
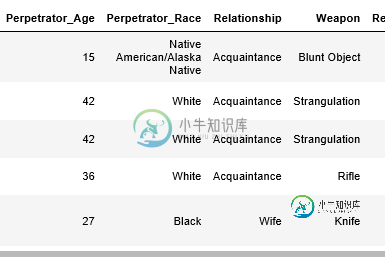
Python熊猫2列关系

第一科伦:武器
第二栏:Pepetrator_年龄
例如,y轴应该是案件数量x轴犯罪人的年龄
线是犯罪者使用的武器类型
您可以将其复制粘贴到jupyter以初始化数据集
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
data = pd.read_csv("hdb.csv", low_memory=False)
cols = data.columns
cols = cols.map(lambda x: x.replace(' ', '_'))
data.columns = cols
#clear the unnecessary data here
data = data.drop(['Agency_Code', 'Victim_Ethnicity', 'Agency_Name','Agency_Type', 'Perpetrator_Ethnicity', 'Victim_Count', 'Perpetrator_Count'], axis=1)
data = data[data.Perpetrator_Age != "0"]
data = data[data.Perpetrator_Age != ""]
data = data[data.Perpetrator_Age != " "]
data = data[data.Victim_Sex != "Unknown"]
data = data[data.Victim_Race != "Unknown"]
data = data[data.Perpetrator_Sex != "Unknown"]
data = data[data.Perpetrator_Race != "Unknown"]
data = data[data.Relationship != "Unknown"]
data = data[data.Weapon != "Unknown"]
data
此处的数据集:https://www.kaggle.com/jyzaguirre/us-homicide-reports
共有1个答案

IIUC,这种数据分组可能更好地显示为分组条形图,例如在Seborn的Countfield中,而不是在线图中,因为您希望按特定列(武器)着色,但您希望显示x轴上的不同列(Perpetrator_Age)。例如,线图不会同时捕获这些聚合。
下面是一个显式的groupby,显示您正在引用的聚合
df_grouped = df.groupby(['Perpetrator_Age', 'Weapon']).count()
print(df_grouped)
Perpetrator_Race Relationship
Perpetrator_Age Weapon
15 Blunt Object 1 1
27 Knife 1 1
36 Rifle 1 1
42 Strangulation 2 2
现在,您要在x轴上显示第一个索引级别(罪犯年龄),必须使用第二个索引级别武器为绘制的数据着色。
这里有一些方法(不需要Groupby)
海本
- 使用
countplot,它将生成计数条形图(对应于每个分组中的案例数或记录数),并允许您指定用于分组数据的列 - 由于您希望按
武器列着色,countplot允许参数hue,您可以在其中指定该属性 - 附加链接
- 自定义图例标题
- 添加自定义y轴标签
进口
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set(style="whitegrid")代码
ax = sns.countplot(x="Perpetrator_Age", hue="Weapon", data=df) handles, labels = ax.get_legend_handles_labels() ax.legend(handles=handles, labels=labels) ax.set_ylabel("Number of cases")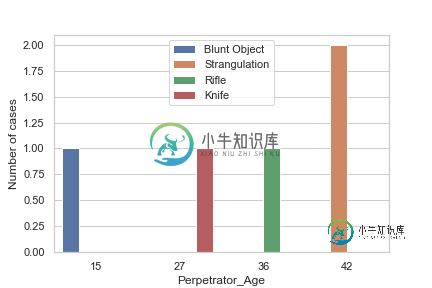
牛郎星
- 基于多系列折线图和分组条形图的留档示例
- 附加链接
- 更改条形宽度
进口
import altair as alt alt.renderers.enable('notebook')代码
alt.Chart(df).mark_bar(size=15).encode( alt.Y('count(Weapon):Q', axis=alt.Axis(title='Number of cases')), alt.X('Perpetrator_Age:O', axis=alt.Axis(labelAngle=0)), color='Weapon:N' ).properties( width=250, height=250 )
- 附加链接
-
我有两个数据帧,其中一列名为。数据帧是从两名参与者同时录制的两个视频中提取的数据。由于跟踪失败,数据缺少一些帧(每个视频不同)。我想根据帧整数值取一个交点。 这里发布了一个类似的问题:熊猫——基于列条目的两个数据帧的交集,但接受的答案是连接,而不是交集。 已删除的行不在和 (我可以重置索引后,我完成处理) 我想首先得到两个数据帧的帧列的交集: 错误: 在获得两个数据帧中的帧索引后,我考虑执行以下操
-
问题内容: 我有一个从csv文件构建的pandas中的数据框。数据框有几列,并由其中一列进行索引(这是唯一的,因为每一行都有用于该索引的该列的唯一值。) 如何基于应用于多个列的“复杂”过滤器选择数据框的行?我可以轻松地从列中大于10的数据框中选择切片,例如: 但是,如果我想要的东西就像一个过滤器:选择的切片,其中 任何 列都大于10? 或者,如果for的值大于10但值小于5? 这些如何在熊猫中实现
-
问题内容: 我已经看到了将一个列/系列分解为Pandas数据框的多个列的主题的几种变体,但是我一直在尝试做点事情,而实际上并没有成功地使用现有方法。 给定这样的一个DataFrame: 我想将系列中的项目转换为以值作为值的列,如下所示: 我觉得这应该是相对简单的事情,但是由于卷积水平的提高,我已经为此花了几个小时不停地努力,但没有成功。 问题答案: 有几种方法: 使用: 使用: 使用后跟:
-
问题内容: 我有一个包含多个列的数据集,我希望对其进行一次热编码。但是,我不想为每个编码都有编码,因为所说的列与所说的项目有关。我想要的是一组使用所有列的虚拟变量。请参阅我的代码以获得更好的解释。 假设我的数据框如下所示: 如果我执行 输出将是 但是,我想获得的是这样的东西: 代替具有表示编码,例如多列的和,我只希望有一组(,,等等)与值时任何在列中的值的,,显示出来。 需要说明的是,在我的原始数
-
问题内容: 我知道这个问题有很多主题,但是没有一种方法适合我,因此我将发布有关我的具体情况的信息 我有一个看起来像这样的数据框: 我想做的是将“性别”列中的全0替换为“女”,并将所有1替换为“男”,但是当我使用上面的代码时,数据框中的值似乎没有变化 我是否使用了replace()错误?还是有更好的方法进行条件值替换? 问题答案: 是的,您使用的是错误的,默认情况下不是就地操作,它会返回替换的数据框
-
我有一个数据框,上面写着有一列 <代码> 我想对这些年龄段进行分组,并创建一个类似这样的新专栏 如何使用Pandas库实现这一点。 我试过这样做 但这样做我得到了这个警告 /Users/Anand/miniconda3/envs/learn/lib/python3.7/site packages/ipykernel_launcher.py:3:SettingWithCopyWarning:试图在数