《猫眼》专题
-
组合熊猫中的多个数据列
我有下面的数据框- 我需要一个全新的数据帧,,有3列:1.0、2.0(结合2.0和4.0)和3.0(结合3.0和5.0)。 结果将是- 您可以预期合并列中不会有重叠的值;如果一行中的一列具有有效值,那么其他列将具有NaN值。 我试过了- 而且它并没有按预期的那样工作。有没有简单有效的方法来做到这一点?
-
熊猫:根据阈值条件删除列
我必须解决这个问题:目标:删除大多数行缺少输入的列:1。数据帧df:数据帧2。阈值:确定将删除哪些列。如果阈值为.9,则缺少90%值的列将被丢弃:1。带删除列的数据帧df(如果未删除任何列,则返回相同的数据帧) Excel文档截图 我编码了这个: 我必须有“自我、博士和阈值”,不能添加更多。代码必须通过下面的测试用例: 当我运行VT.drop_nan_col(df,0.9). head()时,我不
-
熊猫Groupby列,并获得0的频率
我有一个数据帧,我想按Col1 Col2 Col3分组,得到值列的0频率:df= 我如何应用groupby来实现 非常感谢。
-
在熊猫中获得今天的约会
这应该是从pandas的文档中进行的简单查找,但我失败了。如何在pandas的 本来应该给我想要的结果,但现在我得到了时间,这意味着下面的计算结果总是:
-
按id集更新多个文档。猫鼬
我想知道mongoose是否有一些方法可以通过id集更新多个文档。例如: 我想知道的是,如果猫鼬能做这样的事情: 其中,ids是一个id数组,如['id1','id2','id3']-示例数组。对于find,同样的问题。
-
熊猫数据框用NaN替换空白
我有一个空单元格的数据框,并希望用NaN替换这些空单元格。之前在这个论坛上提出的解决方案有效,但前提是单元格包含一个空间: 当单元格为空时,此代码不起作用。有人建议用熊猫代码来代替空细胞吗?
-
熊猫获得列平均值/平均值
我不能得到熊猫的平均值或平均值。有一个数据框。下面我尝试的东西都没有给我列的平均值 以下内容返回多个值,而不是一个值: 这也是:
-
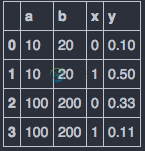 用条件列绘制熊猫数据帧
用条件列绘制熊猫数据帧我有这种熊猫。数据框。“a”、“b”是获得“x”和“y”时的条件。 我需要绘制关于相同条件的(x,y)结肠的折线图。预期结果图为: 当然,这个图像是由以下代码手动给出的: 我的问题是,当获得一个包含条件列x和y的数据帧时,如何动态地绘制如上所述的图。 列名是固定的。但是,条件列的值是动态更改的。因此,我不能使用10、20、100、200的值。 如果我有下面的“用a和b过滤”方法,我认为问题解决了:
-
在某种条件下给熊猫降排
我有一个ID列表和一个数据框,其中一列是ID。我想删除数据框中ID不是ID列表中ID之一的所有行。这是我使用的代码: 但是我得到这个错误消息: 值错误:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all()。 我做错了什么?
-
熊猫中的自定义布尔过滤?
我有一个数据帧 是否有某种自定义筛选方法,可以让Python知道 说我要过滤,
-
云铸造404但本地雄猫没事
首先让我们先把代码拿出来。 很奇怪。此外,链接站点中的一些建议将本地apache deployemtn破坏到服务器将关闭的位置。只是看看是否有人有任何洞察力,因为我找不到任何好的数据,当搜索云铸造404。
-
动态评估熊猫的公式表达?
...使用进行编码。使用的原因是我想要自动化许多工作流,因此动态地创建它们对我会很有用。 我的两个输入数据流是: 我试图更好地理解的和参数,以确定如何最好地解决我的问题。我已经看过了文件,但我并不清楚其中的区别。 应使用哪些参数来确保代码以最大性能工作? 是否有方法将表达式的结果赋回到? 另外,为了使事情更加复杂,如何将作为字符串表达式中的参数传递?
-
熊猫:具有重复索引的海螺
我试图做为。具有和其他在中具有。这是我的代码: 我得到这个错误: 什么,我哪里做错了?
-
使用熊猫的“大数据”工作流
在学习熊猫的过程中,我已经尝试了好几个月来找出这个问题的答案。我在日常工作中使用SAS,这是非常好的,因为它提供了非核心支持。然而,SAS作为一个软件是可怕的,原因还有很多。 有一天,我希望用python和pandas取代SAS的使用,但我目前缺乏大型数据集的核心外工作流。我说的不是需要分布式网络的“大数据”,而是文件太大而无法放入内存,但又太小而无法装入硬盘。 我的第一个想法是使用将大型数据集保
-
已安装熊猫,但仍无法导入
我已经用和python3.7安装了它,但是当我尝试导入pandas并运行代码时,会出现错误。 Traceback(最近一次调用最后一次):文件/用户/芭比/Python/测试/test.py,第1行,在导入熊猫为pd ModuleNotFoundError:没有名为'熊猫'的模块 如果我尝试再次安装...它说这个。 已满足pip3安装pandas要求:已满足pandas in/usr/local/