
绘制熊猫系列数据的平滑曲线

我的数据是:
>>> ts = pd.TimeSeries(data,indexconv)
>>> tsgroup = ts.resample('t',how='sum')
>>> tsgroup
2014-11-08 10:30:00 3
2014-11-08 10:31:00 4
2014-11-08 10:32:00 7
[snip]
2014-11-08 10:54:00 5
2014-11-08 10:55:00 2
Freq: T, dtype: int64
>>> tsgroup.plot()
>>> plt.show()
indexconv是使用转换的字符串datetime.strptime。
这样的情节非常前卫(这些不是我的实际情节): 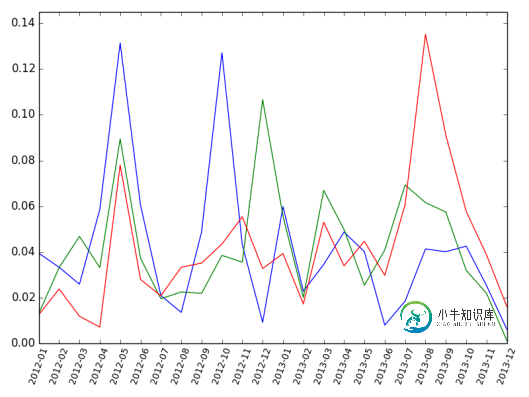
我如何像这样平滑它: 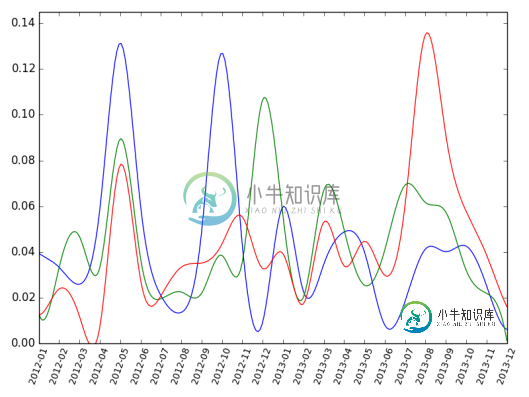
我知道本文中scipy.interpolate提到的内容(这是我从中获取图像的地方),但是如何将其应用于熊猫时间序列?
我发现了一个名为Vincent的很棒的库,它可以处理Pandas,但它不支持Python 2.6。
问题答案:
得到它了。在这个问题的帮助下,我做了以下工作:
-
tsgroup从几分钟到几秒重新采样。\ >>> tsres = tsgroup.resample('S')\ >>> tsres
2014-11-08 10:30:00 3
2014-11-08 10:30:01 NaN
2014-11-08 10:30:02 NaN
2014-11-08 10:30:03 NaN
…
2014-11-08 10:54:58 NaN
2014-11-08 10:54:59 NaN
2014-11-08 10:55:00 2
频率:S,长度:1501 -
使用插值数据
.interpolate(method='cubic')。这会将数据传递给scipy.interpolate.interp1d使用cubic类型,因此您需要安装scipy(pip install scipy)1。\ >>> tsint = tsres.interpolate(method ='cubic')\ >>> tsint
2014-11-08 10:30:00 3.000000
2014-11-08 10:30:01 3.043445
2014-11-08 10:30:02 3.085850
2014-11-08 10:30:03 3.127220
…
2014-11-08 10:54:58 2.461532
2014-11-08 10:54:59 2.235186
2014-11-08 10:55:00 2.000000
频率:S,长度:1501 -
使用绘制它
tsint.plot()。这是原始版本tsgroup和的比较tsint:
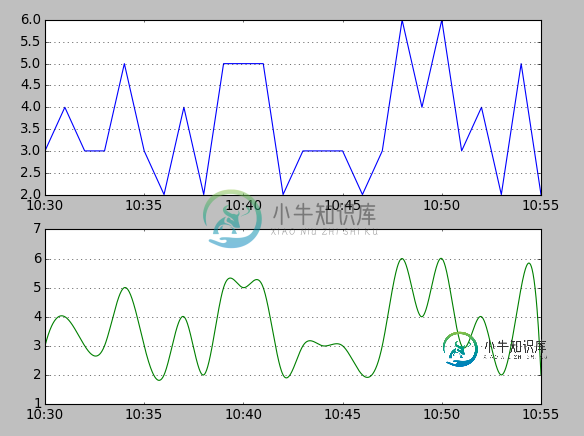
1如果由于.interpolate(method='cubic')告诉您即使已安装Scipy也未安装而出现错误,请打开/usr/lib64/python2.6/site- packages/scipy/interpolate/polyint.py文件或将文件放在任何位置,然后将第二行从更改from scipy import factorial为from scipy.misc import factorial。
-
我有这种熊猫。数据框。“a”、“b”是获得“x”和“y”时的条件。 我需要绘制关于相同条件的(x,y)结肠的折线图。预期结果图为: 当然,这个图像是由以下代码手动给出的: 我的问题是,当获得一个包含条件列x和y的数据帧时,如何动态地绘制如上所述的图。 列名是固定的。但是,条件列的值是动态更改的。因此,我不能使用10、20、100、200的值。 如果我有下面的“用a和b过滤”方法,我认为问题解决了:
-
我有这个熊猫数据框 这就给了我: 我该怎么办 做一个新的人物, 将标题添加到图"标题这里" 以某种方式创建一个映射,这样标签不是29,30等,而是“29周”,“30周”等。 将图表的较大版本保存到我的计算机(例如10 x 10英寸) 这件事我已经琢磨了一个小时了!
-
我有以下熊猫系列 我需要将此更正为csv。但我需要列表中的每个项目作为单独的列。例如:在第一行中,1、11283、1、5应该是单独的列
-
我对熊猫有些陌生。我有一个熊猫数据框,是一行23列。 我想把它转换成一个系列?我想知道做这件事最像蟒蛇的方式是什么? 我试过pd。系列(我的结果),但它抱怨。它还没有聪明到意识到它仍然是数学术语中的“向量”。 谢谢!
-
我有一个带有浮动列的Pandas DataFrame,我将其转换为列表,然后转换为字符串,然后写入文本文件以供其他用途。 例如: 但是,我需要转换后的浮点数不使用科学记数法(本例中为7.569999997E-05)。抑制这些浮动的科学符号的最佳方式是什么?在Pandas数据框架中提前或在序列转换为列表后进行更合理吗? 我研究了“float\u format”参数,该参数可以使用“to\u csv”
-
我有以下代码: 输出: 还有情节。 但在绘图中使用此代码时,x轴是索引。但我想得到x轴上的日期。 如何使用测试的编号和ARI的平均值绘制日期 我想,我应该把字符串(日期)改成日期,但我不知道怎么做。 最好的