《2023届毕业生》专题
-
 七牛云 前端 一面 日常实习 2023-07-04
七牛云 前端 一面 日常实习 2023-07-041、项目是怎么做的(我简历的第一个项目是低代码) 2、选择pnpm做monorepo的原因是什么 3、硬链接什么,和软链接有什么区别 4、低代码中按钮的事件怎么处理的,单击双击长按,n连击 5、组件事件、组件之间的联动是怎么做的 6、自定义事件是怎么做的 7、选一个当时做的最复杂的点,详细说一下过程和解决方案(我调了el-dialog缩放全屏,再用js操作monaco调整大小的性能问题) 8、聊一
-
 2023华为暑期实习二面面经(主管面)
2023华为暑期实习二面面经(主管面)岗位:嵌入式软件开发工程师-数据通信产品线(东莞) 1.自我介绍 2.介绍一下项目 3.项目中最有成就感的地方 4.项目中最大的困难,怎么解决 5.对华为的了解 6.对于加班和工作强度大怎么看 7.有什么爱好 反问环节:会让实习生负责重要但不紧急的小项目,会有导师带;住宿方面不包住宿,附近有些员工小区,基本2000以下 总结:总时长25min,没有很刁钻的问题,全程聊得还挺开心,现在就等结果了 #
-
 2023前端暑期实习面试记录(凉凉ing)
2023前端暑期实习面试记录(凉凉ing)转产品前留下不完整面经,希望给继续在前端方向奋斗的同志们一点点帮助。 虽然我是个没本事的人但希望你们能做到(哽咽) 美团(两次被捞,都在初面挂了) 外卖(第一次 初面) 先简单介绍了部门工作,让我自我介绍,然后主要是根据简历上的项目挖掘知识点 大概问到了这些: · 项目中遇到的困难(提到了跨域) · 跨域的几种方式(答得不算好,只提到了jsonp、nginx、webpack的代理、cors,典型的
-
 2023暑期实习-笔试-美的-数据分析类
2023暑期实习-笔试-美的-数据分析类公司:美的 岗位:数据分析类 笔试平台:牛客 考试时长:90分钟 试卷总分:100分 考试题型:单选 10 道(20分),不定项选择 5 道(20分),编程 3 道(15分+20分+25分) 时间:长期有效 单选题 SQL、概率统计、数学运算 不定项选择 SQL、概率统计、机器学习、数据思维 编程题 排序 订单表tbl_order(orderid, userid, orderdate, pid,
-
 2023春招-面试-杉树科技-数据分析师
2023春招-面试-杉树科技-数据分析师公司:杉树科技 岗位:数据分析师 形式:视频面试 视频面试平台:腾讯会议 面试官:数据分析师、HR 时长:25分钟 流程: 数据分析师(16分钟) 1、自我介绍 2、具体描述一下之前的实习经历,特别是数据分析这一块,比如遇到了哪些问题、有什么分析逻辑、如何去解决问题。 3、深挖项目:在这些工作中有没有得到什么有意思的结论? 4、继续深挖项目。 5、对机器学习大概有一个什么程度的了解? 6、解释一下
-
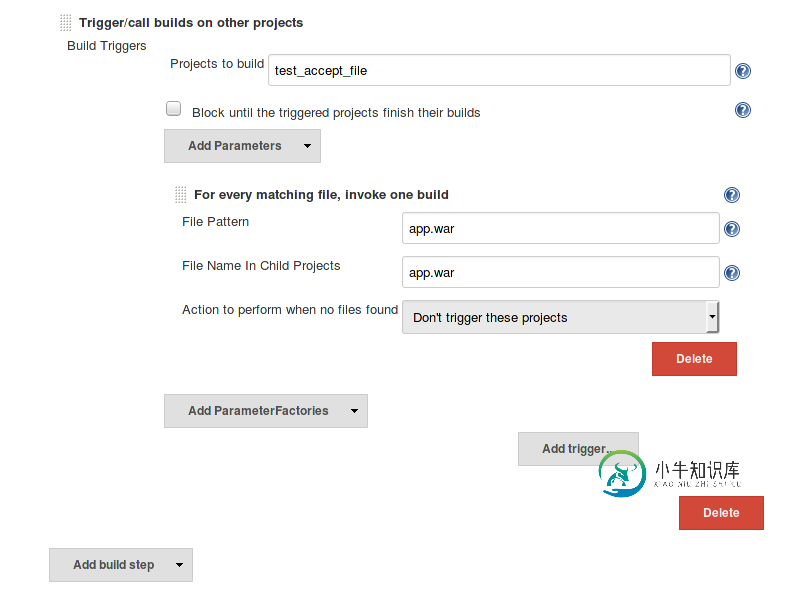 如何将文件传递到阻止上游作业的下游作业?
如何将文件传递到阻止上游作业的下游作业?问题内容: 我要完成的工作是从分支中签出代码,将其合并到分支,构建,运行测试,如果测试成功则推送到分支。 测试应在需要的单独工作中运行。 我当前的设置如下: Job 从中检出,将其合并并构建 作业会在“ 后期制作”步骤中 触发作业(需要预先创建) 如果成功,则在 发布构建操作中推送到分支 __ 我尝试使用 Copy Artifact Plugin, 但是问题在于,在 Post构建步骤中 触发时,我
-
是否可以将Jenkins自由式作业转换为多配置作业?
问题内容: 我在詹金斯(Jenkins)有很多自由式工作,我想转换为多配置工作,这样我就可以在一项工作下跨多个平台进行构建。这些作业指定了很多构建参数,我不想通过创建新的多配置作业来再次手动设置它们。当前,每个作业都将其构建限制为我们一直在构建的平台,而我看到的唯一其他选择是克隆现有作业,并将限制更改为新平台。这不是理想的选择,因为我需要维护2个工作,其中唯一的区别是目标平台。 我没有看到通过UI
-
Jenkins executor忙-加载条作业,但没有链接或id-幽灵作业
Jenkins重启后,我们发现很少有节点执行器繁忙。占据executor的作业有条带的蓝白加载条,并且没有链接到任何特定的构建(事实上,该作业没有正在进行的构建)。所以我们没有id或ui方式来中止它,您可以在这里看到: 詹金斯节点上的工作是什么样子的 现在,我想找到一种方法,在不真正调查问题原因的情况下杀死它,也许它与Jenkins管道作业相关,不会在UI中完成——但在我们的情况下,我们没有基本的
-
Spring Batch Admin现有作业在新作业注册后不再可启动
目前,由于一个我无法解决的问题,我一直在将Spring Batch Admin(SBA)集成到我们的项目中。希望有人能给我一个建议。 我们使用了示例SBA应用程序(Github的当前版本),只添加了一个Tasklet。我通过/job配置上传Spring批处理描述(XMLs)。SBA的json API使用。这工作正常。在SBA的HTML页面中,我看到该作业已注册并可启动。它可以通过API(/jobs
-
Azure Web作业未启动并始终给出“未找到作业功能”
我正在尝试使用触发器运行Azure网络作业,但我的时间作业方法没有触发。我收到了下面的消息。 未找到工作职能。尝试将您的作业类和方法公开化。如果您正在使用绑定扩展(例如ServiceBus、定时器等。)确保您已经在启动代码中调用了扩展的注册方法(例如config。UseServiceBus()、config。使用定时器()等。). 我正在使用配置。UseTimers() 但仍显示消息。不确定以下代
-
在Jenkins中将作业A的工作空间url传递给作业B
我有两个管道作业作业作业A和作业B。我需要通过作业A的工作空间url(比如 /var/lib/jenkins/workspace/JobA)被作业B使用。主要的想法是我试图复制由于maven构建而生成的目标文件夹的内容,但我不想使用复制工件插件或存档工件插件来实现同样的目的。 我尝试过使用“此作业已参数化”选项,其中作业A是作业B的上游,但我无法使用该选项。 有人能帮助实现同样的目标吗?
-
如何在作业结束时运行脚本,即使作业被取消?
这是我目前在GitHub上使用的工作流程 我有一台windows 10计算机,它使用GitHub runner监听传入的作业。在传入作业时,如果正在向主分支推送脚本ci_主机。py使用“--master”标志运行,该标志会启动一个VM并对其运行多个测试。最终,在测试结束时,脚本将VM恢复到预先配置的快照。 因此,基本上我试图实现的是,当通过GitHub操作web界面取消作业时,处理测试的脚本在作业
-
如何从数据流作业内部获取数据流作业 ID - JAVA
在我当前的架构中,多个数据流作业在不同阶段被触发,作为ABC框架的一部分,我需要捕获这些作业的作业id作为数据流管道中的审计指标,并在BigQuery中更新它。 如何使用JAVA从管道中获取数据流作业的运行id?有没有我可以使用的现有方法,或者我是否需要在管道中使用google cloud的客户端库?
-
如何使一个石英作业创建另一个作业后执行?
我想用Quartz实现下面的算法,但不确定是否可以做到。这是我第一次尝试使用石英。 用户通知作业-此作业计算每月报告并向用户发送电子邮件,它需要用户id和用于生成自定义用户报告的其他参数 可能需要生成10,000多个这样的报告 null 如何确保每月作业在单个事务中执行,以便识别所有需要每月报告的用户,并安排作业通知他们 如何立即安排作业在创建它们的作业之后立即执行? 我用的是Spring 3.2
-
部署 Seafile 专业版服务器 - 从社区版迁移至专业版
限制条件" class="reference-link">限制条件 您可能已经部署过 Seafile 社区版服务器,并想要切换到专业版,或者反过来从专业版迁移到社区版。但是有一些限制条件需要您注意: 您只能在相同大版本的社区版服务器和专业版服务器之间进行切换。 这意味着,如果您正在使用 2.0 版本的社区版服务器, 并且想要切换到 2.1 版本的专业版服务器,您必须先将您的社区版服务器升级到 2.