《群面》专题
-
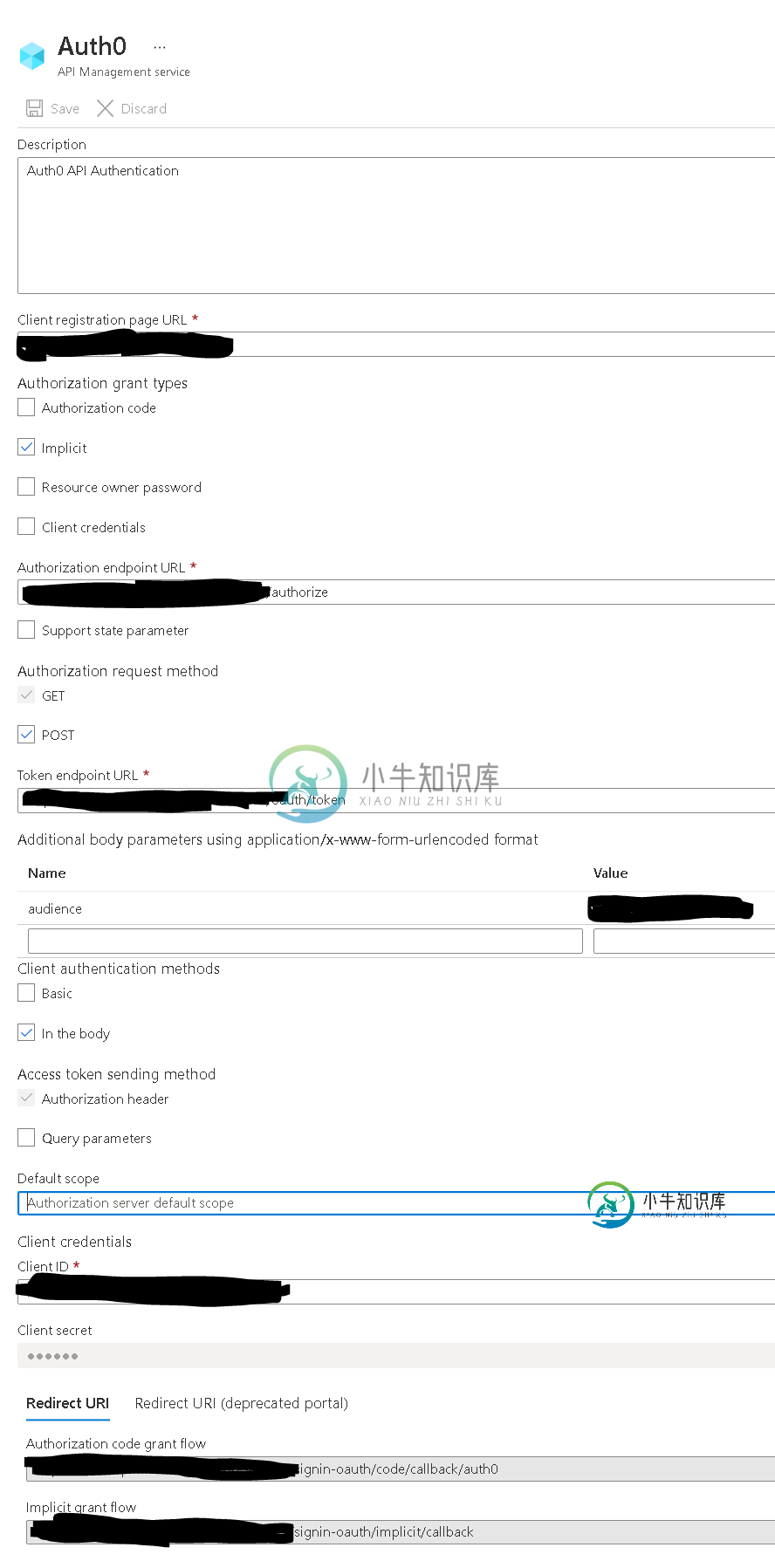 在Azure API管理Oauth2服务中指定访问群体参数
在Azure API管理Oauth2服务中指定访问群体参数我正试图在Azure API管理中设置Oauth2身份验证服务,以便在开发者门户中的Auth0身份提供程序中对用户进行身份验证<但是,我无法配置Oauth2服务来传递audience参数以获取JWT令牌(现在只返回不透明令牌)。 我在Azure门户中创建了一个新的Oath2服务,在“附加身体参数”部分指定了受众: 接下来,我将Oath2服务添加到API中: 接下来,当我尝试在开发者门户中测试API
-
在Azure Kubernetes集群(AKS)上的Nginx入口上配置TCP端口
我可以从外部通过域名导航到我的集群,并看到具有有效HTTPS的控制面板(在15672内部)。所以入口已经启动并运行,我可以创建队列等等。因此rabbitmq工作正常。 但是,我无法使TCP部分工作,以便从集群外部发布到队列。 我已经通过azure portal接口为控制器(nginx-ingress-ingress-nginx-controller)编辑了我认为是configmap(azure-c
-
带有多个Elasticsearch群集的Spring Boot启动速度非常慢
我有Spring启动应用程序与三个弹性搜索群集(ES v6.4.2)配置。application.properties文件如下(我为每个集群配置了三个主节点,但为了简单起见,这里显示了一个): 对于每个集群,我都有一个单独的配置类,在其中设置TransportClient和ElasticsearchTemplate。 现在,当我在本地计算机上运行所有三个集群的情况下本地启动应用程序时,应用程序会正
-
设计:Spring集成:集群环境中的Jdbc入站适配器
我们在Oracle Weblogic 10.3.6服务器中有两个节点的集群环境,它是循环的。 我有一个服务,它从外部系统获取消息并将它们放入数据库(Oracle DB)。 我正在使用jdbc入站适配器转换这些消息并将其传递到通道。一条消息只处理一次。我计划在DB表中有一列(NODE\u NAME)。当从外部系统获取消息的第一个服务也使用NODE_名称(weblogic.NAME)更新列时。在jdb
-
使用混合持久/非持久缓存节点点燃群集
-
org.apache.ignite:连接集群失败,连接失败,重新连接失败
-
 Apache Spark:客户端和集群部署模式之间的差异
Apache Spark:客户端和集群部署模式之间的差异TL;DR:在Spark独立集群中,客户端和集群部署模式之间有什么区别?如何设置应用程序运行的模式? 我们有一个带有三台机器的Spark独立集群,它们都带有Spark 1.6.1: 主机,也是使用运行应用程序的地方 2台相同的工作机 2)如何使用选择应用程序将运行在哪个上?
-
 在Kubernetes集群中使用Helm图访问已部署的服务
在Kubernetes集群中使用Helm图访问已部署的服务目前,我正试图通过创建Helm图表,在Kubernetes集群上部署我的微服务endpointDocker映像。为此,我创建了图表,并更改了values.yaml和deployment.yaml中的参数以进行端口更改。而且我还想从我的角前端访问。所以我添加了service type=nodeport。当我描述该服务时,它给了我可访问的端口。 我访问了http://node-ip:30983/end
-
虽然安装了nginx,但无法连接到我的kubernetes集群
我有一个裸机kubernetes集群。我应用了这样的kubernetes nginx部署:kubectl应用-fhttps://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.34.1/deploy/static/provider/baremetal/deploy.yaml 并添加了这个入口资源: 我的入口资源: 但
-
Kubernetes不在集群中的节点之间进行负载平衡
我按照此处找到的指南设置了一个 4 节点 Kubernetes 集群:https://www.tecmint.com/install-a-kubernetes-cluster-on-centos-8/ 它有一个主节点和3个工作节点。 我正在运行一个名为“hello world”的部署,它基于bashofmann/rancher演示映像,有20个副本。我还创建了一个名为hello world的nod
-
从flink集群外部访问flink状态的方法有哪些?
PS:我们可以将flink状态存储在dynamoDB中,并在那里创建一个API吗?还是以任何其他方式坚持和向外部世界揭露国家?
-
 JSON Web令牌中的客户端ID或多个访问群体
JSON Web令牌中的客户端ID或多个访问群体我在应用程序中使用JWT实现OAuth 2.0,在决定将什么设置为我的aud声明时遇到了困难。用户将通过我的身份验证服务器“登录”到我的客户端,以访问我的API(资源)服务器。我希望我的令牌只对特定客户端和特定API有效。 从我的客户端登录时,我在请求中不包括它的客户端id,但在我发现的大多数实现中,aud设置为该客户端id。我倾向于在我的登录请求中包含一个customer(客户)audience
-
集群环境下的Spring Integration流式入站信道适配器
我需要在多/集群环境中实现sftp流入站通道适配器。我不应该将文件存储在我的本地目录中,我已经流文件并立即处理它。它在单个实例中工作得很好,但是如果我试图在多个节点中运行poller,就会遇到类似重复处理的问题,第二个节点找不到文件。 我尝试使用propertiesmetadatastore按照https://docs.spring.io/spring-integration/reference/
-
Hazelcast集群成员由于大量“isStillRunningService”对象而内存不足
我们有一个在3.5版本上利用Hazelcast IExecutor服务和IMap的系统。我们最近遇到了Hazelcast集群成员在生产中内存不足的情况,一个接一个,最后所有节点都被OOM崩溃。 在进行原因分析时,我们发现下面有数千个日志条目,日志文件大小呈指数级增长。存放原木的存储空间也已经用完。 我知道,集群成员会不断发出心跳,以确保所有成员都活着,我相信默认值是10sec。现在的问题是,如果任
-
在Mac OSX上,HBase无法以单节点群集模式启动
我在我选择的dataDir中观察它的zookeeper_server.pid文件,当我运行jps时,我看到以下内容: 上面的QuorumPeerMain与zookeeper_server.PID中的PID匹配,正如我所料。这样的预期正确吗?从我所做的到目前为止,是否应该期望在这里显示更多的过程? 我安装了hbase-1.1.2。我配置了hbase-site.xml。我将hbase.rootdir设