
Python vs Scala(用于Spark作业)

我对Spark很陌生,目前正在通过玩pyspark和Spark-Shell来探索它。
现在的情况是,我用pyspark和Spark-Shell运行相同的spark作业。
这是来自Pyspark:
textfile = sc.textFile('/var/log_samples/mini_log_2')
textfile.count()
textfile = sc.textFile("file:///var/log_samples/mini_log_2")
textfile.count()
使用spark-shell,工作在25分钟内完成,使用pyspark大约55分钟。如何让Spark独立地用pyspark分配任务,就像它用Spark-shell分配任务一样?
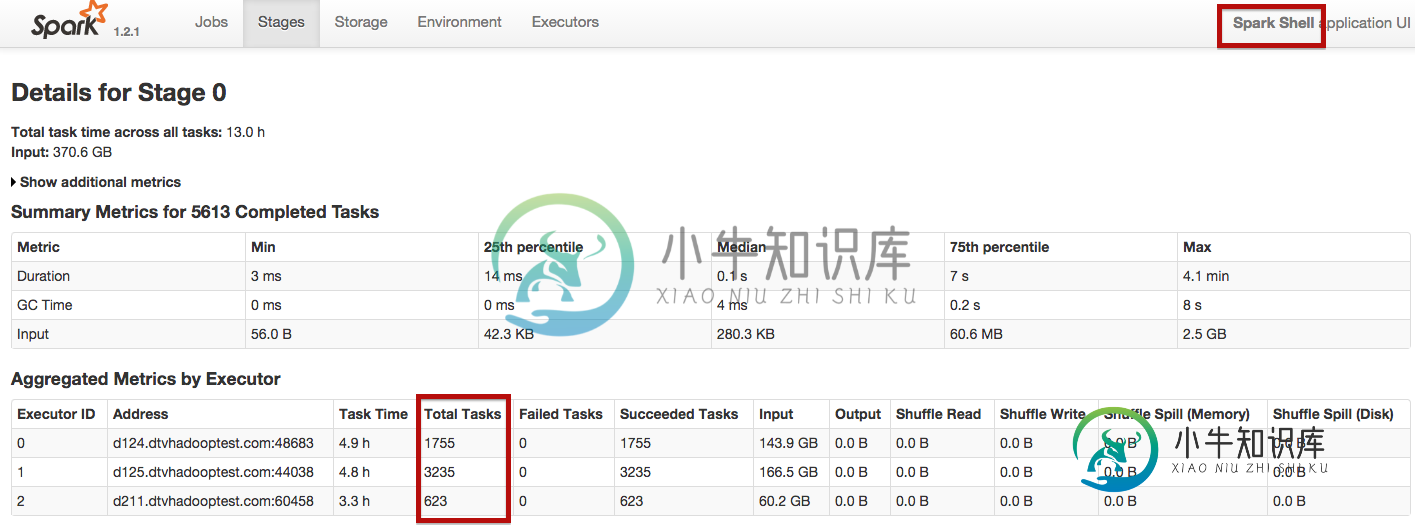
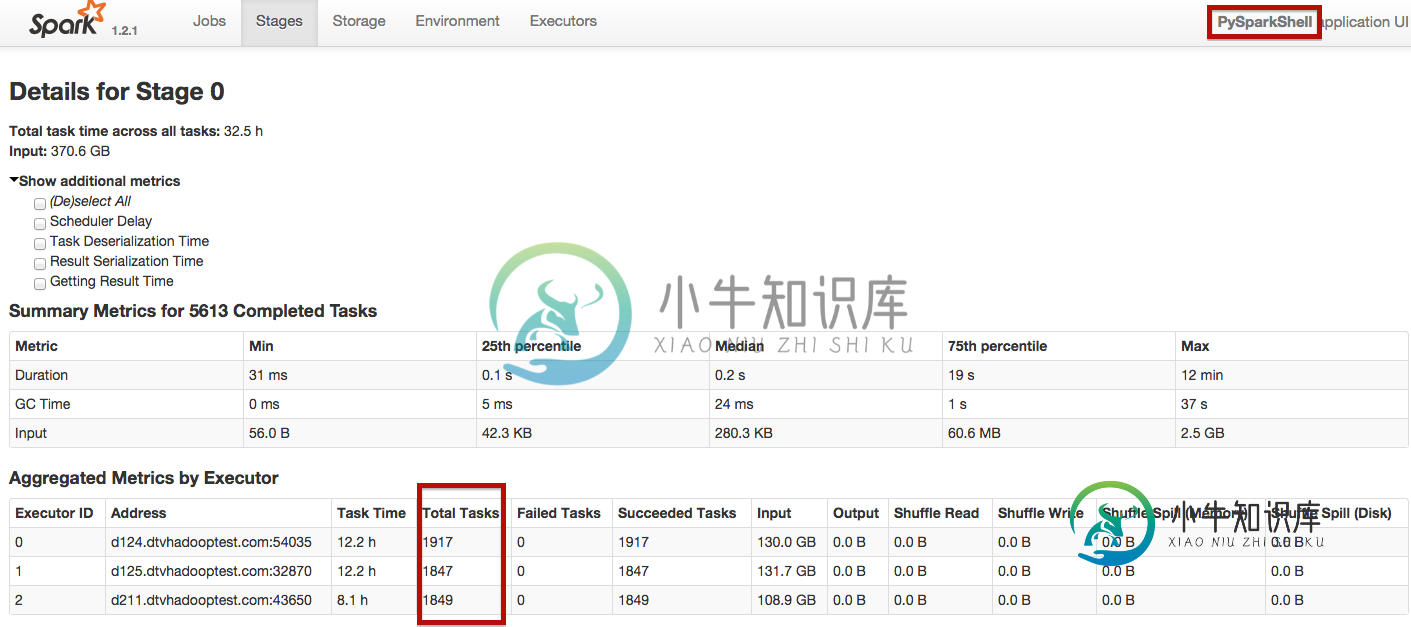
共有1个答案

使用python有一些开销,但它的重要性取决于您正在做什么。尽管最近的报告表明开销不是很大(特别是对于新的DataFrame API)
您遇到的一些开销与每个工作开销的常数有关--这对于大型工作几乎不相关。您应该使用更大的数据集进行示例基准测试,看看开销是不变的,还是与数据大小成正比。
另一个潜在的瓶颈是为每个元素(map等)应用python函数的操作--如果这些操作与您相关,您也应该测试它们。
-
我试图运行火花作业,基本上加载数据在卡桑德拉表。但它也产生了以下错误。
-
是的...已经讨论了很多了。 但是,有很多不明确的地方,提供了一些答案...包括在jars/executor/driver配置或选项中重复jar引用。 类路径的影响 驱动程序 执行程序(用于正在运行的任务) 两者 一点也不 对于任务(对每个执行者) 用于远程驱动程序(如果在群集模式下运行) 方法 方法 或 或 不要忘记,spark-submit的最后一个参数也是一个.jar文件。 如果我从文档中猜
-
18:02:55,271错误UTILS:91-中止任务java.lang.nullpointerException在org.apache.spark.sql.catalyst.expressions.generatedClass$GeneratedIterator.agg_doAggregateWithKeys$(未知源)在org.apache.spark.sql.catalyst.express
-
问题内容: 我尝试使用Spark 1.1.0提供的新的TFIDF算法。我正在用Java写MLLib的工作,但我不知道如何使TFIDF实现有效。由于某种原因,IDFModel仅接受JavaRDD作为方法转换的输入,而不接受简单的Vector。 如何使用给定的类为我的LabledPoints建模TFIDF向量? 注意:文档行的格式为[标签; 文本] 到目前为止,这里是我的代码: *肖恩·欧文(Sean
-
我有一个在AWS EC2机器上运行的HortonWorks集群,我想在上面运行一个使用spark streaming的spark工作,该工作将吞下tweet concernings《权力的游戏》。在尝试在集群上运行它之前,我确实在本地运行了它。代码正在工作,如下所示: 我的问题更确切地说是关于这段特定代码行: 17/07/24 11:53:42 INFO AppClient$ClientEndpo
-
完全错误: 线程“main”java.lang.nosuchmethoderror:scala.predef$.refarrayops([ljava/lang/object;)[ljava/lang/object;)[ljava/lang/object;;在org.spark_module.sparkmodule$.main(sparkmodule.scala:62)在org.spark_modu