
初识 NLTK 库

NLTK库安装
pip install nltk执行python并下载书籍:
[root@centos #] python
Python 2.7.11 (default, Jan 22 2016, 08:29:18)
[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> nltk.download()
选择book后点Download开始下载
下载完成以后再输入:
>>> from nltk.book import *你会看到可以正常加载书籍如下:
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908这里面的text*都是一个一个的书籍节点,直接输入text1会输出书籍标题:
>>> text1
<Text: Moby Dick by Herman Melville 1851>搜索文本
执行
>>> text1.concordance("former")会显示20个包含former的语句上下文
我们还可以搜索相关词,比如:
>>> text1.similar("ship")
whale boat sea captain world way head time crew man other pequod line
deck body fishery air boats side voyage输入了ship,查找了boat,都是近义词
我们还可以查看某个词在文章里出现的位置:
>>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])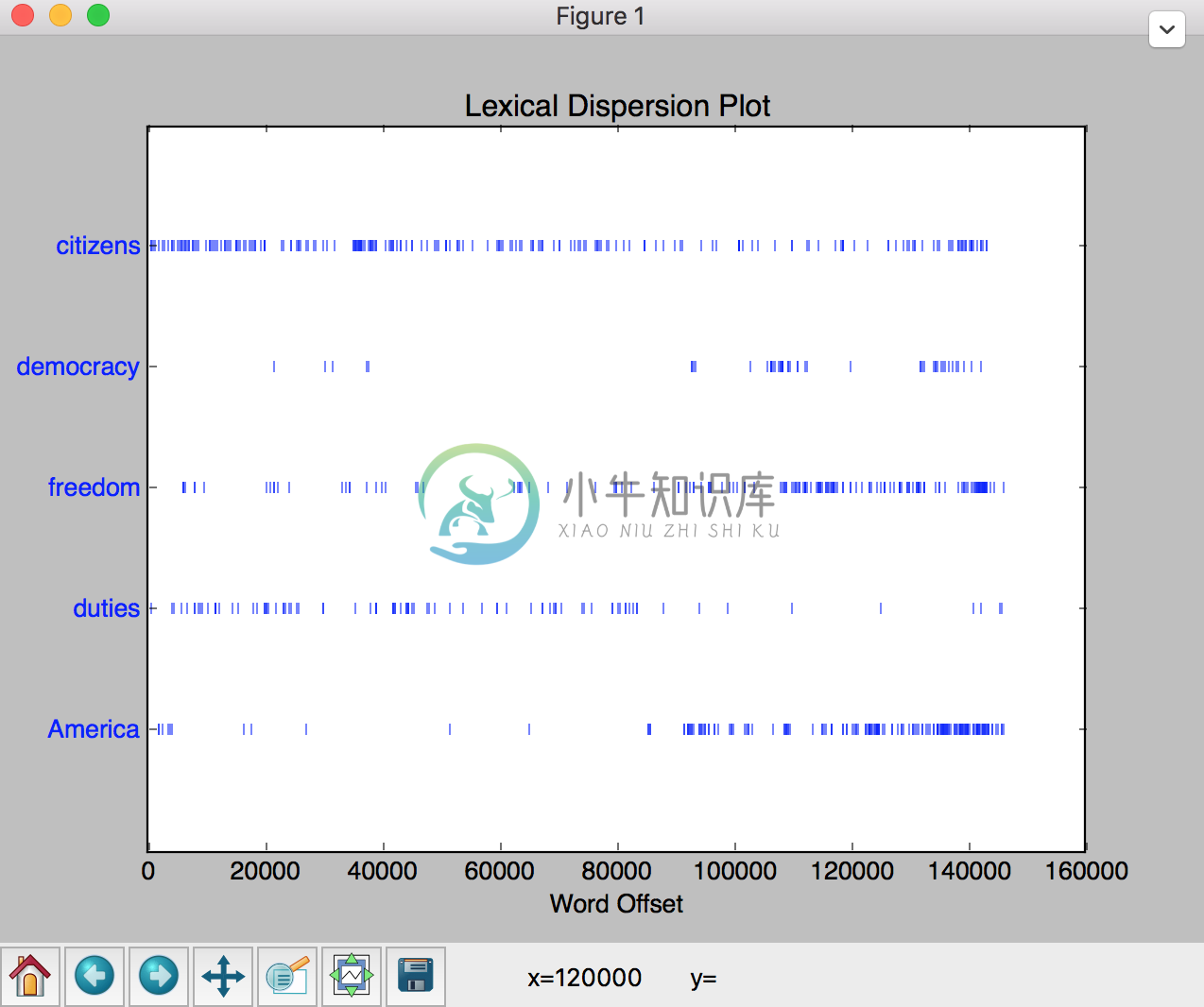
词统计
len(text1):返回总字数
set(text1):返回文本的所有词集合
len(set(text4)):返回文本总词数
text4.count("is"):返回“is”这个词出现的总次数
FreqDist(text1):统计文章的词频并按从大到小排序存到一个列表里
fdist1 = FreqDist(text1);fdist1.plot(50, cumulative=True):统计词频,并输出累计图像
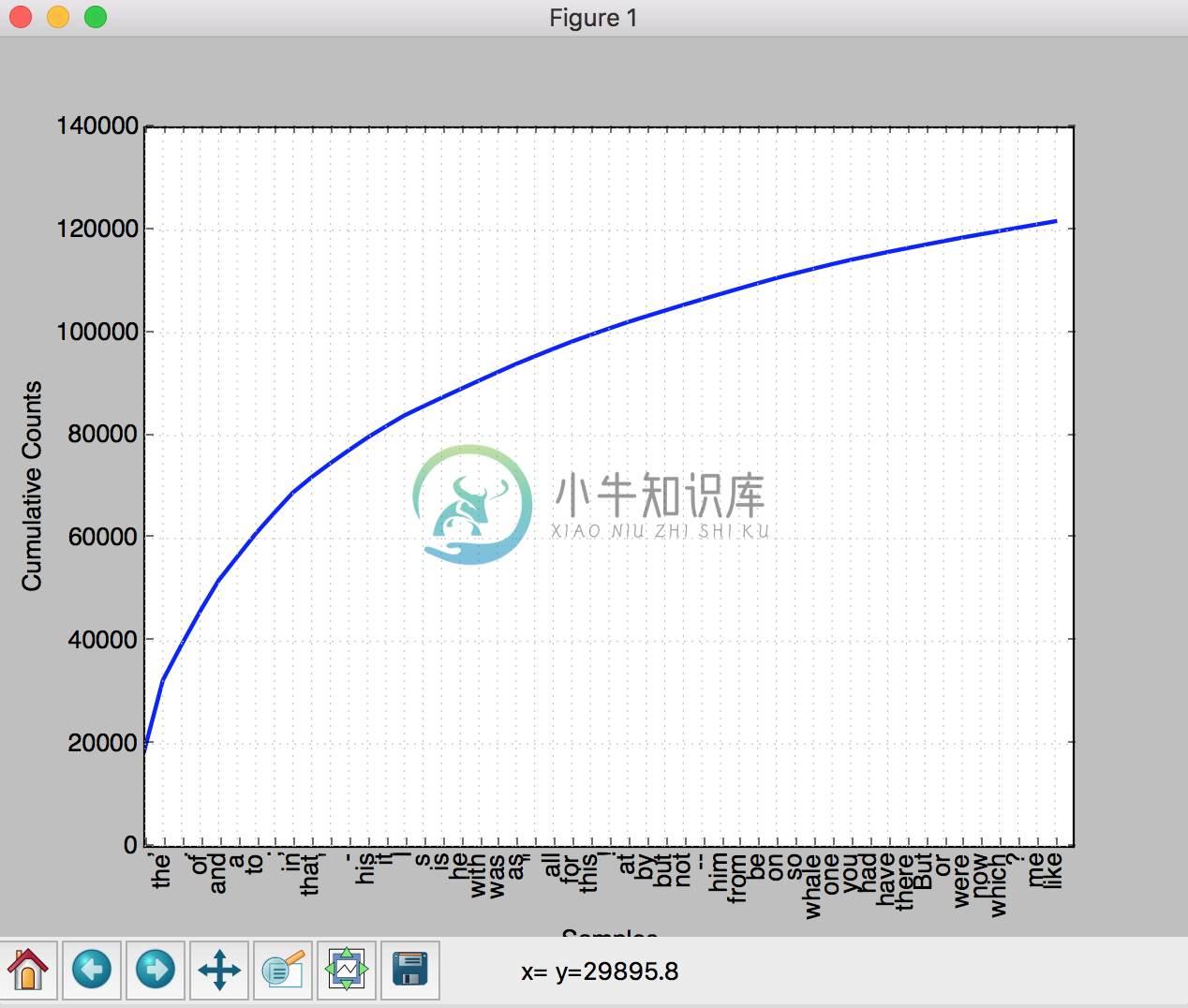
纵轴表示累加了横轴里的词之后总词数是多少,这样看来,这些词加起来几乎达到了文章的总词数
fdist1.hapaxes():返回只出现一次的词
text4.collocations():频繁的双联词
自然语言处理关键点
词意理解:中国队大胜美国队;中国队大败美国队。“胜”、“败”一对反义词,却表达同样的意思:中国赢了,美国输了。这需要机器能够自动分析出谁胜谁负
自动生成语言:自动生成语言基于语言的自动理解,不理解就无法自动生成
机器翻译:现在机器翻译已经很多了,但是还很难达到最佳,比如我们把中文翻译成英文,再翻译成中文,再翻译成英文,来回10轮,发现和最初差别还是非常大的。
人机对话:这也是我们想做到的最终目标,这里有一个叫做“图灵测试”的方式,也就是在5分钟之内回答提出问题的30%即通过,能通过则认为有智能了。
自然语言处理分两派,一派是基于规则的,也就是完全从语法句法等出发,按照语言的规则来分析和处理,这在上个世纪经历了很多年的试验宣告失败,因为规则太多太多,而且很多语言都不按套路出牌,想象你追赶你的影子,你跑的快他跑的更快,你永远都追不上它。另一派是基于统计的,也就是收集大量的语料数据,通过统计学习的方式来理解语言,这在当代越来越受重视而且已经成为趋势,因为随着硬件技术的发展,大数据存储和计算已经不是问题,无论有什么样的规则,语言都是有统计规律的,当然基于统计也存在缺陷,那就是“小概率事件总是不会发生的”导致总有一些问题解决不了。
下一节我们就基于统计的方案来解决语料的问题。