《2023届毕业生》专题
-
 应届生转行产品经理,2次大厂面试复盘上岸
应届生转行产品经理,2次大厂面试复盘上岸大厂面试过2次,虽然拿到了offer,但家人最终还是让我去上海发展,遗憾放弃 不过在面试过程中也大概率的知道,这些大厂在面试时更看重什么 综合2次面试复盘一下,希望能帮助到其他想拿offer的同学🍀 1、学习能力 通过三方面考察:看你大学专业排名(还有获得荣誉等),排名靠前的学习能力至少不会差。如果专业排名不行,你就需要通过别的事件去证明你的学习能力 还会询问你最近学到的新东西,看你的学习效果。
-
 应届生转行产品经理,2次大厂面试复盘上岸
应届生转行产品经理,2次大厂面试复盘上岸大厂面试过2次,虽然拿到了offer,但家人最终还是让我去上海发展,遗憾放弃 不过在面试过程中也大概率的知道,这些大厂在面试时更看重什么 综合2次面试复盘一下,希望能帮助到其他想拿offer的同学🍀 1、学习能力 通过三方面考察:看你大学专业排名(还有获得荣誉等),排名靠前的学习能力至少不会差。如果专业排名不行,你就需要通过别的事件去证明你的学习能力 还会询问你最近学到的新东西,看你的学习效果。
-
 B站-Web端视频播放器开发-应届生但社招二面
B站-Web端视频播放器开发-应届生但社招二面本着探路者先驱的意识,先给牛客的各位兄弟姐妹们探探路体验下社招的难度和校招有什么不同,给日后跳槽被裁员啥的做个准备。话不多说,面经奉上!! 一面在这:https://www.nowcoder.com/discuss/486499573251276800?sourceSSR=users CSS相关: 社招这么喜欢问CSS吗? CSS常见的布局,垂直居中的几种实现方式。 CSS有哪些属性具备硬件加速效
-
 B站-Web端视频播放器开发-应届生但社招一面
B站-Web端视频播放器开发-应届生但社招一面没错,是社招,懂得都懂,赶紧先体验下社招难度为半年后万一被裁做准备,就随便在B站投了简历没想到通过初筛直接约面了; 岗位JD: 以下为社招难度下的面试题: CSS相关: display可以设置哪些值,display:table通常用于什么场景下? position可以设置哪些值,默认是什么? display:none和visibility:hidden的区别?和opacity:0的区别 两种盒模型
-
使用CRON作业访问URL?
问题内容: 我有一个必须执行重复任务的Web应用程序,发送消息和警报,我已经使用脚本页面在浏览器中加载它们时执行了这些任务,即http://example.com/tasks.php,我已经在我的Web应用程序的每个页面中都使用iframe表示。 现在,我想将其更改为使用CRON作业,因为第一种方法可能会导致卡纸性能,因此,我如何制作访问http://example.com/tasks.php的C
-
制作商业Java软件(DRM)
问题内容: 我打算制作一些可以通过互联网出售的软件。我以前只是创建开放源代码,所以我真的不知道如何保护它免受warez的破坏和分发。考虑到我知道两个程序都没有被破解或没有真正的用处,所以我决定唯一或多或少可靠的方法可能是这样的: 连接到服务器并提供许可信息和某种硬件摘要信息 如果一切正常,服务器将返回绑定到该特定PC的程序的某些关键缺失部分,并规定2天的使用限制 关键内容不会保存到硬盘驱动器,因此
-
Jenkins EnvInject插件+管道作业
问题内容: 我想在管道作业中使用EnvInject插件。因此,我可以设置复选框“为运行准备一个环境”,但是 没有动作“注入环境变量”,就像在自由式作业中一样。我在“属性内容”块中声明了变量:在此处输入图片说明 如何使用EnvInject在管道作业中注入环境变量? 问题答案: 如果在“属性内容”块中声明了以下变量: 然后,您可以将它们放入管道中,以便:
-
熊猫每月滚动作业
问题内容: 我最终在写出这个问题的时候就弄清楚了,所以无论如何我都会发布并回答我自己的问题,以防别人需要一点帮助。 问题 假设我们有一个,包含该数据。 目标 对于每一行,将 其一个月*以内的每一行的总和相加,最好使用一种非常干净的语法。 * 我尝试过的 但这引发了异常 版: 问题答案: 使用偏移量而不是专门使用30天或大约一个月。 最初,我凭直觉跳了起来,使用了一个月,但现在很清楚为什么不起作用。
-
自动创建SQL Server作业
问题内容: 我正在编写SQL Server部署脚本,这些脚本会在特定的SQL Server服务器/实例上自动创建SQL Server作业。我发现可以通过将脚本作业用作=> Create To来提取可用于自动创建SQL Server作业的sql语句。 我的困惑是,我发现数据库名称和所有者帐户名称在生成的sql脚本中进行了硬编码。当我使用sqlcmd在另一台计算机上执行sql脚本以执行部署时,数据库名
-
列出所有Apache Kafka业务
本文向大家介绍列出所有Apache Kafka业务相关面试题,主要包含被问及列出所有Apache Kafka业务时的应答技巧和注意事项,需要的朋友参考一下 答:Apache Kafka的业务包括: 添加和删除Kafka主题 如何修改Kafka主题 如何关机 在Kafka集群之间镜像数据 找到消费者的位置 扩展您的Kafka群集 自动迁移数据 退出服务器 数据中心
-
Hystrix断路器,业务例外
有一种显而易见的方法可以将业务异常包装到holder对象中,从run()方法返回它,然后将其解包装回异常并重新抛出。但它想知道是否有更干净的方法。
-
从Kubernetes Cron作业调用endpoint
我有一个webapp在Kubernetes集群的Docker-container中运行。该应用程序有一个endpoint,我想定期调用。应用程序在多个节点/吊舱上运行,重要的是只有一个节点执行endpoint发起的任务。我查看了Kubernetes Cron作业,但没有找到任何关于从Kubernetes Cron作业调用endpoint的文档。有人对解决这个问题有什么建议吗?在只有一个节点执行任务
-
测试Quartz JDBC作业存储
现在我手动更改系统时间。例如,如果我将作业安排在2/5/2013 12:45 PM运行,那么我将系统时钟时间更改为2/5/2013 12:43 PM,然后等待几分钟,看看Quartz是否从DB接收到该作业。这对我很管用。 我不想每次需要测试时都更改系统时钟时间。有没有更好的办法做到这一点? 我注意到频繁地改变系统时间有时会使Quartz搞砸,因为有些工作没有被接上。
-
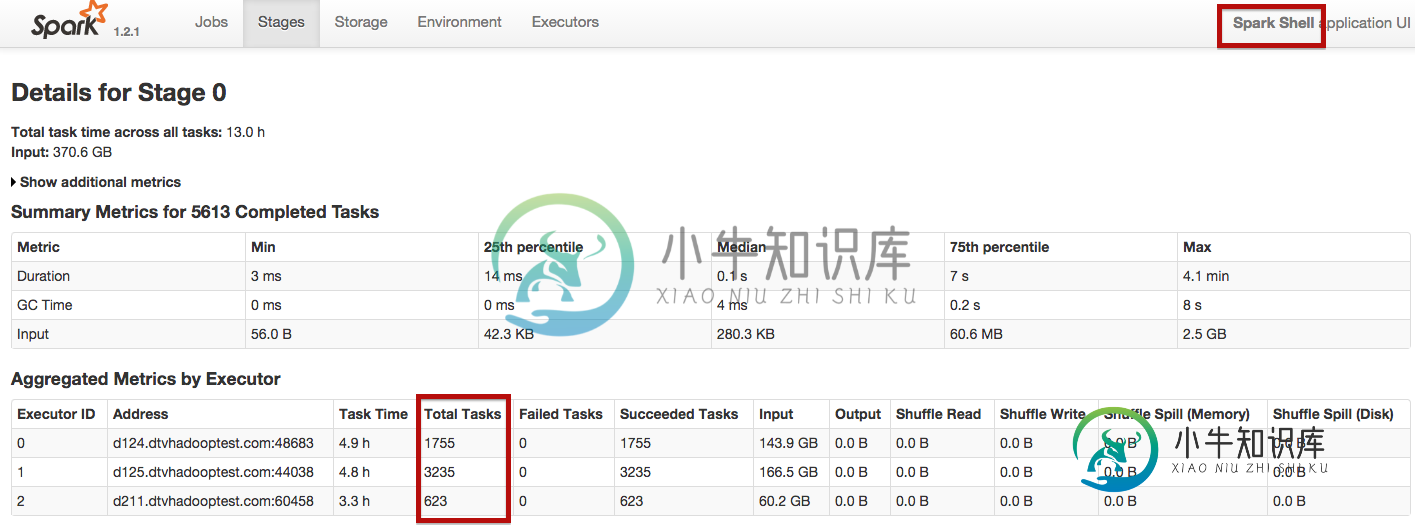 Python vs Scala(用于Spark作业)
Python vs Scala(用于Spark作业)我对Spark很陌生,目前正在通过玩pyspark和Spark-Shell来探索它。 现在的情况是,我用pyspark和Spark-Shell运行相同的spark作业。 这是来自Pyspark: 使用spark-shell,工作在25分钟内完成,使用pyspark大约55分钟。如何让Spark独立地用pyspark分配任务,就像它用Spark-shell分配任务一样?
-
动态作业调度石英
是否可以添加/删除/修改在Quartz Spring Boot中动态安排的作业(在运行时),由使用我的门户的最终用户。由于计划无法从外部访问,我不知道有什么办法。基本上,我需要将所有的时间表信息存储到数据库中并访问它们。Im构建的门户将被大量用户使用,实现这一目标的正确解决方案是什么? 否则我可以像下面这样使用cron吗 每5 mns扫描一次作业以实现此目的。