
如何按字典分组和聚合熊猫数据目录[副本]

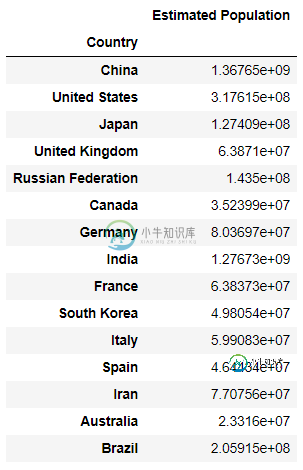
该索引有15个国家名称。我还有一本字典:
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
词典中的所有国家都出现在数据目录中。使用给定的字典,我需要“按大陆对国家进行分组,然后创建一个数据框架,显示每个国家估计人口的平均值和性病偏差。”
这是我尝试的代码:
df2=df.groupby(ContinentDict)['Estimated Population'].agg({'mean':np.mean,'std':np.std})
当我运行这段代码时,我得到错误“没有要聚合的数字类型”
然后我尝试了以下代码:
df2=pd.to_numeric(df.groupby(ContinentDict)['Estimated Population']).agg({'mean':np.mean,'std':np.std})
这会给我一个错误“缓冲区的维度数不对(预期为1,实际为2)”
如何消除这些错误并获得所需的数据库?
共有1个答案

在应用.agg函数之前,需要更改估计填充列的dtype。
使用:
df['Estimated Population'] = df['Estimated Population'].astype(float)
或者,
df['Estimated Population'] = pd.to_numeric(df['Estimated Population'])
-
我用熊猫数据框来处理数据。现在我需要聚合数据,并想知道如何聚合数据。 我有: 我想用打印创建:
-
我有一个数据框,其中包含各种建筑的消费数据。这些建筑被划分为几个类别,并进一步划分为子类别。如何返回每个子类别本身的建筑数量计数?
-
我有一个非常大的 pyspark 数据帧和一个较小的熊猫数据帧,我读入如下: 这两个数据帧都包含标记为“A”和“B”的列。我想创建另一个 pyspark 数据帧,其中只有 df1 中的那些行,其中“A”和“B”列中的条目出现在 中同名的列中。也就是说,使用 df2 的列“A”和“B”过滤 df1。 通常我认为这将是一个连接(通过实现),但是如何将熊猫数据帧与 pyspark 数据帧连接起来? 我负
-
如何通过键访问Groupby对象中相应的Groupby数据框? 使用以下groupby: 我可以迭代它来获取密钥和组: 我想能够访问一个组的关键: 但是当我试着用这样做时,我得到了一个奇怪的对象,它似乎没有任何与我想要的数据帧对应的方法。 我能想到的最好的办法是: 但是考虑到熊猫在这些事情上通常有多好,这有点令人讨厌。 这样做的内置方法是什么?
-
我试图开发以下过滤器与熊猫数据帧: 我有四列,,,和 如何将其作为聚合函数编写? 下面是一个编写效率低下的工作示例: 输出:
-
拿着字典: 我如何把这个字典变成一个数据框,其中的值是列?即。我想要一个数据框显示: 这种形式似乎根本得不到! 谢谢 这是一个不同的问题,另一个问题只是问如何将字典的值放入数据帧,我问的是如何获得我概述的特定形式