
将深度学习应用到 NLP

词向量
自然语言需要数学化才能够被计算机认识和计算。数学化的方法有很多,最简单的方法是为每个词分配一个编号,这种方法已经有多种应用,但是依然存在一个缺点:不能表示词与词的关系。
词向量是这样的一种向量[0.1, -3.31, 83.37, 93.0, -18.37, ……],每一个词对应一个向量,词义相近的词,他们的词向量距离也会越近(欧氏距离、夹角余弦)
词向量有一个优点,就是维度一般较低,一般是50维或100维,这样可以避免维度灾难,也更容易使用深度学习
词向量如何训练得出呢?
首先要了解一下语言模型,语言模型相关的内容请见我另外一篇文章《自己动手做聊天机器人 十三-把语言模型探究到底》。语言模型表达的实际就是已知前n-1个词的前提下,预测第n个词的概率。
词向量的训练是一种无监督学习,也就是没有标注数据,给我n篇文章,我就可以训练出词向量。
基于三层神经网络构建n-gram语言模型(词向量顺带着就算出来了)的基本思路:
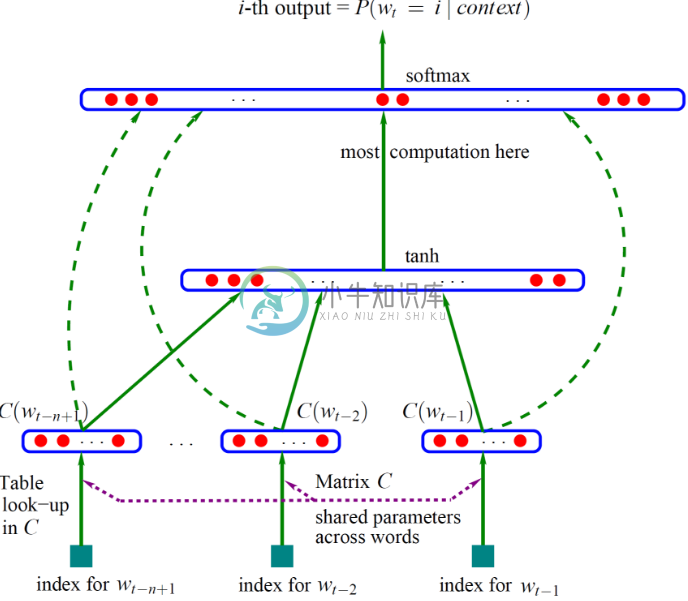
最下面的w是词,其上面的C(w)是词向量,词向量一层也就是神经网络的输入层(第一层),这个输入层是一个(n-1)×m的矩阵,其中n-1是词向量数目,m是词向量维度
第二层(隐藏层)是就是普通的神经网络,以H为权重,以tanh为激活函数
第三层(输出层)有|V|个节点,|V|就是词表的大小,输出以U为权重,以softmax作为激活函数以实现归一化,最终就是输出可能是某个词的概率。
另外,神经网络中有一个技巧就是增加一个从输入层到输出层的直连边(线性变换),这样可以提升模型效果,这个变换矩阵设为W
假设C(w)就是输入的x,那么y的计算公式就是y = b + Wx + Utanh(d+Hx)
这个模型里面需要训练的有这么几个变量:C、H、U、W。利用梯度下降法训练之后得出的C就是生成词向量所用的矩阵,C(w)表示的就是我们需要的词向量
上面是讲解词向量如何“顺带”训练出来的,然而真正有用的地方在于这个词向量如何进一步应用。
词向量的应用
第一种应用是找同义词。具体应用案例就是google的word2vec工具,通过训练好的词向量,指定一个词,可以返回和它cos距离最相近的词并排序。
第二种应用是词性标注和语义角色标注任务。具体使用方法是:把词向量作为神经网络的输入层,通过前馈网络和卷积网络完成。
第三种应用是句法分析和情感分析任务。具体使用方法是:把词向量作为递归神经网络的输入。
第四种应用是命名实体识别和短语识别。具体使用方法是:把词向量作为扩展特征使用。
另外词向量有一个非常特别的现象:C(king)-C(queue)≈C(man)-C(woman),这里的减法就是向量逐维相减,换个表达方式就是:C(king)-C(man)+C(woman)和它最相近的向量就是C(queue),这里面的原理其实就是:语义空间中的线性关系。基于这个结论相信会有更多奇妙的功能出现。