《猫眼》专题
-
如何停止在csv文件末尾写空行-熊猫
当保存数据到csv,,它会在csv文件的末尾创建一个空行。 你如何避免这种情况? 它与有关,它的默认值是,用于新行。 有没有办法指定以避免在最后创建空行,或者我需要读取csv文件,删除空行并保存它? 不熟悉熊猫。我们将感谢您的帮助,提前感谢!
-
如何在熊猫[重复]中展开带括号的列
我有4个值数据作为函数的输出。这是我的数据 这是我想要的
-
Java 版本, 雄猫, 不支持的主要.minor 版本 52.0
我正在开发一个应用程序,我用Java和Jersey构建了后端部分,它托管在我的服务器上。我在服务器上使用Tomcat7来调用web服务。 我以前有一台带有Ubuntu的计算机,我曾经将我的项目导出到战争文件,将其放在Tomcat文件夹中,然后它就可以工作了。我现在将我的电脑改成了Mac,我有完全相同的Java项目,当我在电脑上本地运行它时,它就可以工作。但是当我以与以前相同的方式将其上传到服务器时
-
如何用熊猫删除数据集中的列?[副本]
现在我正在上一门机器学习课程。现在我应该导入我的数据集之后,我读了一个“CSV”文件导入我的数据集,我想删除一个列,但我不知道如何做。
-
pyspark将一列拆分为多个列而没有熊猫
我的问题是如何将一列拆分为多个列。我不知道为什么 不起作用。 例如,我想将“df_test”更改为“df_test2”。我看到了很多使用熊猫模块的例子。还有别的办法吗?提前感谢您。 df_test2
-
 猫头鹰和DL推理:厄洛斯为什么不美?
猫头鹰和DL推理:厄洛斯为什么不美?我创建了一个基于以下内容的本体论: > 每个人都是美丽的,如果他/她的父母之一是美丽的 阿佛洛狄忒是厄洛斯的父母 因此,我们希望爱神也是美丽的!然而,弹丸推理者似乎并不是这样推断的。如果我手动将爱神的类型置为successful的话,它会接受它,但它难道不应该推断它吗? 我的本体论就在这里(将扩展改为.owl)。我还提供了来自Protege的截图: 我错过了什么? 编辑: 我可以看到Eros出现在
-
使用用户定义的函数声明熊猫系列
我试图用函数简化一些代码。目的是使用该函数声明空白序列,以便以后填充。 代码当前在单独的一行上声明每个系列,如下所示: 这种方法工作得很好,但对于许多系列,代码会很长。 我想做以下几点: 然而,当我试图声明series_列表时,它返回NameError:[variable]未定义。有没有办法用空对象(即没有数据,但名称为series1、series2、series1000)填充series_列表?
-
 阿里巴巴 天猫国际 一面 (电话面试40min)
阿里巴巴 天猫国际 一面 (电话面试40min)自我介绍 介绍项目 介绍一下Web Worker 响应式适配 为什么用tailwind,tailwind的特性 什么是跨域,怎么解决 哪些跨域方式支持post请求 vite为什么启动很快 协作方式,git流程,rebase和merge的区别,rebase的缺点/风险 项目首页优化方式,网络层面有什么优化方法 浏览器缓存机制 HTTP 2.0 HTTP 和 HTTPS 的区别 hooks和class
-
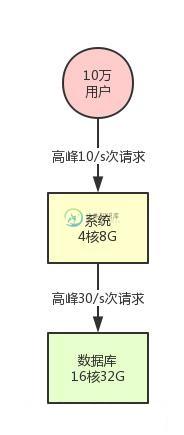 天猫双11高并发架构是怎么设计的?
天猫双11高并发架构是怎么设计的?主要内容:一、背景引入,二、先考虑一个最简单的系统架构,三、系统集群化部署,四、数据库分库分表 + 读写分离,五、缓存集群引入,六、引入消息中间件集群,七、现在能hold住高并发面试题了吗?,八、本文能带给你什么启发?一、背景引入 这篇文章,我们聊聊大量同学问我的一个问题,面试的时候被问到一个让人特别手足无措的问题:你的系统如何支撑高并发? 大多数同学被问到这个问题压根儿没什么思路去回答,不知道从什么地方说起,其实本质就是没经历过一些真正有高并发系统的锤炼罢了。 因为没有过相关的项目经历,所以就
-
Python 3熊猫错误:熊猫。解析器。CParserError:标记数据时出错。C错误:第5行预期有11个字段,saw 13
我检查了这个答案,因为我有一个类似的问题。 Python在标记数据时出错 然而,由于某种原因,我的所有行都被跳过了。 我的代码很简单: 我得到的错误是:
-
Python-检测并排除熊猫数据框中的异常值
问题内容: 我有一个只有几列的熊猫数据框。 现在我知道某些行是基于某个列值的离群值。 例如 “ Vol”列的所有值都在周围,12xx而一个值是4000(离群值)。 现在,我想排除具有Vol此类列的行。 因此,从本质上讲,我需要在数据帧上放置一个过滤器,以便我们选择某一列的值在均值例如3个标准差以内的所有行。 有什么优雅的方法可以做到这一点? 问题答案: 如果你的数据框中有多个列,并且希望删除至少一
-
Python-通过字典有效替换熊猫系列中的值
问题内容: 如何通过字典替换熊猫系列中的值已被询问并多次提出。 推荐的方法是要么使用,有时也使用如果所有的系列值是在字典键找到。 但是,使用性能的速度通常不合理,通常比简单的列表理解速度慢倍。 替代方法具有良好的性能,但是仅当在字典中找到所有键时才建议使用。 为什么这么慢,如何提高性能? 注意:此问题未标记为重复问题,因为它正在寻找有关在给定不同数据集的情况下何时使用不同方法的具体建议。这在答案中
-
Python-使用pd.eval()在熊猫中进行动态表达评估
问题内容: 给定两个数据框 我想使用对一列或多列进行算术运算pd.eval。具体来说,我想移植以下代码: …使用进行编码eval。使用的原因eval是我想自动执行许多工作流程,因此动态创建它们对我很有用。 我试图更好地理解和参数,以确定如何最好地解决我的问题。我已经浏览了文档,但是对我而言,区别并不明显。 应该使用什么参数来确保我的代码以最高性能工作? 有没有一种方法可以将表达式的结果赋值给df2
-
Python-通过熊猫DataFrame分组并选择最常用的值
问题内容: 我有一个包含三个字符串列的数据框。我知道第三列中的唯一一个值对于前两个的每种组合都有效。为了清理数据,我必须按前两列按数据帧分组,并为每种组合选择第三列的最常用值。 我的代码: 最后一行代码不起作用,它显示“ Key error’Short name’”,如果我尝试仅按城市分组,则会收到AssertionError。我该如何解决? 问题答案: 你可以用来获取计数系列,并获取第一行:
-
如何将熊猫系列或索引转换为Numpy数组?
问题内容: 您是否知道如何以NumPy数组或python列表的形式获取DataFrame的索引或列? 问题答案: 要获取NumPy数组,应使用以下属性: 这样可以访问数据的存储方式,因此无需进行转换。 注意:此属性也可用于其他许多熊猫的对象。 要将索引作为列表获取,请致电: 同样,对于列。