
用条件列绘制熊猫数据帧

我有这种熊猫。数据框。“a”、“b”是获得“x”和“y”时的条件。
df = pd.DataFrame([[10,20,0,.1], [10,20,1,.5], [100,200,0,.33], [100,200,1,.11]], columns=["a", "b", "x", "y"])
df
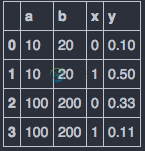
我需要绘制关于相同条件的(x,y)结肠的折线图。预期结果图为:
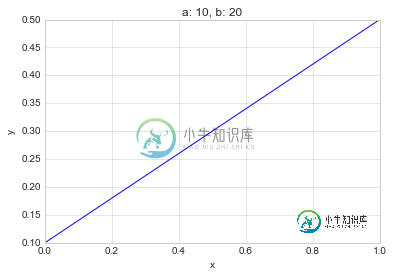
当然,这个图像是由以下代码手动给出的:
pd.DataFrame([[0,.1],[1,.5]]).plot(kind="line", x=0, y=1, style="-", legend=None, title="a: 10, b: 20")
plt.xlabel("x")
plt.ylabel("y")
plt.figure()
pd.DataFrame([[0,.33],[1,.11]]).plot(kind="line", x=0, y=1, style="-", legend=None, title="a: 100, b: 200")
plt.xlabel("x")
plt.ylabel("y")
我的问题是,当获得一个包含条件列x和y的数据帧时,如何动态地绘制如上所述的图。
列名是固定的。但是,条件列的值是动态更改的。因此,我不能使用10、20、100、200的值。
如果我有下面的“用a和b过滤”方法,我认为问题解决了:
def filter_with_a_and_b(df, a_b):
# how to implement?
a_b_list = df.drop_duplicates(["a","b"])
new_df_list = filter_with_a_and_b(df, a_b)
for idx, df in enumerate(new_df_list):
df.plot(title=a_b_list[idx])
共有1个答案

这就是你想要的吗?
df.loc[(df.a == 10) & (df.b == 20), ['x','y']].plot(title='a: 10, b: 20')
现在让我们更聪明一点:
cond = {'a': 100, 'b': 200}
df.loc[(df.a == cond['a']) & (df.b == cond['b']), ['x','y']].plot(title='a: {a}, b: {b}'.format(**cond))
或者使用query():
q = 'a == 100 and b == 200'
df.query(q)[['x','y']].plot(title=q)
更新:
a_b_list = df[['a','b']].drop_duplicates()
[df.loc[(df.a == tup[0]) & (df.b == tup[1]), ['x','y']] \
.plot(x='x', y='y', kind='line', style='-',title='a: {0[0]}, b: {0[1]}'.format(tup)) \
.set_ylabel('y')
for tup in a_b_list.itertuples(index=False)]
-
我有这个熊猫数据框 这就给了我: 我该怎么办 做一个新的人物, 将标题添加到图"标题这里" 以某种方式创建一个映射,这样标签不是29,30等,而是“29周”,“30周”等。 将图表的较大版本保存到我的计算机(例如10 x 10英寸) 这件事我已经琢磨了一个小时了!
-
问题内容: 我的数据是: 是使用转换的字符串。 这样的情节非常前卫(这些不是我的实际情节): 我如何像这样平滑它: 我知道本文中提到的内容(这是我从中获取图像的地方),但是如何将其应用于熊猫时间序列? 我发现了一个名为Vincent的很棒的库,它可以处理Pandas,但它不支持Python 2.6。 问题答案: 得到它了。在这个问题的帮助下,我做了以下工作: 从几分钟到几秒重新采样。 \ >>>
-
我必须解决这个问题:目标:删除大多数行缺少输入的列:1。数据帧df:数据帧2。阈值:确定将删除哪些列。如果阈值为.9,则缺少90%值的列将被丢弃:1。带删除列的数据帧df(如果未删除任何列,则返回相同的数据帧) Excel文档截图 我编码了这个: 我必须有“自我、博士和阈值”,不能添加更多。代码必须通过下面的测试用例: 当我运行VT.drop_nan_col(df,0.9). head()时,我不
-
假设我有2个数据帧: DF1: Col1 | Col2 | Col3 XCN000370/17-18C|XCN0003711718C|0003971718 DF2 Col1 | Col2 | Col3 XCN0003711718C|XCN0003711718C|0003971718 我希望它们像这样合并: 首次匹配Col1(DF1)和Col1(DF2) 在保持不匹配的情况下,将Col1(DF1)与
-
问题内容: 我有一个熊猫DataFrame,里面有很多值。 如何删除这样的列? 我试图这样做: 有更优雅的方法吗? 问题答案: 这是保留每列中小于或等于指定数量的nan的列的另一种选择: 在我的测试中,这似乎比李建勋在我测试的案例中建议的放置列方法要快一些:
-
我有以下代码: 输出: 还有情节。 但在绘图中使用此代码时,x轴是索引。但我想得到x轴上的日期。 如何使用测试的编号和ARI的平均值绘制日期 我想,我应该把字符串(日期)改成日期,但我不知道怎么做。 最好的