《群面》专题
-
Kubernetes集群-无法从多VM k8s集群中另一个pod中运行的Spring Boot服务访问pod中正在运行的Kafka代理
我有一个在多VM环境中运行的Kafka代理(私有云-带有我们自己的库伯内特斯集群-4节点集群)。 我创建了一个spring-boot应用程序,它有一个发布者,必须在Kafka代理中向Kafka主题发布消息。我有两个集装箱(Kafka经纪人 我无法通过在发布者的bootstrap.servers中提供Kafka的服务名称:端口ID来访问Kafka代理(在同一个k8s集群中运行) Spring boo
-
 群面复盘:为电商平台量身打造三个社交功能,说明数据指标?
群面复盘:为电商平台量身打造三个社交功能,说明数据指标?本期群面题目:选择市面已有APP,结合电商平台的特点,为其量身打造三个社交功能,并说明衡量其效果好坏的数据指标? 活动复盘 自我介绍(耗时5min) 自由讨论&汇报(耗时30+5min) (1)读题(耗时5min) (2)第一阶段: 时间划分,角色确定; (3)第二阶段: 选择电商APP: 得物(垂类电商);确定目标、用户画像及使用场景; (4)第三阶段: 产品核心功能讨论:产品定位、产品功能一(
-
 群面题复盘|疫情期间,腾讯文档应该新增哪些功能,如何推广?
群面题复盘|疫情期间,腾讯文档应该新增哪些功能,如何推广?01群面题目 疫情期间,腾讯文档应该新增哪些功能,如何推广? 02 自我介绍(耗时5min) 本次参加的同学们主要是不二产培班的同学以及不二PM的同学,他们大部分毕业于23届,来自国内985、211等重点高校以及海外名校,平均每个人有2段产品相关实习经历。 03 自由讨论&汇报(耗时30+5min) (1)读题(耗时2min) (2)第一阶段: 产品定位——个体用户、企业用户(社区
-
在集群中共享Java同步块,还是使用全局锁?
问题内容: 我有一些代码只想允许一个线程访问。我知道如何使用块或方法来完成此操作,但是在集群环境中可以工作吗? 目标环境是WebSphere 6.0,集群中有2个节点。 我感觉这种方法行不通,因为每个节点上的每个应用程序实例都将拥有自己的JVM,对吗? 我在这里试图做的是在启动系统时对数据库记录进行一些更新。它将查找代码版本之前的所有数据库记录,并执行特定的任务来更新它们。我只希望一个节点执行这些
-
启动hadoop集群时报下图错误,分析什么原因:
本文向大家介绍启动hadoop集群时报下图错误,分析什么原因:相关面试题,主要包含被问及启动hadoop集群时报下图错误,分析什么原因:时的应答技巧和注意事项,需要的朋友参考一下 解答: 1、权限问题,可能曾经用root启动过集群。(例如hadoop搭建的集群,是tmp/hadoop-hadoop/.....) 2、可能是文件夹不存在 3、解决: 删掉tmp下的那个文件,或改成当前用户
-
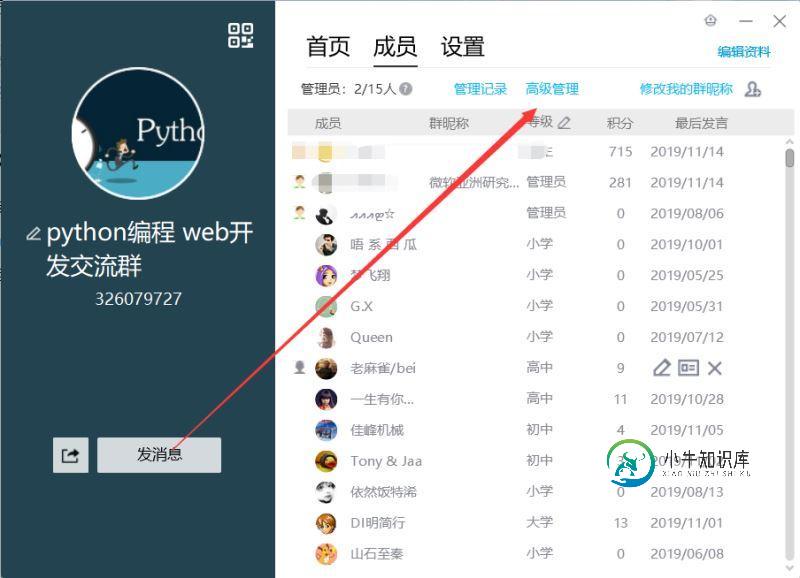 Python获取统计自己的qq群成员信息的方法
Python获取统计自己的qq群成员信息的方法本文向大家介绍Python获取统计自己的qq群成员信息的方法,包括了Python获取统计自己的qq群成员信息的方法的使用技巧和注意事项,需要的朋友参考一下 首先说明一下需要使用的工具以及技术:python3 + selenium selenium安装方法:pip install selenium 前提:获取自己的qq群成员信息,自己必须是群主或者管理员,然后通过管理页面进入到成员高级管理网页端,就
-
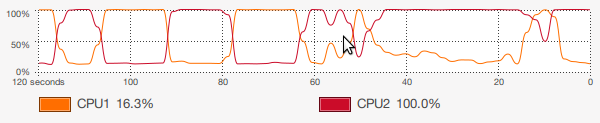 如何在简单的Express应用程序中使用Node.js集群?
如何在简单的Express应用程序中使用Node.js集群?问题内容: —我构建了一个简单的应用程序,该应用程序从Redis数据库中提取数据(50个项目)并将其扔到localhost。我做了一个ApacheBench(c = 100,n = 50000),并且在1.73GHz(我的6岁笔记本电脑)的双核T2080上获得了半不错的150个请求/秒,但是proc的使用非常令人失望显示: 仅使用了一个内核,这是按照Node中的设计进行的,但是我认为,如果我可以使
-
Elastic search给出错误在群集中找不到活动节点
问题内容: 我开始使用Elastic search。我成功在服务器上安装了elasticsearch(与应用程序服务器不同),但是当我尝试从应用程序服务器调用Elatic搜索时出现错误 当我检查Elastic search状态时,它显示 Active 。 如何将Elastic search从我的应用程序服务器调用到elasticsearch服务器。 我的elasticsearch.yml设置 el
-
在Redis集群中使用pipeline批量插入的实现方法
本文向大家介绍在Redis集群中使用pipeline批量插入的实现方法,包括了在Redis集群中使用pipeline批量插入的实现方法的使用技巧和注意事项,需要的朋友参考一下 由于项目中需要使用批量插入功能, 所以在网上查找到了Redis 批量插入可以使用pipeline来高效的插入, 示例代码如下: 但实际上遇到的问题是,项目上所用到的Redis是集群,初始化的时候使用的类是JedisClust
-
Kafka消费群体中只有一个消费者的再平衡
当一个组中只有一个消费者,并且认为消费者无法在session.time.out内进行轮询时,将触发重新平衡,但是在这种情况下,组中只有一个消费者,现在假设session.time.out是30秒和消费者民意调查后50秒组协调员将识别消费者后50秒,并允许它提交偏移或协调员将断开消费者和没有偏移得到提交,并将重新平衡消费者与新的消费者标识?如果上次提交的偏移量是345678,在下一次轮询中,它处理了
-
是否可以在RKE集群上使用云代码(VSCode内部)?
我正在研究是否可以在私有RKE集群上使用云代码(VSCode内部)?使用VSCode,连接到集群的唯一选择似乎包括GCP(或其他大型云计算提供商)或MiniKube。Kubectl在集群上的所有设置和工作都很好--只是在云中没有支持--运行/调试代码等?我运气不好吗?
-
将一个GKE集群拆成“全新”状态而不删除它?
我第一次真正玩Kubernetes,在GCP上有一个全新的(空的)GKE集群。 我将使用YAML Kustomize文件,并尝试在其中部署一些服务,但我真正寻找的是一个命令(或/命令集),以将GKE集群恢复到一个完全“新”的状态。这是因为它可能需要几十个(或更多!)尝试配置和调整我的YAML文件,直到我得到正确的配置和行为,每次我搞砸了,我都想用一个完全“干净”/新的GKE集群重新开始。出于本问题
-
Spark cassandra连接器不能在独立的Spark集群中工作
我有一个向spark独立单节点集群提交spark作业的maven scala应用程序。提交作业时,Spark应用程序尝试使用spark-cassandra-connector访问Amazon EC2实例上托管的cassandra。连接已建立,但不返回结果。一段时间后连接器断开。如果我在本地模式下运行spark,它工作得很好。我试图创建简单的应用程序,代码如下所示: SparkContext.Sca
-
Kafka Connect 集群中只有一个节点响应 REST API 请求
我在不同的主机上运行Kafka Connect集群,我只看到其中一个节点响应REST API请求(特别是:POST、PUT或DELETE请求)的行为。我可以通过关闭一个节点并向另一个活动节点发出写入命令来可靠地交换响应API请求的节点。 这是我的 docker-compose worker 配置: 我可以使用Debezium Postgres连接器和Kafka Snowflake连接器重现它。所以
-
Spring Cloud Admin健康检查 邮件、钉钉群通知的实现
本文向大家介绍Spring Cloud Admin健康检查 邮件、钉钉群通知的实现,包括了Spring Cloud Admin健康检查 邮件、钉钉群通知的实现的使用技巧和注意事项,需要的朋友参考一下 本文主要介绍了Spring Cloud Admin的使用,分享给大家,具体如下: 源码地址:https://github.com/muxiaonong/Spring-Cloud/tree/master