《面试题目》专题
-
 短视频业务数据指标体系面试题与解析 1
短视频业务数据指标体系面试题与解析 1面试高频题1: 题目:短视频业务中有哪些常用指标? 答案解析: 对内容产品来说,第一步就是“有内容”,即内容的生产环节。 不同的内容产品为我们提供了不同的选择,抖音快手的产品类型是短视频,知乎的“产品”是问题,微博的产品是动态,腾讯优酷的产品是电视剧电影。但不论产品的形态如何多变,在观察指标时,都可以考虑从在线、新增、原创、精品、违规等几个指标监控内容产品的丰富度、热度与质量。比如某平台在推广过程
-
 短视频业务数据指标体系面试题与解析2
短视频业务数据指标体系面试题与解析2面试高频题4: 题目:怎么衡量你在业务部门的贡献 业务部门是数据分析师分析所服务的相关方,包括产品、运营等 答案解析: 能否驱动业务提供方向和结论,并有明显业务效益的提升 能否理解业务并提供专业的意见,从而解决了业务方的一些难题 能否对业务充分理解,并能高效做出取数和数据报表等操作,提升业务方效率 拿日常工作详细举例: 比起零散的跑数据,提供有效的数据报表更有效一些 能有一些数据可视化的展示,比纯
-
 拿到offer啦!设计岗面试前请背下这10个问题!
拿到offer啦!设计岗面试前请背下这10个问题!都说今年将是互联网的至暗时刻,很多同学反馈面试难。好不容易接到面试通知,有些1面就挂了,或者是卡在2/3面,就是不发Offer。甚至许多大厂设计师在被毕业后,也面临找工作难的问题。 我今年参与了10余场面试,成功拿下了4家大厂的Offer,并拿到了超预期的涨幅💰💰。其实就是靠着我在面试准备和总结上投入的大量精力和时间‼️并且我发现大部分公司有70%以上的问题都是类似的。今天就给大家整理了一下这
-
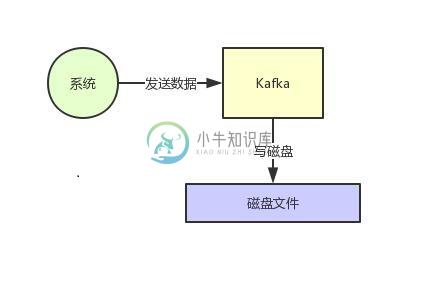 字节面试题: 如何让一个MQ抗住几十万并发?
字节面试题: 如何让一个MQ抗住几十万并发?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁
-
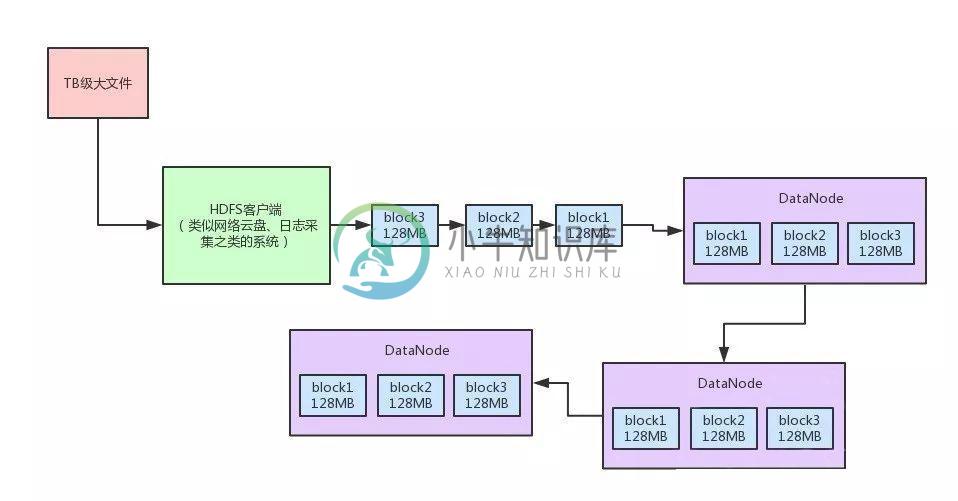 大厂面试题: TB级文件上传该怎么优化性能?
大厂面试题: TB级文件上传该怎么优化性能?主要内容:一、写在前面,二、原始的文件上传方案,三、HDFS对大文件上传的性能优化,1. Chunk缓冲机制,2. Packet数据包机制,3. 内存队列异步发送机制,四、总结一、写在前面 上一篇文章,我们聊了一下Hadoop中的NameNode里的edits log写机制。 主要分析了edits log写入磁盘和网络的时候,是如何通过分段加锁以及双缓冲的机制,大幅度提升了多线程并发写edits log的吞吐量,从而支持高并发的访问。 如果没看那篇文章的同学,可以回看一下:《放几十亿数据的系统还
-
 运营面试题 如何识别和处理劣质视频内容?
运营面试题 如何识别和处理劣质视频内容?1.问题定义:何为低质视频? 2.问题拆解: 1)封面(模糊,密恐,低俗涉性等)2)标题(标题党,劣质标题等) 3)内容(无意义,广告,时效性差,劣质二拆等) 3.低质识别(机器+人工) 1)用户维度:识别同类低质作者2)内容维度(模型为主) 4.打压策略 根据低质的影响面,对用户体感的伤害程度。按照轻度,中度,重度,分发侧分别进行降权,过滤,封禁等策略。作者侧通过复审进行作者维度的生态控制。 5
-
 产品高频面试题解析:「请你介绍一下XX经历」
产品高频面试题解析:「请你介绍一下XX经历」魔术师刘谦曾经说过一句话:“很多人,包括职业魔术师,都误会魔术表演了。魔术的真正魅力倒不是偷梁换柱的那一刹那,而是整个魔术表演从开始气氛铺垫,到最后极具张力的释放整个起承转合的排演和演绎。简而言之,魔术师首先不是要会变,而是要会演。” 面试不是一场你问我答的考试,而是一场证明能力与岗位要求匹配的个人表演。 面试官的每个问题都是在考察面试者的不同能力,确定面试者是否匹配要求。 面试时不要着急回答问题
-
 记录一下金蝶 产品设计岗位面试问的问题
记录一下金蝶 产品设计岗位面试问的问题面试全程30分钟左右 1. 自我介绍 2. 研究生做过的科研项目说一下做了什么,怎么做的。(因为我自我介绍的时候说我虽然我没有相关实习经验,但是感觉我搞科研产出的过程和产品设计的过程很像,底层逻辑是相似的。) 3. 个人的优缺点 4. 个人的爱好。我说到了刷小红书 所以又问了我对小红书的看法的评价。 5. 接受加班吗,怎么看待? 6. 有参加一些非科研项目吗?负责啥的?团队沟通能力? 7. 有了解
-
 数据分析面试题|如何提升app的用户参与度
数据分析面试题|如何提升app的用户参与度******************* 春招保驾护航! 参考回答: - 第一步:定义指标。几乎所有的产品案例研究都从一个模糊的目标开始,第一步是将此目标转化为可以优化的指标。 比如。 "我将小红书上用户的参与度定义为每天至少采取一项行动的用户比例,其中行动意味着与网站互动,即发布、喜欢、上传图片等" 。 - 在指标确定之后,选择我们认为对该指标起到影响的变量特征。比如用户特
-
 腾讯网易米哈游,各游戏厂面试真题大公开
腾讯网易米哈游,各游戏厂面试真题大公开今年春招我们帮助了多位同学顺利拿到大厂offer,在秋招面试之际,我们整理了同学们的面试题,仅供大家参考!! 同学们可以对照面试题默默给出自己的答案,整理一下回答,打一场有准备的仗喔! 小H同学--腾讯IEG--社区运营 面经 说一个你经常玩的游戏,哪些吸引你的点,哪些可以改进? 怎么样才能让玩家不拘泥于一款中国年限定呢?也就是说都买。 谈一谈印象深刻的商业化活动,不限制游戏。 (根据各个工作室的
-
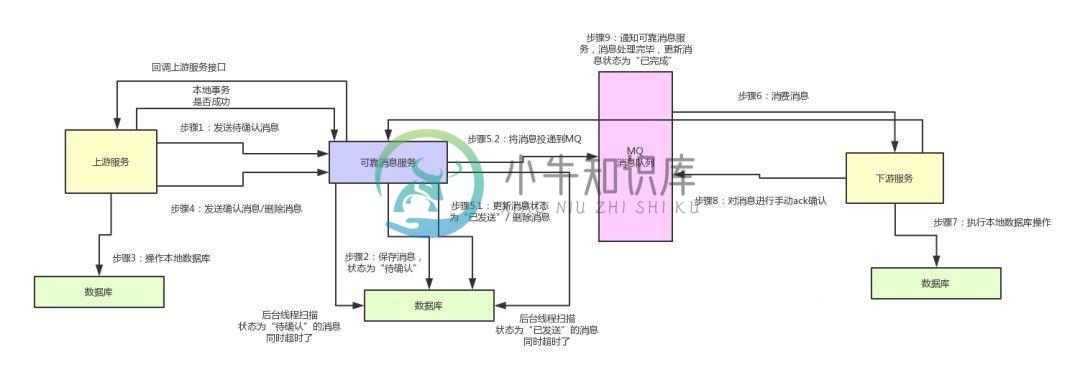 阿里面试问题:分布式事务如何实现高可用?
阿里面试问题:分布式事务如何实现高可用?主要内容:一、写在前面,二、可靠消息最终一致性方案的核心流程,三、可靠消息最终一致性方案的高可用保障生产实践一、写在前面 上一篇文章咱们聊了聊TCC分布式事务,对于常见的微服务系统,大部分接口调用是同步的,也就是一个服务直接调用另外一个服务的接口。 这个时候,用TCC分布式事务方案来保证各个接口的调用,要么一起成功,要么一起回滚,是比较合适的。 但是在实际系统的开发过程中,可能服务间的调用是异步的。 也就是说,一个服务发送一个消息给MQ,即消息中间件,比如RocketMQ、RabbitMQ、Ka
-
 设计师不知道怎么回答面试官问题,看这里
设计师不知道怎么回答面试官问题,看这里设计师不知道怎么正确回答面试官问题?正确回答的方法来了,建议先收藏再看。 1、你为什么选择我们公司 这就需要在面试之前先了解一下这个公司,了解他们是做什么的,然后说很看好这个业务未来的发展、很喜欢这个领域之类的 2、你了解哪些设计理论 格式塔、交互五要素、less is more、故事逻辑、用户分层、情绪版、原子理论等,根据自己的真实情况回答,不要不懂装懂。 3、你认为我们的产品有哪些问题 面试前
-
 《机器学习高频面试题详解》1.3:L1和L2正则化
《机器学习高频面试题详解》1.3:L1和L2正则化前言 大家好,我是鬼仔,今天带来《机器学习高频面试题详解》专栏的第1.3节:L1和L2正则化。这是鬼仔第一次开设专栏,每篇文章鬼仔都会用心认真编写,希望能将每个知识点讲透、讲深,帮助同学们系统性地学习和掌握机器学习中的基础知识,希望大家能多多支持鬼仔的专栏~ 目前这篇是试读,后续的文章需要订阅才能查看哦(每周一更/两更),专栏预计更新30篇文章(只增不减),具体内容可以看专栏介绍,大家的支持是鬼仔
-
 美团面试题:如何提升美团外卖拼单成功率?
美团面试题:如何提升美团外卖拼单成功率?#运营人求职交流聚集地# 外卖参与方:商家;用户;骑手;平台。 思考:拼单成功率=拼单成功用户/总用户 拼单成功率低的原因可能是: 没有足够用户进行拼单(时间,品类,距离等因素);没有骑手接单;想拼的店没有开通拼单功能;不知道可以拼单。 拼单优点:快和便宜。所以画像一般是图便宜的同学和上班族白领。 运营角度提升: 1、平台:降低拼单门槛要求,改变拼单规则(比如可以跨品类拼);拼单产品位往前挪,用户
-
 【这才是重量级框架】大数据开发面试题【Spark篇】
【这才是重量级框架】大数据开发面试题【Spark篇】115、Spark的任务执行流程 driver和executor,结构式一主多从模式,driver:spark的驱动节点,用于执行spark任务中的main方法,负责实际代码的执行工作;主要负责:将代码逻辑转换为任务、在executor之间调度任务、跟踪executor的执行情况。 Executor:spark的执行节点,是jvm的一个进程,负责在spark作业中运行具体的任务,任务之间相互独立,