
相关软件介绍/Hive/Partition简述
一、背景
1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、分区表指的是在创建表时指定的partition的分区空间。
3、如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
二、技术细节
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、表和列名不区分大小写。
3、分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table day_table (id int, content string) partitioned by (dt string);单分区表,按天分区,在表结构中存在id,content,dt三列。
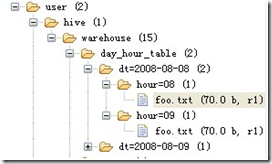
b、双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
表文件夹目录示意图(多分区表):
6、添加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: : PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08') location '/path/pv1.txt' PARTITION (dt='2008-08-08', hour='09') location '/path/pv2.txt';7、删除分区语法:
ALTER TABLE table_name DROP partition_spec, partition_spec,...用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]例:
LOAD DATA INPATH '/user/pv.txt' INTO TABLE day_hour_table PARTITION(dt='2008-08- 08', hour='08'); LOAD DATA local INPATH '/user/hua/*' INTO TABLE day_hour partition(dt='2010-07- 07');当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。9、基于分区的查询的语句:SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';10、查看分区语句:
hive> show partitions day_hour_table; OK dt=2008-08-08/hour=08 dt=2008-08-08/hour=09 dt=2008-08-09/hour=09
三、总结
1、在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在最字集的目录中。
2、总的说来partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。