
空熊猫数据帧填充随机值,如何使其全部NaN?

我试图用python中的pandas和numpy创建一个空的数据帧,这样一个数据帧就充满了NaN,但每次它似乎都充满了值。为什么会发生这种情况,我如何使一个空的?
这是我已经尝试过的:
data_class_b = pd.DataFrame(np.NaN, index=range(len(df)), columns=[0,1])
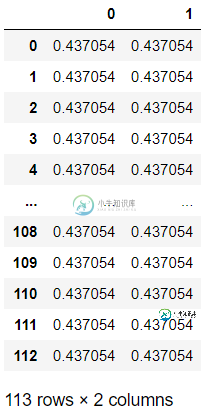
data_class_b = pd.DataFrame(np.empty((len(df),2)))
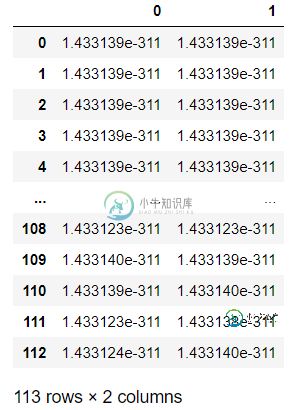
我使用的方法是基于关于制作空数据框的问题的答案,在这些问题中,它们声明它们应该工作。但是我没有得到想要的结果。那么如何创建一个空数据框呢?
共有2个答案

我重启了我的笔记本电脑,现在它工作了,所以我仍然不知道为什么它以前不工作,但现在工作了。在我发布这个问题之前,我已经重新启动了python程序,但这并没有做到。

尝试删除np.nan:
data_class_b = pd.DataFrame(index=range(len(df)), columns=[0,1])
但对我来说,这也是正确的:
data_class_b = pd.DataFrame(np.NaN, index=range(len(df)), columns=[0,1])
-
向对象似乎很难完成。有3个与此相关的stackoverflow问题,没有一个给出有效的答案。 这就是我要做的。我有一个DataFrame,我已经知道它的形状以及行和列的名称。 现在,我有了一个迭代计算行值的函数。我如何用字典或?以下是失败的各种尝试: 显然,它试图添加一列而不是一行。 非常不具信息性的错误消息。 显然,这仅用于在数据框中设置单个值。 我不想忽略索引,否则结果如下: 它确实对齐了列名
-
我正在尝试合并两个数据帧: 第一个数据帧,,用INTEGERS/STRINGS填充 左边的数据框一起被整数/列表填充。 当我使用pandas函数时,新的数据框将用NaN填充右侧的数据框,而不是列表 我期望使用两个原始数据帧中的值创建一个新的合并数据帧。相反,在新的数据框中,“control”数据框中的所有值都是正确的,但“together”数据框中的所有列表都是正确的 以下是一些样本数据: 以下是
-
我试图通过保持行之间的一致性来随机化我的行,但会混淆行的顺序,从而随机化从属变量。我有以下数据帧: 并将行随机化: 然后执行重置索引,如 期望输出:
-
然后,我会添加初始值,然后查看这个数据,从前面的行计算新行,例如左右。 我目前使用的代码如下所示,但我觉得它有点难看,必须有一种方法直接使用DataFrame来实现这一点,或者只是一种更好的方法。注意:我使用的是Python2.7。
-
我从熊猫数据帧文档开始:数据结构简介 我想在一个时间序列类型的计算中迭代地填充数据帧。所以基本上,我想用列A、B和时间戳行初始化数据帧,全0或全NaN。 然后,我会添加初始值并检查这些数据,根据之前的行计算新行,比如说< code > row[A][t]= row[A][t-1]1 左右。 我目前正在使用下面的代码,但我觉得它有点难看,必须有一种方法直接用数据帧来做这件事,或者一般来说是一种更好的
-
我有两个Dataframes一个与日期集(df1)和另一个与emp_ids集(df2)。我试图创建一个新的Dataframe,这样df2中的每个emp_id都被标记为df1中的每个日期。 下面给出了我的数据帧的外观 df1 df2 预期产出: 我将日期列转换为字符串,并尝试执行以下操作,但返回的数据框为空 我尝试做