《群面》专题
-
OpenShift Origin项目在使集群再次运行时迷失了方向
我在这里有一个关于在OpenShift origin上创建的项目的持久性的基本问题。使用以下命令实例化一个非常基本的设置: oc集群up--创建计算机 之后,我创建了一个项目TestProject,并从 添加到项目 - 选项。现在,当我用下面的命令关闭集群并再次启动时,我的项目(TestProject)丢失了,每次启动集群时,我只看到一个名为my project的默认项目。 oc集群停机- doc
-
Spring 启动应用程序无法连接到 kubernetes 集群上的 RabbitMQ
我在我的kubernetes集群上部署了RabbitMQ服务器,我能够从浏览器访问管理用户界面。但是我的Spring启动应用程序无法连接到端口5672,我收到连接拒绝错误。如果我将我的application.yml属性从kuberntes主机替换为localhost并在我的机器上运行docker映像,同样的代码也可以工作。我不确定我做错了什么? 有人试过这种设置吗?请帮帮忙。谢谢!
-
安装配置/Hadoop集群中关于SSH认证权限的问题
今天回北京了,想把在外地做的集群移植回来,需要修改ip地址和一些配置参数,结果在配置的过程中,总是会有一些提示,说是我的机器之间的认证权限有问题。所以对照以前写的安装手册,把ssh重新配置了一遍。但是发现在启动的时候还是有提示,说是我的ssh有错误,还是需要输入yes和密码来登录。总结了一下,内容如下: 1、hadoop的ssh配置namenode无密码访问datanode需要配置各个机器,详细步
-
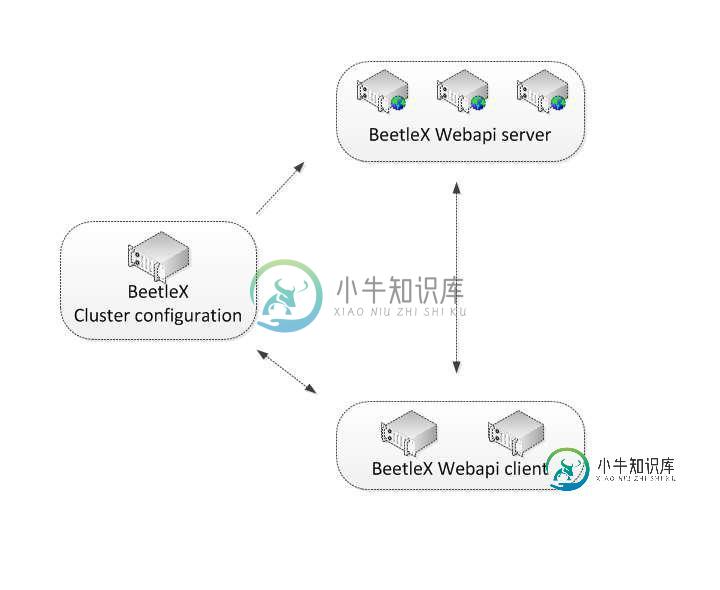 详解.net core下如何简单构建高可用服务集群
详解.net core下如何简单构建高可用服务集群本文向大家介绍详解.net core下如何简单构建高可用服务集群,包括了详解.net core下如何简单构建高可用服务集群的使用技巧和注意事项,需要的朋友参考一下 一说到集群服务相信对普通开发者来说肯定想到很复杂的事情,如zeekeeper ,反向代理服务网关等一系列的搭建和配置等等;总得来说需要有一定经验和规划的团队才能应用起来。在这文章里你能看到在.net core下的另一种集群构建方案,通过
-
将群组总计添加到Pandas数据框中的最佳方法
问题内容: 我有一个简单的任务,我想知道是否有更好/更有效的方法。我有一个看起来像这样的数据框: 我想添加一列来保存组总数的值: 我这样做的方式是: 是否有更好/更干净的方法将这些值直接添加到数据框中? 谢谢您的帮助。 问题答案: df[‘TotalCount’] = df.groupby(‘Group’)[‘Count’].transform(‘sum’) 这里讨论了其他一些选项。
-
重新排序群集编号以获取正确的对应关系
问题内容: 我有一个数据集,使用两个不同的聚类算法进行了聚类。结果大致相同,但是群集编号是置换的。现在,为了显示颜色编码的标签,我希望标签ID对于相同的群集是相同的。如何获得两个标签ID之间的正确排列? 我可以使用蛮力来做到这一点,但也许有更好/更快的方法。我将不胜感激任何帮助或指针。如果可能的话,我正在寻找一个python函数。 问题答案: 寻找最佳匹配的最著名的算法是 匈牙利方法 。 由于无法
-
如何推断读取器endpoint地址从aws_elasticache_replication_group集群模式取消
我不熟悉地形和aws。我需要在禁用群集模式的情况下配置elasticache redis。我已经阅读了aws\u elasticache\u replication\u group resource的文档,它将primary\u endpoint\u address指定为复制组中主节点的endpoint地址(如果禁用群集模式)。 根据aws文档: 对于Redis(禁用群集模式)群集,请将主endp
-
为什么我的Flink独立群集没有收到我的作业?
我在Flink(Java)中创建了一个程序来计算3个不同房间的9个假传感器的平均值。如果我启动jar文件,该程序运行良好。所以我决定启动flink独立集群来检查运行我的作业和相应任务的TaskManager,如这里(https://ci.apache.org/projects/flink/flink-docs-stable/tutorials/local_setup.html)。我正在我的机器上运
-
无法从GCP群集使用VPC对等互连连接到Mongo Atlas
我正在尝试将在GCP库伯内特斯引擎集群上运行的Java应用程序与Mongo Atlas集群(M20)连接起来。以前,当我没有打开VPC Peering并且我使用常规连接字符串时,它运行良好。但我现在正在尝试使用VPC Peering,在我的GCP项目中使用VPC网络。我按照https://docs.atlas.mongodb.com/security-vpc-peering/.中的步骤选择了192
-
在具有Docker容器的独立集群上执行Spark SPARK_PUBLIC_DNS和SPARK_LOCAL_IP
问题内容: 到目前为止,我仅在Linux机器和VM(桥接网络)上运行Spark,但现在我对将更多计算机用作从属设备很感兴趣。在计算机上分发Spark Slave Docker容器并使它们自动连接到硬编码的Spark master IP会很方便。这种不足已经可以解决,但是我在从属容器上配置正确的SPARK_LOCAL_IP(或start-slave.sh的– host参数)时遇到了麻烦。 我认为我已
-
NoSuchElementException火花流查询中的错误,尽管集群配置很重
有人能帮我理解这个错误背后的原因吗: 群集配置为: 数据库运行时5.5 LTS Scala 2.11 Spark 2.4.3 驱动程序:64GB内存,16核,3DBU 工人:64GB mem,16核,3DBU(2-4个工人,自动扩展) fairscheduler中定义了3个并行运行的流式查询。xml Spark配置是: 在下面添加代码流: fairScheduler示例。xml文件:
-
我们如何在Kubernetes集群中获取NodePort服务的NodePort的tcpdump?
我希望有一个指向Kubernetes集群中pod的NodePort服务的节点端口(如30034)的tcpdump。此节点端口服务映射在路径下的入口资源内。当我使用入口内配置的主机点击入口时,我从目标pod得到响应,但tcpdump没有跟踪任何东西。(入口-- 我尝试过:sudo tcpdump-I any port 30034-w tcp dump。但它并没有捕获任何东西。 你能在这里提出建议吗。
-
AWS上具有Kops的Kubernetes群集-节点端口服务不可用
我在访问Kubernetes群集上的NodePort服务时遇到困难。 球门 设置ALB入口控制器,以便我可以使用webockets和超文本传输协议/2 根据该控制器的要求设置NodePort服务 采取的步骤 之前,在AWS eu-west-1上创建了Kops(版本1.6.2)群集。nginx ingress的kops插件以及Kube lego也已添加。ELB入口工作正常。 使用该项目指定的IAM配
-
如何在google容器引擎中为kubernetes集群创建防火墙
这可能是一个非常简单的问题,但我似乎不知道如何只允许从我的office IP访问我的kubernetes集群。 在我的防火墙规则中,我看到我的gke节点规则是2个内部ip和我的office ip。 我还看到了我在外部IP地址中看不到的外部IP范围的防火墙规则。该IP地址也不会出现在我的负载均衡器IP中...... 最后,我有一个负载平衡防火墙规则,它允许负载平衡选项卡中的外部IP范围,这是我的ku
-
在Hadoop 2上运行作业时无法初始化集群异常
问题内容: 所有守护程序都在运行,jps显示: 但是示例继续失败,并带有以下异常: 因为它说问题出在配置中,所以我在这里发布配置文件。目的是创建一个单节点群集。 yarn-site.xml core-site.xml hdfs-site.xml mapred-site.xml 请告诉我们缺少了什么或我在做什么错。 问题答案: 您使用大写字母,这可能是为什么它无法解决的原因。尝试使用官方文档中建议的