
Spark on Angel
Spark on Angel
Angel从v1.0.0版本开始,就加入了PS-Service的特性,不仅仅可以作为一个完整的PS框架运行,也可以作为一个PS-Service,为不具备参数服务器能力的分布式框架,引入PS能力,从而让它们运行得更快,功能更强。 而Spark是这个Service设计的第一个获益者。
作为一个比较流行的内存计算框架,Spark 的核心概念是RDD,而RDD的关键特性之一,是其不可变性,来规避分布式环境下复杂的各种并行问题。这个抽象,在数据分析的领域是没有问题的,能最大化的解决分布式问题,简化各种算子的复杂度,并提供高性能的分布式数据处理运算能力。
然而在机器学习领域,RDD的弱势也很明显。 机器学习的核心是迭代和参数更新,RDD凭借着逻辑上不落地的内存计算特性,可以很好的解决迭代的问题,然而RDD的不可变性,却不适合参数反复多次更新的需求。 这个根本的不匹配性,导致了Spark的MLLib库,发展一直非常缓慢,从15年开始就没有实质性的创新,性能也不好。 而Spark社区,一直也不愿意正视和解决这个问题。
现在,由于Angel良好的设计和平台性,利用其提供的PS-Service,Spark可以充分利用Angel的参数更新能力,让Spark也具备高速训练大模型的能力。 开发者只需要付出很小的修改代价,就能用简洁优雅代码实现复杂的机器学习算法。
1. 架构设计
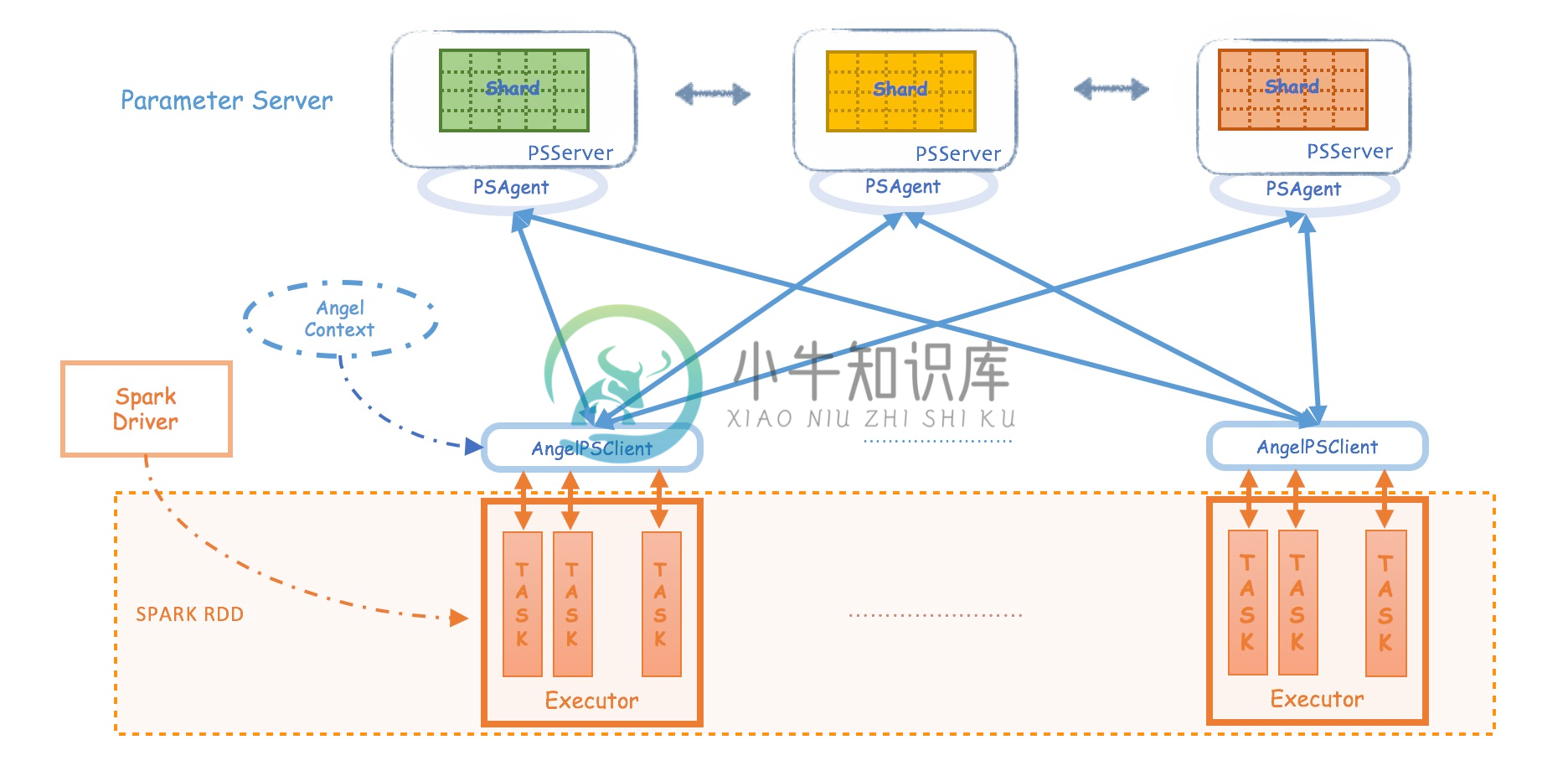
Spark-On-Angel 的系统架构如下图所示,简单来说:
- Spark RDD是不可变区,Angel PS是可变区
- Spark通过PSAgent与Angel进行协作和通讯
2. 核心实现
得益于Angel的接口设计,Spark-On-Angel非常轻量,其主要核心模块包括
PSContext
- 利用Spark的Context,和Angel的配置,创建AngelContext,在Driver端负责全局的初始化和启动工作
PSModel
- PSModel是PS server上PSVector/PSMatrix的总称,包含着PSClient对象
- PSModel是PSVector和PSMatrix的父类
PSVector
- PSVector的申请:通过
PSVector.dense(dim: Int, capacity: Int = 50, rowType:RowType.T_DENSE_DOUBLE)申请PSVector,会创建一个维度为dim,容量为capacity, 类型为Double的VectorPool,同一个VectorPool内的两个PSVector可以做运算。 通过PSVector.duplicate(psVector),申请一个与psVector在同一个VectorPool的PSVector。
- PSVector的申请:通过
PSMatrix
- PSMatrix的创建和销毁:通过
PSMatrix.dense(rows: Int, cols: Int)创建,当PSMatrix不再使用后,需要手动调用destory销毁该Matrix
- PSMatrix的创建和销毁:通过
使用Spark on Angel的简单代码如下:
PSContext.getOrCreate(spark.sparkContext)
val psVector = PSVector.dense(dim, capacity)
rdd.map { case (label , feature) =>
psVector.increment(feature)
...
}
println("feature sum:" + psVector.pull.mkString(" "))
3. 启动流程
Spark on Angel本质上是一个Spark任务。Spark启动后,driver通过Angel PS的接口启动Angel PS,必要时将部分数据封装成PSVector丢给PS node管理。 因此,整个Spark on Angel的执行过程与Spark差别不多,driver负责启动、管理PS node, executor在需要的时候向PS node发起对PSVector操作的请求。
Spark driver的执行流程
- 启动SparkSession
- 启动PSContext
- 申请PSVector/PSMatrix
- 执行算法逻辑
- 终止PSContext和SparkSession
Spark executor的执行流程
- 启动PSContext
- 执行driver分配的task
项目地址:https://github.com/Angel-ML/angel
官网:https://angelml.ai/