
指标:Spectator,Servo和Atlas
当一起使用时,Spectator / Servo和Atlas提供了近乎实时的操作洞察平台。
Netflix的度量收集库Spectator和Servo Atlas是用于管理维度时间序列数据的Netflix指标后端。
Servo为Netflix服务了好几年,仍然可以使用,但逐渐被淘汰出局Spectator,这只适用于Java 8. Spring Cloud Netflix提供了支持,但Java 8鼓励基于应用的应用程序使用Spectator。
维度与层次度量
Spring Boot执行器指标是层次结构,指标只能由名称分隔。这些名称通常遵循将密钥/值属性对(维)嵌入到以句点分隔的名称中的命名约定。考虑以下两个端点(root和star-star)的指标:
{
"counter.status.200.root": 20,
"counter.status.400.root": 3,
"counter.status.200.star-star": 5,
}第一个指标给出了每单位时间内针对根端点的成功请求的归一化计数。但是如果系统有20个端点,并且想要获得针对所有端点的成功请求计数呢?一些分级度量后端将允许您指定一个通配符,例如counter.status.200. ,它将读取所有20个指标并聚合结果。或者,您可以提供HandlerInterceptorAdapter拦截并记录所有成功请求的counter.status.200.all等指标,而不考虑端点,但现在您必须编写20 + 1个不同的指标。同样,如果您想知道服务中所有端点的成功请求总数,您可以指定一个通配符,例如counter.status.2 .*。
即使在分级度量后端的通配符支持的情况下,命名一致性也是困难的。具体来说,这些标签在名称字符串中的位置可能会随着时间而滑落,从而导致查询错 例如,假设我们为上述HTTP方法添加了一个额外的维度。那么counter.status.200.root成为counter.status.200.method.get.root等等。我们的counter.status.200.*突然不再具有相同的语义。此外,如果新的维度在整个代码库中不均匀地应用,某些查询可能会变得不可能。这可以很快失控。
Netflix指标被标记(又称维度)。每个指标都有一个名称,但是这个单一的命名度量可以包含多个统计信息和“标签”键/值对,这允许更多的查询灵活性。实际上统计本身就是记录在一个特殊的标签上。
使用Netflix Servo或Spectator记录,上述根端点的计时器包含每个状态码的4个统计信息,其中计数统计信息与Spring Boot执行器计数器相同。如果到目前为止,我们遇到了HTTP 200和400,将有8个可用数据点:
{
"root(status=200,stastic=count)": 20,
"root(status=200,stastic=max)": 0.7265630630000001,
"root(status=200,stastic=totalOfSquares)": 0.04759702862580789,
"root(status=200,stastic=totalTime)": 0.2093076914666667,
"root(status=400,stastic=count)": 1,
"root(status=400,stastic=max)": 0,
"root(status=400,stastic=totalOfSquares)": 0,
"root(status=400,stastic=totalTime)": 0,
}默认度量集合
没有任何附加依赖或配置,基于Spring Cloud的服务将自动配置Servo MonitorRegistry,并开始收集每个Spring MVC请求的指标。默认情况下,将为每个MVC请求记录名称为rest的Servo定时器,其标记为:
- HTTP方法
- HTTP状态(例如200,400,500)
- URI(如果URI为空,则为“root”),为Atlas
- 异常类名称,如果请求处理程序抛出异常
- 如果在请求上设置了匹配
netflix.metrics.rest.callerHeader的密钥的请求头,则呼叫者。netflix.metrics.rest.callerHeader没有默认键。如果您希望收集来电者信息,则必须将其添加到应用程序属性中。
设置netflix.metrics.rest.metricName属性将度量值的名称从rest更改为您提供的名称。
如果Spring AOP已启用,并且org.aspectj:aspectjweaver存在于您的运行时类路径上,则Spring Cloud还将收集每个使用RestTemplate进行的客户端调用的指标。将为每个具有以下标签的MVC请求记录名称为restclient的Servo定时器:
- HTTP方法
- HTTP状态(例如200,400,500),如果响应返回为空,则为“CLIENT_ERROR”;如果在执行
RestTemplate方法期间发生IOException,则为“IO_ERROR” - URI,为Atlas
- 客户名称
| 警告 | 避免在RestTemplate内使用硬编码的url参数。定位动态端点时使用URL变量。这将避免ServoMonitorCache将每个网址视为唯一密钥的潜在“GC覆盖限制达到”问题。 |
// recommended
String orderid = "1";
restTemplate.getForObject("http://testeurekabrixtonclient/orders/{orderid}", String.class, orderid)
// avoid
restTemplate.getForObject("http://testeurekabrixtonclient/orders/1", String.class)指标集:Spectator
要启用Spectator指标,请在spring-boot-starter-spectator上包含依赖关系:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-spectator</artifactId>
</dependency>在Spectator说明中,仪表是一个命名,打字和标记的配置,而指标表示给定仪表在某个时间点的值。Spectator米由注册表创建和控制,注册表目前有几个不同的实现。Spectator提供4米类型:计数器,定时器,量规和分配摘要。
Spring Cloud Spectator集成为您配置可注入的com.netflix.spectator.api.Registry实例。具体来说,它配置一个ServoRegistry实例,以统一REST度量标准的集合,并将度量标准导出到Servo API下的Atlas后端。实际上,这意味着您的代码可能会使用Servo显示器和Spectator米的混合,并且都将由Spring Boot Actuator MetricReader实例舀取,并将两者都发送到Atlas后端
Spectator柜台
计数器用于测量某些事件发生的速率。
// create a counter with a name and a set of tags
Counter counter = registry.counter("counterName", "tagKey1", "tagValue1", ...);
counter.increment(); // increment when an event occurs
counter.increment(10); // increment by a discrete amount计数器记录单个时间归一化统计量。
Spectator计时器
一个计时器用于测量一些事件需要多长时间。Spring Cloud自动记录Spring MVC请求和有条件RestTemplate请求的定时器,稍后可用于为请求相关指标创建仪表板,如延迟:
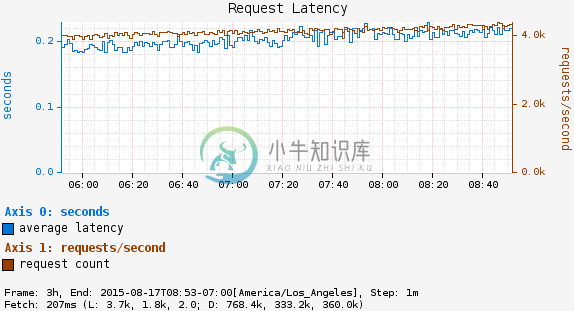 图4.请求延迟
图4.请求延迟// create a timer with a name and a set of tags
Timer timer = registry.timer("timerName", "tagKey1", "tagValue1", ...);
// execute an operation and time it at the same time
T result = timer.record(() -> fooReturnsT());
// alternatively, if you must manually record the time
Long start = System.nanoTime();
T result = fooReturnsT();
timer.record(System.nanoTime() - start, TimeUnit.NANOSECONDS);计时器同时记录4个统计信息:count,max,totalOfSquares和totalTime。如果您在每次记录时间时在计数器上调用了increment()一次,计数统计量将始终与计数器提供的单个归一化值相匹配,因此对于单个操作,不需要单独计数和分时。
对于长时间运行的操作,Spectator提供了一个特殊的LongTaskTimer。
Spectator量规
量规用于确定一些当前值,如队列的大小或处于运行状态的线程数。由于仪表被采样,它们不提供关于这些值在样品之间如何波动的信息。
仪器的正常使用包括在初始化中使用标识符注册仪表,对要采样的对象的引用,以及基于对象获取或计算数值的功能。对对象的引用被单独传递,Spectator注册表将保留对该对象的弱引用。如果对象被垃圾回收,则Spectator将自动删除注册。见注 Spectator是关于潜在的内存泄漏的文件中,如果这个API被滥用。
// the registry will automatically sample this gauge periodically
registry.gauge("gaugeName", pool, Pool::numberOfRunningThreads);
// manually sample a value in code at periodic intervals -- last resort!
registry.gauge("gaugeName", Arrays.asList("tagKey1", "tagValue1", ...), 1000);Spectator分发摘要
分发摘要用于跟踪事件的分布情况。它类似于一个计时器,但更普遍的是,大小不一定是一段时间。例如,分发摘要可用于测量服务器的请求的有效载荷大小。
// the registry will automatically sample this gauge periodically
DistributionSummary ds = registry.distributionSummary("dsName", "tagKey1", "tagValue1", ...);
ds.record(request.sizeInBytes());指标集:Servo
| 警告 | 如果您的代码在Java 8上编译,请使用Spectator而不是Servo,因为Spectator注定要从长期来替换Servo。 |
在Servo语言中,监视器是一个命名,键入和标记的配置,而指标表示给定监视器在某个时间点的值。Servo显示器在逻辑上相当于Spectator米。Servo显示器由MonitorRegistry创建和控制。尽管有上述警告,Servo确实具有比Spectator有米的更广泛的监视器选项。
Spring Cloud集成为您配置可注入的com.netflix.servo.MonitorRegistry实例。在Servo中创建了相应的Monitor类型后,记录数据的过程完全类似于Spectator。
创建Servo显示器
如果您正在使用由Spring Cloud提供的Servo MonitorRegistry实例(具体来说是DefaultMonitorRegistry的实例),则Servo提供了用于检索计数器和计时器的便利类。这些便利类确保每个唯一的名称和标签组合只注册一个Monitor。
要在Servo中手动创建监视器类型,特别是对于不提供方便方法的异域监视器类型,通过提供MonitorConfig实例来实例化适当的类型:
MonitorConfig config = MonitorConfig.builder("timerName").withTag("tagKey1", "tagValue1").build();
// somewhere we should cache this Monitor by MonitorConfig
Timer timer = new BasicTimer(config);
monitorRegistry.register(timer);指标后端:Atlas
Netflix开发了Atlas来管理维度时间序列数据,实现近实时操作洞察。Atlas具有内存中数据存储功能,可以非常快速地收集和报告大量的指标。
Atlas捕获操作情报。而商业智能是收集的数据,用于分析一段时间内的趋势,操作情报提供了系统中目前发生的情况。
Spring Cloud提供了一个spring-cloud-starter-atlas,它具有您需要的所有依赖关系。然后只需使用@EnableAtlas注释您的Spring Boot应用程序,并为您运行的Atlas服务器提供netflix.atlas.uri属性的位置。
全球标签
您可以通过Spring Cloud向发送到Atlas后端的每个度量标准添加标签。全局标签可用于按应用程序名称,环境,区域等分隔度量。
实现AtlasTagProvider的每个bean将贡献全局标签列表:
@Bean
AtlasTagProvider atlasCommonTags(
@Value("${spring.application.name}") String appName) {
return () -> Collections.singletonMap("app", appName);
}使用Atlas
要引导内存独立的Atlas实例:
$ curl -LO https://github.com/Netflix/atlas/releases/download/v1.4.2/atlas-1.4.2-standalone.jar
$ java -jar atlas-1.4.2-standalone.jar| 提示 | 运行在r3.2xlarge(61GB RAM)上的Atlas独立节点可以在给定的6小时窗口内每分钟处理大约200万个度量值。 |
一旦运行,您收集了少量指标,请通过在Atlas服务器上列出代码来验证您的设置是否正确:
$ curl http://ATLAS/api/v1/tags| 提示 | 在针对您的服务执行多个请求后,您可以通过在浏览器中粘贴以下URL来收集关于每个请求的请求延迟的一些非常基本的信息:http://ATLAS/api/v1/graph?q=name,rest,:eq,:avg |
Atlas wiki包含各种场景样本查询的汇编。
确保使用双指数平滑来查看警报原理和文档,以生成动态警报阈值。
重试失败的请求
Spring Cloud Netflix提供了多种方式来进行HTTP请求。您可以使用负载平衡RestTemplate,Ribbon或Feign。无论您如何选择HTTP请求,始终有可能失败的请求。当请求失败时,您可能希望自动重试该请求。要在使用Sping Cloud Netflix时完成此操作,您需要在应用程序的类路径中包含 Spring重试。当Spring重试出现负载平衡RestTemplates时,Feign和Zuul将自动重试任何失败的请求(假设配置允许)。
组态
随时Ribbon与Spring重试一起使用,您可以通过配置某些Ribbon属性来控制重试功能。您可以使用的属性是client.ribbon.MaxAutoRetries,client.ribbon.MaxAutoRetriesNextServer和client.ribbon.OkToRetryOnAllOperations。请参阅Ribbon文档 ,了解属性的具体内容。
此外,您可能希望在响应中返回某些状态代码时重试请求。您可以列出您希望Ribbon客户端使用属性clientName.ribbon.retryableStatusCodes重试的响应代码。例如
clientName:
ribbon:
retryableStatusCodes: 404,502您还可以创建一个类型为LoadBalancedRetryPolicy的bean,并实现retryableStatusCode方法来确定是否要重试发出状态代码的请求。
Zuul
您可以通过将zuul.retryable设置为false来关闭Zuul的重试功能。您还可以通过将zuul.routes.routename.retryable设置为false,以路由方式禁用重试功能。