《阿里巴巴面试》专题
-
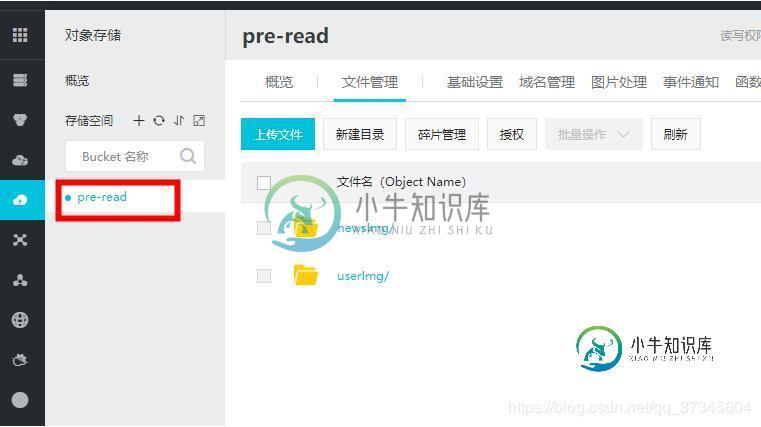 SpringBoot集成阿里云OSS图片上传
SpringBoot集成阿里云OSS图片上传本文向大家介绍SpringBoot集成阿里云OSS图片上传,包括了SpringBoot集成阿里云OSS图片上传的使用技巧和注意事项,需要的朋友参考一下 简述 最近做的公司项目,图片比较多,不想给其存储到自己服务器上,就买了阿里云的OSS服务器来哦进行存储,其实集成第三方平台,一般没什么难度,当然,你要仔细看对方的API文档,这篇主要说一下个人集成OSS的过程 步骤 1、pom.xml中添加OSS的
-
阿里云服务器ubuntu 配置教程
本文向大家介绍阿里云服务器ubuntu 配置教程,包括了阿里云服务器ubuntu 配置教程的使用技巧和注意事项,需要的朋友参考一下 由于阿里云的导入自定义 ubuntu 镜像需要开通 OSS 快照是收费的(看着感觉不贵,但是也很麻烦),而且自己已配置好的镜像想导入需要转换格式,还存在不能使用的情况,所以麻烦点直接在阿里云原来的ubuntu里直接配置需要用到的内容。 首先,阿里云服务器ubuntu默
-
 阿里云!我胡汉三又回来啦!
阿里云!我胡汉三又回来啦!2023-3-22 阿里云-RDS产品部 想不到吧阿里云,我从地狱回来啦!(此处脑补奇异博士:我是来谈判的阿里云!) 这次,吃了上一次的亏,我终于结合着自己的项目投了个还算相关的部门,做数据库的(当然上次计网死得太惨,回去也是恶补了计网和网络编程) 只能说尽力了,有些问题知道答案但没复习完,认了认了 但是……但是……这个面试官究竟是谁!我真的太爱这个面试官了!!!!怎么有人面试这么亲和,完全就是领
-
 阿里国际站行业运营凉经
阿里国际站行业运营凉经自我介绍 从最近的实习经历开始,详细询问项目的具体操作,包括成本和佣金等细节。 实习过程中遇到的最大困难是什么 觉得那段实习收获最大? 对阿里巴巴国际站的了解程度 跨境电商与国内电商有什么区别? 对别的电商平台有什么了解? 跨境电商需要哪些能力? 反问 面试官态度很好,也指出了我在跨境电商实习经验上的不足……还是比较看重个人能力与岗位的匹配度吧,可能跨境电商对我来说还是不太适合,专业知识上不懂的太
-
 阿里大文娱 优酷 后端凉经
阿里大文娱 优酷 后端凉经先问项目 八股问 mysql 乐观锁 聚簇索引 然后问有没有大模型 transformer经验 反问如何提升 建议学习spring 源码 数据结构 redis
-
阿里云 - 挖矿病毒文件目录?
最近服务器被挖矿程序入侵了,会定时创建crontab任务,如下: 0 2 * * * .//kworkers 但是我有个奇怪的问题,这个.//kworkers怎么理解,既不是相对路径又不是绝对路径,./是当前目录,/是跟目录,那.//是个啥?我试过,linux下是创建不了一个/开头的文件的。 最后附上我解决这个挖矿病毒的办法:挖矿程序入侵服务器导致cpu 100%排查
-
 阿里云大数据基础技术工程后端实习一面
阿里云大数据基础技术工程后端实习一面2023实习第四场面试(2023.03.13) 50min 电话面,面试官很好很耐心,收获很大; 约面的时候其实我已经进系统投了其他部门了,然后说“那先面一下吧,之后再说” (腆脸要了一次面试机会哈哈哈哈) 1.自我介绍 2.进程线程最本质的区别 3.进程间通信方式 4.操作系统内存回收机制 5.如果内存回收和直接回收之后,内存还是不够怎么办 6.实际使用当中,如果我有些进程重要程度很高,但占用内
-
 血泪教训:投大厂,要趁早(阿里前端一面凉经)
血泪教训:投大厂,要趁早(阿里前端一面凉经)8.30 投简历 投晚了,阿里校招刚出的时候感觉还没准备好,打算再攒攒面经刷刷题 后面才知道,时间不等人,在你犹豫的同时别人已经上车了,座位就会少一个 9.6 19:30 一面(≈60min) 属于是电话面📞吧? 面试开始前5分钟面试官给发了个链接,里面有道代码题 到点了面试官就打电话过来了,说先做一下这个题
-
 23秋招 补录 阿里 数据研发工程师 面经 已offer
23秋招 补录 阿里 数据研发工程师 面经 已offer准备面试过程中搜数据开发岗面经还是费了点劲的 所以在此记录一下攒人品 之后各位uu能多一点参考 背景 阿里的数据研发(不是大数据研发)校招的时候对技术要求不高比较随意 所以我这种数据分析岗位背景的人简历也是秒过 还有蚂蚁的某些数据开发也是这样的 之前找过我说现有的技术栈没问题 但我因为自我感觉不行+对数据分析的执着给拒了!!大家不要学我可以多看看机会 数据分析岗位基本趋于饱和 只看大公司+数据分析
-
 字节跳动QA、虾皮阿里深信服测开社招面筋
字节跳动QA、虾皮阿里深信服测开社招面筋简单描述下楼主的情况,本科985,毕业1.5年,一直是做测开,今年拿到字节和虾皮的offer(可提供字节内推,放最后) 因为当初面试的时候把所有的题目都整理到一起了,具体细节可能不太清晰,就先分享一下印象比较深的问题,然后把具体的知识点放后面了 深信服 一面: 常规的知识点面试,侧重python和linux相关的知识 1、python的深拷贝、浅拷贝的区别 2、python的内存管理机制(垃圾回收
-
 10.22 大数据工程师 阿里国际 百度 面经(带答案)
10.22 大数据工程师 阿里国际 百度 面经(带答案)数据库底层索引的优劣势? 数据库底层索引的优势和劣势主要取决于具体的索引类型和使用场景: 优势: 提升查询性能:索引可以加快数据库的查询速度,通过跳过不需要的数据块,减少了磁盘I/O操作。 加速排序:索引可以帮助数据库对查询结果进行排序,从而提高排序的效率。 支持唯一性约束:索引可以保证某一列或多列的唯一性,保证数据的完整性。 提高并发性能:索引可以减少数据的锁竞争,提高数据库的并发性能。 支持数
-
 阿里菜鸟CV算法工程师自动驾驶一面凉经
阿里菜鸟CV算法工程师自动驾驶一面凉经9.9面试的,上来没自我介绍环节,直接简历项目开始过,比赛,论文,实习,中间穿插八股:BN和LN区别,transformer encoder组成,BERT等等,应该是都答上来了。 之后手撕,很简单求根号,没用二分,用梯度下降写出来了,被老哥表扬(大四机器学习课考过,做题家基因动了)。 最后说岗位匹配的问题,因为之前没做过自动驾驶,我就拼命说对这个方向感兴趣,自己这两天看过哪些论文(真的是为了这个岗
-
 2023秋招offer阿里、百度、美团、快手、滴滴、华为面经
2023秋招offer阿里、百度、美团、快手、滴滴、华为面经我面的全都是机器学习/AI/计算机视觉算法岗,拿到了自己满意的offer,菜菜的小孙同学来牛客还愿啦,希望能帮助他其他小伙伴吖,祝愿大家都能拿到心仪的offer哇! 本人本硕985,研究大方向深度学习,小方向应用于计算机视觉的连续学习/增量学习/终身学习,同时涉猎了一点元学习、多任务学习、可解释性机器学习这部分的内容。研究生期间一共完成了三篇工作,一篇nips一作(oral),一篇aaai学生二作
-
 阿里大淘宝商业化中心暑期实习Java一面(1.5h)
阿里大淘宝商业化中心暑期实习Java一面(1.5h)自我介绍 项目 后端为什么采用token机制进行幂等性校验而不用订单号? 为什么用redis来存储token? redis单机实现会有问题吗?(无法高可用) redis集群(主从、分片) 采用什么协议实现? 主从架构下当我数据很多的时候怎么办? 缓存雪崩、缓存穿透、缓存击穿 如果一个key刚才数据库里没有现在有了,布隆过滤器怎么处理? 布隆过滤器的优势劣势 布隆过滤器如何删数据 redis数据结构
-
 9.26阿里后端笔试第3题,解题思路
9.26阿里后端笔试第3题,解题思路题目: 给定一个长度为n的数组{a1,a2,a3,..,an},定义一个操作:每次选择一个数x,使数组中所有x变成x+1,问至少需要多少次操作,才能得到非降数组 数据范围: 1<=n<=2*10^5; 1<=ai<=10^9 示例: 输入 2,5,3,4,9,7 输出 4 说明: step 0: 2,5,3,4,9,7 step 1: 2,5,4,4,9,7 step 2: 2,