇到远程访问mysql的问题,每次都需要搜索,感觉太麻烦,这里记录下,也方便我以后查阅。 首先访问本机的mysql(用ssh登录终端,输入如下命令): mysql -uroot -p 输入密码登陆进去后,输入如下的语句: 其中: user是用户名 m
-
在openTelemetry collector中平衡导出到jaeger
我有文档中所述的配置 收集器产生错误。如何配置收集器以平衡导出器在不同后端发送请求? info exporterhelper/queued_retry.go:276导出失败。将在间隔后重试请求。{"component_kind":"导出器","component_type":"jaeger","component_name":"jaeger","错误":"无法通过Jaeger导出器推送跟踪数据:
-
Spring靴平地机面临的问题
使用梯度抛出错误的Spring boot应用程序 java.lang.IllegalArgumentException:org.springframework.util.assert.notempty(assert.java:467)~[spring-core-5.3.0-snapshot.jar:5.3.0-snapshot]在org.springframework.boot.springapp
-
将关联表展平为多值列?
问题内容: 我有一张只包含产品ID和类别ID的表(产品可以在多个类别中)。如何将类别ID展平到产品列中,所以我以此结束: 就像我需要循环到类别列的单独表中一样。我该怎么办?或者有更好的方法吗? 问题答案: 在MSSQL中没有内置的方法可以做到这一点。 在Microsoft SQL Server 2005中模拟group_concat MySQL函数? 很好地描述了如何实施变通办法。
-
平方列表中的所有元素
问题内容: 有人告诉我 编写一个函数square(a),该函数接受一个数字数组a并返回一个包含每个平方值的数组。 起初,我有 但是,由于我正在打印,而且没有像被问到的那样返回,因此这不起作用。所以我尝试了 但这仅平方我数组的最后一个数字。我如何才能使整个列表平方? 问题答案: 您可以使用列表理解: 或者您可以: 或者,您可以使用发电机。它不会返回列表,但是您仍然可以迭代它,并且由于不必分配整个新列
-
如何在sqlite中计算平方根
问题内容: 我需要在sqlite数据库中计算欧几里得距离。 除了编写和加载用于数学函数的动态库外,有人知道如何在sqlite中计算平方根吗? 我快要在这里http://en.wikipedia.org/wiki/Fast_inverse_square_root求助于快速反平方根算法,尽管它可能会变得比我现在需要的更多乐趣。 另外,很高兴弄清楚如何进行幂运算(这是一个普遍的问题,比单独乘以一个数字更
-
 Mac Kubernetes负载平衡器NoHttpResponseException的Docker
Mac Kubernetes负载平衡器NoHttpResponseException的Docker我正在尝试运行一个连接到部署pod的简单负载平衡服务器。 我安装了Docker for Mac edge版本。 问题是,当我尝试向公开的负载均衡器urlhttp://localhost:8081/api/v1/posts/health发出GET请求时,出现的错误是: org.apache.http.localhost:8081响应失败 做的时候: 我得到: 很明显,服务正在运行,但localhos