《猫眼娱乐》专题
-
由于Unicode解码错误,无法在熊猫中打开csv文件
我保存了一个熊猫数据框作为CSV使用 但是当我读到它在使用 我收到一条错误消息说 UnicodeDecodeError:“utf-8”编解码器无法解码位置158处的字节0xbf:无效的开始字节 我已经尝试通过使用打开csv文件来强制读取时的编码为utf-8 真的卡住了,有人能帮忙吗? 非常感谢
-
什么是'级别','键',和名称参数在熊猫的conat函数?
如何使用 Pandas的concat功能是合并实用程序的瑞士军刀。在各种各样的情况下它是有用的。现有文档遗漏了一些可选参数的细节。其中包括和参数。我开始弄清楚这些论点的作用。 我将提出一个问题,它将作为进入。 考虑数据帧<代码> d1 ,<代码> D2< /代码>,和<代码> D3< /代码>: 如果我把它们连在一起 我通过用于我的对象: 但是,我想使用参数留档: 级别:序列列表,默认为无。用于构
-
熊猫:根据更复杂的标准选择和修改数据帧
我在看这个和这个线索,虽然我的问题没有那么不同,但有一些不同。我有一个满是
-
在熊猫中,如何水平连接,然后删除多余的列
假设我有两个数据帧。 DF1:col1,col2,col3, DF2:col2,col4,col5 如何水平连接这两个数据帧,并使用col1、col2、col3、col4和col5?现在,我在做pd。concat([DF1,DF2],axis=1),但它最终有两个col2。假设两个col2中的所有值都相同,我只希望有一列。
-
熊猫。果心常见的PandaError:未正确调用DataFrame构造函数
我正在尝试使用mosquitto接收数据,并使用python pandas将其保存为csv文件。在我停止脚本之前,数据是连续的。 mqtt\U发布。py mqtt_sub.py代码 从上面的脚本中,我得到了测试。csv
-
从带有日期索引的多个csv文件创建熊猫DataFrame
我有多个CSV文件与测量数据,我将需要合并到一个熊猫DataFrame与日期/时间作为索引。我尝试过使用pd.concat,但是,这只是把csv文件添加在一起,并不能正确地“排序”它们。 示例文件1: 示例文件2: 如何将文件导入到一个数据帧中,使其按索引和名称进行排序??
-
 空熊猫数据帧填充随机值,如何使其全部NaN?
空熊猫数据帧填充随机值,如何使其全部NaN?我试图用python中的pandas和numpy创建一个空的数据帧,这样一个数据帧就充满了NaN,但每次它似乎都充满了值。为什么会发生这种情况,我如何使一个空的? 这是我已经尝试过的: 我使用的方法是基于关于制作空数据框的问题的答案,在这些问题中,它们声明它们应该工作。但是我没有得到想要的结果。那么如何创建一个空数据框呢?
-
熊猫数据框系列:检查是否存在特定值[重复]
如果列表中的值存在于其中一个dataframe列中,我需要迭代列表并执行特定操作。我试着按照下面的方法做,但发现了下面的错误 '错误:#序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all() 所需输出:
-
熊猫:索引数据帧时出现多个条件-意外行为
我过滤的数据框中的行的值在两个列。 出于某种原因,OR运算符的行为与我期望的和运算符的行为相同,反之亦然。 我的测试代码: 结果是: 如您所见,运算符会删除至少一个值等于的每一行。另一方面,运算符要求两个值都等于,才能删除它们。我预期的结果恰恰相反。有人能解释一下这种行为吗? 我用的是熊猫0.13.1。
-
熊猫-将数据框多索引转换为日期时间对象
问题内容: 考虑一个输入文件: 我可以将每月总计进行分组,如下所示: 分组总数的索引如下: 我想将索引重新格式化为日期时间格式(天可以是一个月的第一天)。 我尝试了以下方法: 和 都失败了。有人知道我该怎么做吗? 问题答案: 考虑按“ M”进行重采样,而不是按DatetimeIndex的属性分组: 注意:如果您不想在这两个月之间,则必须删除NaN。
-
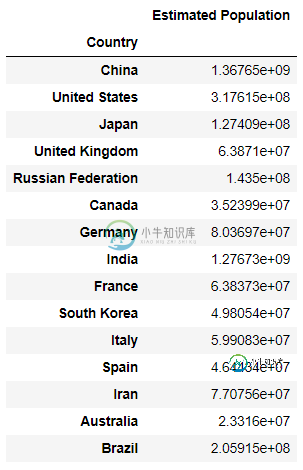 如何按字典分组和聚合熊猫数据目录[副本]
如何按字典分组和聚合熊猫数据目录[副本]该索引有15个国家名称。我还有一本字典: 词典中的所有国家都出现在数据目录中。使用给定的字典,我需要“按大陆对国家进行分组,然后创建一个数据框架,显示每个国家估计人口的平均值和性病偏差。” 这是我尝试的代码: 当我运行这段代码时,我得到错误“没有要聚合的数字类型” 然后我尝试了以下代码: 这会给我一个错误“缓冲区的维度数不对(预期为1,实际为2)” 如何消除这些错误并获得所需的数据库?
-
迭代熊猫数据框,检查值并创建其中的一些
问题内容: 好的,我有一个(大)数据框,如下所示: 如您所见,数据框具有一列,一列,每天有四个小时(00、06、12、18)和一列。 问题在于数据框中缺少日期,在上面的示例中,第8行和第9行之间应该有两个额外的行,分别对应于小时和当天,并且在第9行和第10行之间应该有一个额外的行,对应于小时和日期。一天中的一个小时。 我需要什么? 我想对数据框的列进行迭代,检查每天是否存在并且没有人丢失,并且每天
-
具有$ or条件的猫鼬的find方法无法正常工作
问题内容: 最近,我开始在Node.js上将MongoDB与Mongoose结合使用。 当我将Model.find方法与条件和字段一起使用时,猫鼬无法正常工作。 这不起作用: 顺便说一句,如果我删除了’_id’部分,这确实可行! 在MongoDB Shell中,两者都可以正常工作。 问题答案: 我通过谷歌搜索解决了这个问题:
-
熊猫在特定行将数据框拆分为两个数据框
问题内容: 我有从构成的DataFrame 。一行包含96个值,我想将DataFrame与值72分开。 以便将行的前72个值存储在Dataframe1中,并将行的后24个值存储在Dataframe2中。 我按如下方式创建我的DF: 问题是:如何拆分它们?:) 问题答案: (iloc文档)
-
Python如何抓取天猫商品详细信息及交易记录
本文向大家介绍Python如何抓取天猫商品详细信息及交易记录,包括了Python如何抓取天猫商品详细信息及交易记录的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Python抓取天猫商品详细信息及交易记录的具体代码,供大家参考,具体内容如下 一、搭建Python环境 本帖使用的是Python 2.7 涉及到的模块:spynner, scrapy, bs4, pymmssql 二、要获