《群面》专题
-
Spark Streaming和Kafka:一个集群还是几个独立的盒子?
我要做一个关于使用火花流Kafka集成的决定。 一个Kafka主题和一个星火集群。 几个Kafka主题和几个独立的Spark盒(每个主题有一台带有独立Spark集群的机器) 几个Kafka主题和一个星火集群。 我很想选择第二种方案,但我找不到人谈论这样的解决方案。
-
如何创建跨越两个区域的GCP Kubernetes引擎集群?
-
如何在google cloud dataproc集群上同时使用jupyter、pyspark和cassandra
我试图让这三个工具在谷歌云平台上一起工作。所以我使用Dataproc创建了一个带有初始化脚本的Spark集群来安装cassandra和jupyter。 当我用ssh连接集群并启动“pyspark—packages datastax:spark cassandra connector:2.3.0-s_2.11”时,一切似乎都正常 编辑:事实上,spark shell可以,但pyspark不行。 我不
-
使用Java对启用Kerberos的Hadoop集群进行身份验证
我有Kerberos并启用了Hadoop集群。我需要使用Java代码执行HDFS操作。 多谢了。
-
在Hadoop 2.7.2(CentOS 7)集群中,Datanode启动,但不连接到namenode
我安装了一个三节点hadoop集群。主节点和从节点分别启动,但datanode未显示在namenode webUI中。datanode的日志文件显示以下错误: namenode计算机的信息: cat/etc/hosts cat/etc/sysconfig/networkscripts/ifcfg-eth0 cat/etc/hostname 名称 cat核心站点。xml 猫hdfs-site.xml
-
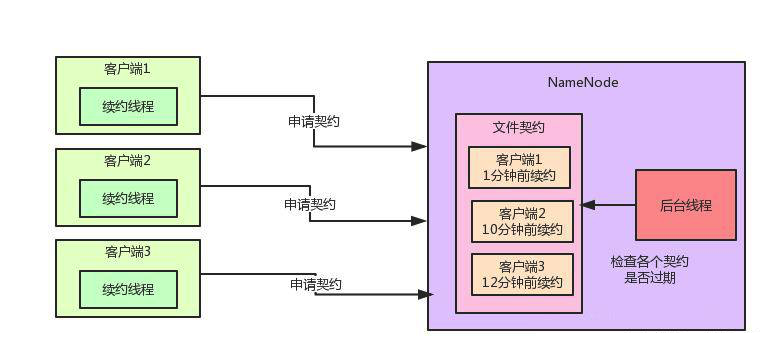 契约机制能让大数据集群性能提升100倍!
契约机制能让大数据集群性能提升100倍!主要内容:一、前情概要,二、背景引入,三、问题凸现,四、Hadoop的优化方案一、前情概要 这篇文章给大家聊聊Hadoop在部署了大规模的集群场景下,大量客户端并发写数据的时候,文件契约监控算法的性能优化。 看懂这篇文章需要一些Hadoop的基础知识背景,还不太了解的兄弟,可以先看看之前的文章:《兄弟们给我10分钟,带你了解一下大数据技术的入门原理和架构设计!》 二、背景引入 先给大家引入一个小的背景,假如多个客户端同时要并发的写Hadoop HDFS上的一个文件,大家觉得
-
7.5 将安全功能应用在正在运行的集群中
通过前面讨论的安全协议,选择一个或者多个协议保护正在运行的集群。 您可以通过以下步骤来完善安全功能: 滚动重启集群节点开启额外的安全端口。 使用安全端口重启客户端而不是 PLAINTEXT 端口(假设你正在设置 client-broker 的安全连接 )。 滚动重启集群节点开启 broker和broker之间的安全模式(如果需要的话)。 最后滚动关闭 PLAINTEXT 端口 关于配置 SSL 和
-
使用 Dumpling 备份 TiDB 集群数据到兼容 S3 的存储
本文详细描述了如何将 Kubernetes 上的 TiDB 集群数据备份到兼容 S3 的存储上。本文档中的“备份”,均是指全量备份(Ad-hoc 全量备份和定时全量备份)。底层通过使用 Dumpling 获取集群的逻辑备份,然后在将备份数据上传到兼容 S3 的存储上。 本文使用的备份方式基于 TiDB Operator 新版(v1.1 及以上)的 CustomResourceDefinition
-
高可用和集群简述 - 高可用与分片的概念
在本文档中,高可用主要指的是解决尽可能在不丢失数据的前提下不间断服务问题,由于redis是异步复制,因此不保证数据完全不丢失,在这个场景下并不实现动态横向扩容,只能进行纵向扩容,你只要加内存,启动redis,设置maxmemory即可。而分片(Sharding)主要指的是解决在线动态横向扩容缩容问题,当然为了稳定也进行高可用部署配置,即包含成对的主从关系。
-
是否可以使用 Spring-Cloud-Streams Kafka-Streams 创建一个多绑定器绑定,以便从集群 A 流式传输并生成到集群 B
我想创建一个带有Spring-Cloud-Streams的Kafka-Streams应用程序,该应用程序集成了2个不同的Kafka集群/设置。我尝试使用文档中提到的多绑定器配置来实现它,类似于以下示例:https://github.com/spring-cloud/spring-cloud-stream-samples/tree/main/multi-binder-samples 给定如下简单函数
-
 腾讯光子-游戏策划凉经 关于我把专业面当成群面准备这件事
腾讯光子-游戏策划凉经 关于我把专业面当成群面准备这件事事情是这样的,我收到邮件的时候我以为接到的是群面,但实际上只写了面试所以是专业面。可能是因为在简历被捞之前,朋友跟我说了他的群面经历,加上收到邮件时神志不清,所以在思维惯性下误以为是群面。而且我事后也没有去检查,就这样按群面准备了三天直到面试开始才发现是专业面。总觉得自己越来越傻是不是脑子出问题。 面试后就觉得凉凉,但 是 竟 然 过 了。 之后认真准备二面,但结果挂了,也是意料之中吧,我确实配不
-
如何在懂你英语30天的社群中,通过用户运营和社群运营实现用户续费,请写出具体执行方案。
本文向大家介绍如何在懂你英语30天的社群中,通过用户运营和社群运营实现用户续费,请写出具体执行方案。相关面试题,主要包含被问及如何在懂你英语30天的社群中,通过用户运营和社群运营实现用户续费,请写出具体执行方案。时的应答技巧和注意事项,需要的朋友参考一下
-
使用flink/kubernetes替换etl作业(在SSI上):每个作业类型一个flink集群,或者每个作业执行创建和销毁flink集群
我正在尝试将使用SSIS包创建的数百个feed文件ETL作业替换为apache flink作业(并将kuberentes作为底层infra)的可行性。我在一些文章中看到的一条建议是“为一种工作使用一个flink集群”。 由于我每天都有少量的每种工作类型的工作,那么这意味着对我来说最好的方法是在执行工作时动态创建flinkcluster并销毁它以释放资源,这是正确的方法吗?我正在建立flinkclu
-
 美团面试题|外卖如何找到用户群体中的大学生并给他们打标签?
美团面试题|外卖如何找到用户群体中的大学生并给他们打标签?Q:已知机型和手机号,美团外卖如何找到用户群体中的大学生群体并给他们打标签(用户群体包括美团用户or其他美团产品用户,不局限于外卖用户)? 对问题进行拆解,既然目的是给用户打标签,那么我们可以倒推从哪些维度来给目标用户打标签。 这里用到的分析思路为:用户消费行为分析,即从用户属性、消费标签、行为标签和内容分析这四方面来倒推潜在的大学生群体。 1、用户属性 这方面主要包括性别、年龄、地域、收入、学历
-
Tcp-IP的HazelCast程序化配置未在群集中添加成员
问题内容: 以下是文档中给出的HazelCast程序配置,但无法在HazelCast群集中添加成员。 请查看代码,如果需要进一步修改以将成员添加到hazelcast集群,请让我看看 问题答案: 添加此行以关闭多播以支持TCP, 将此行移到最后, 您应该在构建实例之前完成配置。