《欢聚集团》专题
-
如果我打算按键执行大量聚合,我应该选择RDD而不是数据集/数据帧吗?
我有一个用例,我打算按键分组,同时在列上聚合。我正在使用Dataset,并试图通过使用groupBy和agg来实现这些操作。以下面的场景为例 我打算把它转换成 为此,我在stack上搜索并找到以下内容: 以上对我来说似乎很整洁。 但在搜索上述内容之前,我首先搜索了数据集是否像RDD一样具有内置的reduceByKey。但找不到,所以选择了上面的。但我读了这篇文章《grouByKey vs redu
-
对顶点进行聚类时。x服务,集群EventBus处理程序是否传播到新加入的节点?
这是我在官方文件或其他任何地方都找不到的东西;我提议的情况基本上是这样的: 我有一个集群的Vert. x实例相同的服务,相同的代码库。 在某个时间点,我注册了一个EventBus消费者,地址为集群范围。我订阅了一个完成处理程序,以便在集群的所有节点上完成注册时收到通知。 一切正常,但现在我向集群添加了一个新节点。 我的问题实际上有两个方面: 消费者会被传播到new-joiner吗?也就是说,如果我
-
何时使用集合与集合?
问题内容: 除了a 和Java 可以两次包含相同的元素外,a 和Java 之间在实践上还有什么区别吗?它们具有相同的方法。 (例如,是否给我更多选择来使用接受s但不接受s的库?) 编辑: 我可以认为至少有5种不同的情况来判断这个问题。其他人还能提出更多建议吗?我想确保我了解这里的微妙之处。 设计接受或参数的方法。更通用,并接受更多输入可能性。(如果我正在设计特定的类或接口,那么对我的消费者会更好,
-
Java中ArrayList的交集和并集
问题内容: 有什么方法可以这样做吗?我一直在寻找,但找不到任何东西。 另一个问题:我需要这些方法,以便可以过滤文件。有些是AND过滤器,有些是OR过滤器(类似于集合论),因此我需要根据所有文件以及保存这些文件的unite / intersects ArrayLists进行过滤。 我是否应该使用其他数据结构来保存文件?还有其他什么可以提供更好的运行时间吗? 问题答案: 这是不使用任何第三方库的简单实
-
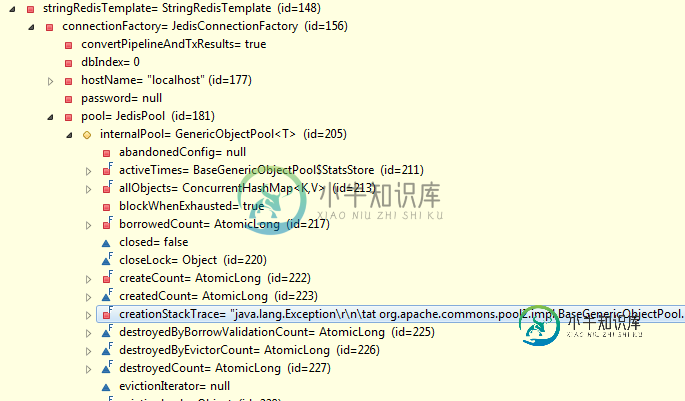 Redis集群与Spring boot的集成
Redis集群与Spring boot的集成我有一个redis集群,有主服务器、从服务器和3个哨兵服务器。主从映射到dns名称node1-redis-dev.com、node2-redis-dev.com。redis服务器版本为2.8 我在application.properties文件中包含以下内容。 但是,当我检查StringRedisTemplate时,在JedisConnectionFactory的hostName属性下,我看到的是
-
Java流-收集、转换和收集
我想获取地图的值,找到min值,并为地图的每个条目构造一个新的CodesWitMinValue实例。我希望使用Java11个流,我可以在多行中使用多个流(一个用于min值,一个用于转换)来实现这一点。是否可以使用java 11流和收集器在单行中实现?谢谢。
-
集合子集的穷举匹配
我有一个关于使用“永远”类型的穷举开关/情况的问题。 比如说,我有一组字符串:{a,B}(字符串可以是任意长的单词,而且集合本身可能非常大),对于每个子集(比如{},{a,B}),我想创建一个函数:show:Set= 预发伪代码: 是否有可能在编译时保证show函数中包含所有可能的子集?所以把C加到集合{A,B,C}需要我扩充show函数吗?并为{C}、{A,C}、{B,C}和{A,B,C}添加案
-
18. 函数的集合与系集
在连续情景中,我们不得不处理函数的集合和函数的系集。由函数集的名字可以看出,它就是一组函数,通常是一个变量——时间的函数。为描述函数集,我们可以给出集合中各种函数的显式表达式,也可以给出只有集合中的函数才拥有的性质。下面是一些示例: 由以下函数组成的集合: 。 的每个具体值确定了集合中的一个特定函数。 一个由时间函数组成的集合,其中包含频率不超过W周期/秒的所有时间函数。 一个由带宽局限于W、幅度
-
MYSQL数组聚合函数,例如PostgreSQL array_agg
问题内容: 我在MySQL上有两个表,我想知道在MySQL上是否有任何聚合函数,如postgreSQL的array_agg()。 表1的属性只有8条记录表2的记录捕获了该属性,因此对于同一属性,有时可以是1或n次,我得到了这个Qry: 如果我使用GROUP BY部分,则会得到以下信息: 丢失了除users_admin_id的第一个值以外的任何其他数据。我知道我可以通过postgreSQL的arra
-
如何在MySQL中组合聚合函数?
问题内容: 我只是在学习MySQL-是否有组合(或嵌套)聚合函数的方法? 给定一个查询: 这将给我每个用户回答的问题数量。我真正想要的是每个用户回答的平均问题数量…… 计算此统计信息的正确方法是什么? 如果有可能,是否有办法针对每个问题分解此统计信息?(用户可以多次回答相同的问题)。就像是: 问题答案: 您必须使用子查询: 您不能将一个聚合与另一个聚合一起包装。如果MySQL支持分析/排序/窗口功
-
 Python聚类算法之DBSACN实例分析
Python聚类算法之DBSACN实例分析本文向大家介绍Python聚类算法之DBSACN实例分析,包括了Python聚类算法之DBSACN实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python聚类算法之DBSACN。分享给大家供大家参考,具体如下: DBSCAN:是一种简单的,基于密度的聚类算法。本次实现中,DBSCAN使用了基于中心的方法。在基于中心的方法中,每个数据点的密度通过对以该点为中心以边长为2*EPs的
-
SQL从聚合函数获取其他行
问题内容: 我有一个汇总函数,按(colA)进行分组。它从一组列(列B)中选择最大值,但我也想从同一行中的列(列C)中返回另一个值。但是,如果将3行分组,则从C列中选择第一个值,而不是最大值(MAX(colB))的列。 问题答案: 您将要使用一个子查询,该子查询将按每个子查询获取,然后将该值重新连接到表中,以返回与该子查询的值匹配的其余列: 参见带有演示的SQL Fiddle
-
Elasticsearch关键字以及小写和聚合
问题内容: 我以前用映射“关键字”存储了一些字段。但是,它们是区分大小写的。 为了解决这个问题,可以使用分析仪,例如 与映射 但是,按期进行汇总不起作用。 原因:java.lang.IllegalArgumentException:默认情况下,在文本字段上禁用Fielddata。在[a]上设置fielddata = true,以通过反转取反的索引将字段数据加载到内存中。请注意,这可能会占用大量内存
-
计算子聚合返回的存储桶
问题内容: 我需要计算管道聚合返回的结果集中的存储桶数。问题是我的查询在这里使用脚本选择器: 返回类似这样的内容: 在该键下,我可以看到一个满足我条件的访问者列表(由标识的每个访问者都必须在索引中恰好有三个文档),但这不是很有用,因为它可以处理成千上万的访问者。我正在使用PHP处理结果,从理论上讲,它可以计算结果集,但是对于大量的访问者来说,这并不是最好的主意。有没有一种方法可以仅在和旁边输出有效
-
 详解SQL Server的聚焦过滤索引
详解SQL Server的聚焦过滤索引本文向大家介绍详解SQL Server的聚焦过滤索引,包括了详解SQL Server的聚焦过滤索引的使用技巧和注意事项,需要的朋友参考一下 前言 这一节我们还是继续讲讲索引知识,前面我们聚集索引、非聚集索引以及覆盖索引等,在这其中还有一个过滤索引,通过索引过滤我们也能提高查询性能,简短的内容,深入的理解。 过滤索引,在查询条件上创建非聚集索引(1) 过滤索引是SQL 2008的新特性,被应用在表中