
十二、设备和服务器上的分布式 TensorFlow
在第 11 章,我们讨论了几种可以明显加速训练的技术:更好的权重初始化,批量标准化,复杂的优化器等等。 但是,即使采用了所有这些技术,在具有单个 CPU 的单台机器上训练大型神经网络可能需要几天甚至几周的时间。
在本章中,我们将看到如何使用 TensorFlow 在多个设备(CPU 和 GPU)上分配计算并将它们并行运行(参见图 12-1)。 首先,我们会先在一台机器上的多个设备上分配计算,然后在多台机器上的多个设备上分配计算。
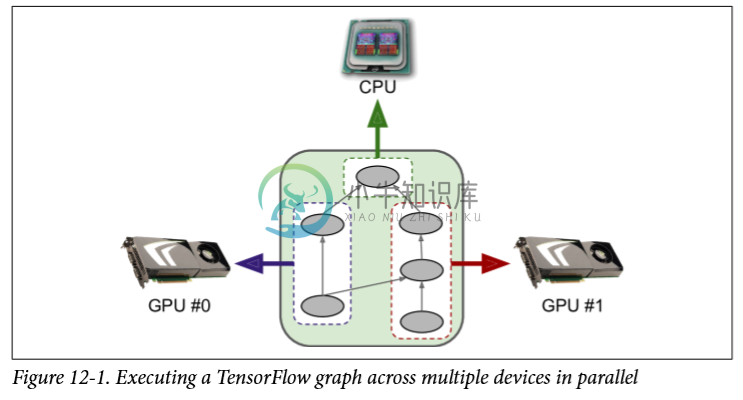
与其他神经网络框架相比,TensorFlow 对分布式计算的支持是其主要亮点之一。 它使您可以完全控制如何跨设备和服务器分布(或复制)您的计算图,并且可以让您以灵活的方式并行和同步操作,以便您可以在各种并行方法之间进行选择。
我们来看一些最流行的方法来并行执行和训练一个神经网络,这让我们不再需要等待数周才能完成训练算法,而最终可能只会等待几个小时。 这不仅可以节省大量时间,还意味着您可以更轻松地尝试各种模型,并经常重新训练模型上的新数据。
还有其他很好的并行化例子,包括当我们在微调模型时可以探索更大的超参数空间,并有效地运行大规模神经网络。
但我们必须先学会走路才能跑步。 我们先从一台机器上的几个 GPU 上并行化简单图形开始。
一台机器上多设备
只需添加 GPU 卡到单个机器,您就可以获得主要的性能提升。 事实上,在很多情况下,这就足够了。 你根本不需要使用多台机器。 例如,通常在单台机器上使用 8 个 GPU,而不是在多台机器上使用 16 个 GPU(由于多机器设置中的网络通信带来的额外延迟),可以同样快地训练神经网络。
在本节中,我们将介绍如何设置您的环境,以便 TensorFlow 可以在一台机器上使用多个 GPU 卡。 然后,我们将看看如何在可用设备上进行分布操作,并且并行执行它们。
安装
为了在多个 GPU 卡上运行 TensorFlow,首先需要确保 GPU 卡具有 NVidia 计算能力(大于或等于3.0)。 这包括 Nvidia 的 Titan,Titan X,K20 和 K40(如果你拥有另一张卡,你可以在 https://developer.nvidia.com/cuda-gpus 查看它的兼容性)。
如果您不拥有任何 GPU 卡,则可以使用具有 GPU 功能的主机服务器,如 Amazon AWS。 在 ŽigaAvsec 的博客文章中,提供了在 Amazon AWS GPU 实例上使用 Python 3.5 设置 TensorFlow 0.9 的详细说明。将它更新到最新版本的 TensorFlow 应该不会太难。 Google 还发布了一项名为 Cloud Machine Learning 的云服务来运行 TensorFlow 图表。 2016 年 5 月,他们宣布他们的平台现在包括配备张量处理器(TPU)的服务器,专门用于机器学习的处理器,比许多 GPU 处理 ML 任务要快得多。 当然,另一种选择只是购买你自己的 GPU 卡。 Tim Dettmers 写了一篇很棒的博客文章来帮助你选择,他会定期更新它。
您必须下载并安装相应版本的 CUDA 和 cuDNN 库(如果您使用的是 TensorFlow 1.0.0,则为 CUDA 8.0 和 cuDNN 5.1),并设置一些环境变量,以便 TensorFlow 知道在哪里可以找到 CUDA 和 cuDNN。 详细的安装说明可能会相当迅速地更改,因此最好按照 TensorFlow 网站上的说明进行操作。
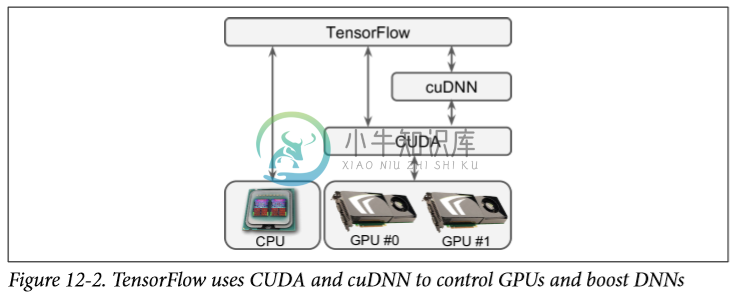
Nvidia 的 CUDA 允许开发者使用支持 CUDA 的 GPU 进行各种计算(不仅仅是图形加速)。 Nvidia 的 CUDA 深度神经网络库(cuDNN)是针对 DNN 的 GPU 加速原语库。 它提供了常用 DNN 计算的优化实现,例如激活层,归一化,前向和后向卷积以及池化(参见第 13 章)。 它是 Nvidia Deep Learning SDK 的一部分(请注意,它需要创建一个 Nvidia 开发者帐户才能下载它)。 TensorFlow 使用 CUDA 和 cuDNN 来控制 GPU 卡并加速计算(见图 12-2)。
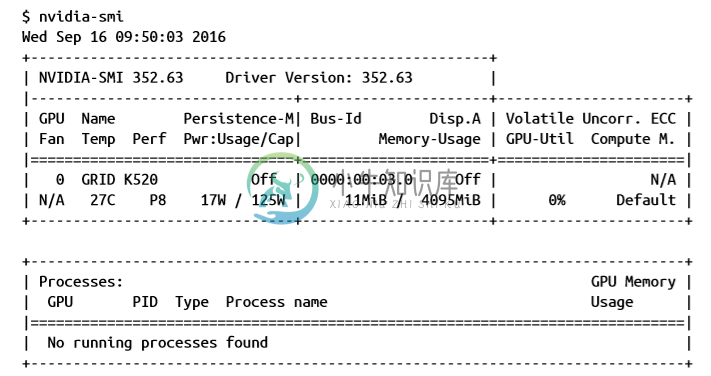
您可以使用nvidia-smi命令来检查 CUDA 是否已正确安装。 它列出了可用的 GPU 卡以及每张卡上运行的进程:
最后,您必须安装支持 GPU 的 TensorFlow。 如果你使用virtualenv创建了一个独立的环境,你首先需要激活它:
$ cd $ML_PATH # Your ML working directory (e.g., HOME/ml) $ source env/bin/activate
然后安装合适的支持 GPU 的 TensorFlow 版本:
$ pip3 install --upgrade tensorflow-gpu
现在您可以打开一个 Python shell 并通过导入 TensorFlow 并创建一个会话来检查 TensorFlow 是否正确检测并使用 CUDA 和 cuDNN:
>>> import tensorflow as tf
I [...]/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcudnn.so locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcuda.so.1 locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally
>>> sess = tf.Session()
[...]
I [...]/gpu_init.cc:102] Found device 0 with properties:
name: GRID K520
major: 3 minor: 0 memoryClockRate (GHz) 0.797
pciBusID 0000:00:03.0
Total memory: 4.00GiB
Free memory: 3.95GiB
I [...]/gpu_init.cc:126] DMA: 0
I [...]/gpu_init.cc:136] 0: Y
I [...]/gpu_device.cc:839] Creating TensorFlow device
(/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
看起来不错!TensorFlow 检测到 CUDA 和 cuDNN 库,并使用 CUDA 库来检测 GPU 卡(在这种情况下是 Nvidia Grid K520 卡)。
管理 GPU 内存
默认情况下,TensorFlow 会在您第一次运行图形时自动获取所有可用 GPU 中的所有 RAM,因此当第一个程序仍在运行时,您将无法启动第二个 TensorFlow 程序。 如果你尝试,你会得到以下错误:
E [...]/cuda_driver.cc:965] failed to allocate 3.66G (3928915968 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
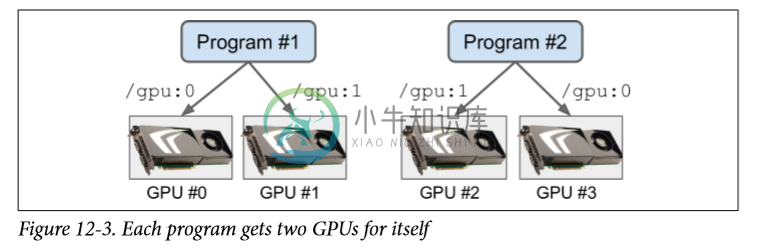
一种解决方案是在不同的 GPU 卡上运行每个进程。 为此,最简单的选择是设置CUDA_VISIBLE_DEVICES环境变量,以便每个进程只能看到对应的 GPU 卡。 例如,你可以像这样启动两个程序:
$ CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py
# and in another terminal:
$ CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py
程序 只会看到 GPU 卡 0 和 1(分别编号为 0 和 1),程序 只会看到 GPU 卡 2 和 3(分别编号为 1 和 0)。 一切都会正常工作(见图 12-3)。
另一种选择是告诉 TensorFlow 只抓取一小部分内存。 例如,要使 TensorFlow 只占用每个 GPU 内存的 40%,您必须创建一个ConfigProto对象,将其gpu_options.per_process_gpu_memory_fraction选项设置为 0.4,并使用以下配置创建session:
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
session = tf.Session(config=config)
现在像这样的两个程序可以使用相同的 GPU 卡并行运行(但不是三个,因为3×0.4> 1)。 见图 12-4。
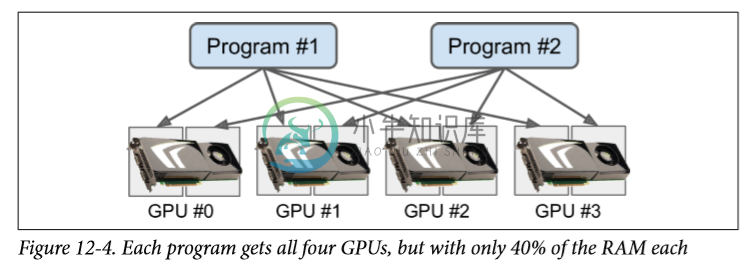
如果在两个程序都运行时运行nvidia-smi命令,则应该看到每个进程占用每个卡的总 RAM 大约 40%:

另一种选择是告诉 TensorFlow 只在需要时才抓取内存。 为此,您必须将config.gpu_options.allow_growth设置为True。但是,TensorFlow 一旦抓取内存就不会释放内存(以避免内存碎片),因此您可能会在一段时间后内存不足。 是否使用此选项可能难以确定,因此一般而言,您可能想要坚持之前的某个选项。
好的,现在你已经有了一个支持 GPU 的 TensorFlow 安装。 让我们看看如何使用它!
设备布置操作
TensorFlow 白皮书介绍了一种友好的动态布置器算法,该算法能够自动将操作分布到所有可用设备上,并考虑到以前运行图中所测量的计算时间,估算每次操作的输入和输出张量的大小, 每个设备可用的 RAM,传输数据进出设备时的通信延迟,来自用户的提示和约束等等。 不幸的是,这种复杂的算法是谷歌内部的,它并没有在 TensorFlow 的开源版本中发布。它被排除在外的原因似乎是,由用户指定的一小部分放置规则实际上比动态放置器放置的更有效。 然而,TensorFlow 团队正在努力改进它,并且最终可能会被开放。
在此之前,TensorFlow都是简单的放置,它(如其名称所示)非常基本。
简单放置
无论何时运行图形,如果 TensorFlow 需要求值尚未放置在设备上的节点,则它会使用简单放置器将其放置在未放置的所有其他节点上。 简单放置尊重以下规则:
- 如果某个节点已经放置在图形的上一次运行中的某个设备上,则该节点将保留在该设备上。
- 否则,如果用户将一个节点固定到设备上(下面介绍),则放置器将其放置在该设备上。
- 否则,它默认为 GPU#0,如果没有 GPU,则默认为 CPU。
正如您所看到的,将操作放在适当的设备上主要取决于您。 如果您不做任何事情,整个图表将被放置在默认设备上。 要将节点固定到设备上,您必须使用device()函数创建一个设备块。 例如,以下代码将变量a和常量b固定在 CPU 上,但乘法节点c不固定在任何设备上,因此将放置在默认设备上:
with tf.device("/cpu:0"):
a = tf.Variable(3.0)
b = tf.constant(4.0)
c = a * b
其中,"/cpu:0"设备合计多 CPU 系统上的所有 CPU。 目前没有办法在特定 CPU 上固定节点或仅使用所有 CPU 的子集。
记录放置位置
让我们检查一下简单的放置器是否遵守我们刚刚定义的布局约束条件。 为此,您可以将log_device_placement选项设置为True;这告诉放置器在放置节点时记录消息。例如:
>>> config = tf.ConfigProto()
>>> config.log_device_placement = True
>>> sess = tf.Session(config=config)
I [...] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
[...]
>>> x.initializer.run(session=sess)
I [...] a: /job:localhost/replica:0/task:0/cpu:0
I [...] a/read: /job:localhost/replica:0/task:0/cpu:0
I [...] mul: /job:localhost/replica:0/task:0/gpu:0
I [...] a/Assign: /job:localhost/replica:0/task:0/cpu:0
I [...] b: /job:localhost/replica:0/task:0/cpu:0
I [...] a/initial_value: /job:localhost/replica:0/task:0/cpu:0
>>> sess.run(c)
12
Info中以大写字母I开头的行是日志消息。 当我们创建一个会话时,TensorFlow 会记录一条消息,告诉我们它已经找到了一个 GPU 卡(在这个例子中是 Grid K520 卡)。 然后,我们第一次运行图形(在这种情况下,当初始化变量a时),简单布局器运行,并将每个节点放置在分配给它的设备上。正如预期的那样,日志消息显示所有节点都放在"/cpu:0"上,除了乘法节点,它以默认设备"/gpu:0"结束(您可以先忽略前缀:/job:localhost/replica:0/task:0;我们将在一会儿讨论它)。 注意,我们第二次运行图(计算c)时,由于 TensorFlow 需要计算的所有节点c都已经放置,所以不使用布局器。
动态放置功能
创建设备块时,可以指定一个函数,而不是设备名称。TensorFlow 会调用这个函数来进行每个需要放置在设备块中的操作,并且该函数必须返回设备的名称来固定操作。 例如,以下代码将固定所有变量节点到"/cpu:0"(在本例中只是变量a)和所有其他节点到"/gpu:0":
def variables_on_cpu(op):
if op.type == "Variable":
return "/cpu:0"
else:
return "/gpu:0"
with tf.device(variables_on_cpu):
a = tf.Variable(3.0)
b = tf.constant(4.0)
c = a * b
您可以轻松实现更复杂的算法,例如以循环方式用GPU锁定变量。
操作和内核
对于在设备上运行的 TensorFlow 操作,它需要具有该设备的实现;这被称为内核。 许多操作对于 CPU 和 GPU 都有内核,但并非全部都是。 例如,TensorFlow 没有用于整数变量的 GPU 内核,因此当 TensorFlow 尝试将变量i放置到 GPU 时,以下代码将失败:
>>> with tf.device("/gpu:0"):
... i = tf.Variable(3)
[...]
>>> sess.run(i.initializer)
Traceback (most recent call last):
[...]
tensorflow.python.framework.errors.InvalidArgumentError: Cannot assign a device to node 'Variable': Could not satisfy explicit device specification
请注意,TensorFlow 推断变量必须是int32类型,因为初始化值是一个整数。 如果将初始化值更改为 3.0 而不是 3,或者如果在创建变量时显式设置dtype = tf.float32,则一切正常。
软放置
默认情况下,如果您尝试在操作没有内核的设备上固定操作,则当 TensorFlow 尝试将操作放置在设备上时,您会看到前面显示的异常。 如果您更喜欢 TensorFlow 回退到 CPU,则可以将allow_soft_placement配置选项设置为True:
with tf.device("/gpu:0"):
i = tf.Variable(3)
config = tf.ConfigProto()
config.allow_soft_placement = True
sess = tf.Session(config=config)
sess.run(i.initializer) # the placer runs and falls back to /cpu:0
到目前为止,我们已经讨论了如何在不同设备上放置节点。 现在让我们看看 TensorFlow 如何并行运行这些节点。
并行运行
当 TensorFlow 运行图时,它首先找出需要求值的节点列表,然后计算每个节点有多少依赖关系。 然后 TensorFlow 开始求值具有零依赖关系的节点(即源节点)。 如果这些节点被放置在不同的设备上,它们显然会被并行求值。 如果它们放在同一个设备上,它们将在不同的线程中进行求值,因此它们也可以并行运行(在单独的 GPU 线程或 CPU 内核中)。
TensorFlow 管理每个设备上的线程池以并行化操作(参见图 12-5)。 这些被称为 inter-op 线程池。 有些操作具有多线程内核:它们可以使用其他线程池(每个设备一个)称为 intra-op 线程池(下面写成内部线程池)。
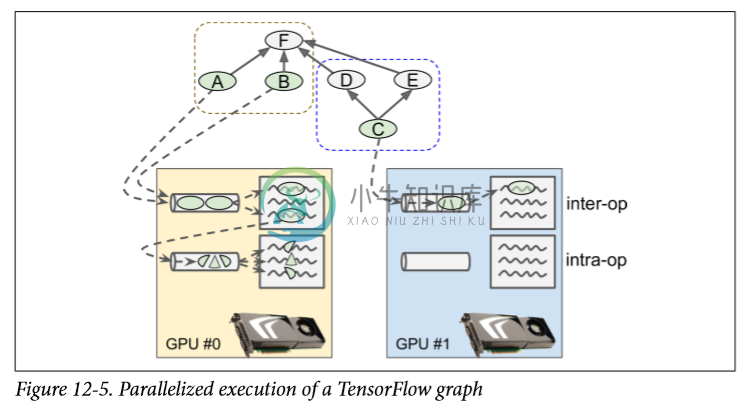
例如,在图 12-5 中,操作A,B和C是源操作,因此可以立即进行求值。 操作A和B放置在 GPU 上,因此它们被发送到该设备的内部线程池,并立即进行并行求值。 操作A正好有一个多线程内核; 它的计算被分成三部分,这些部分由内部线程池并行执行。 操作C转到 GPU 的内部线程池。
一旦操作C完成,操作D和E的依赖性计数器将递减并且都将达到 0,因此这两个操作将被发送到操作内线程池以执行。
您可以通过设置inter_op_parallelism_threads选项来控制内部线程池的线程数。 请注意,您开始的第一个会话将创建内部线程池。 除非您将use_per_session_threads选项设置为True,否则所有其他会话都将重用它们。 您可以通过设置intra_op_parallelism_threads选项来控制每个内部线程池的线程数。
控制依赖关系
在某些情况下,即使所有依赖的操作都已执行,推迟对操作的求值可能也是明智之举。例如,如果它使用大量内存,但在图形中只需要更多内存,则最好在最后一刻对其进行求值,以避免不必要地占用其他操作可能需要的 RAM。 另一个例子是依赖位于设备外部的数据的一组操作。 如果它们全部同时运行,它们可能会使设备的通信带宽达到饱和,并最终导致所有等待 I/O。 其他需要传递数据的操作也将被阻止。 顺序执行这些通信繁重的操作将是比较好的,这样允许设备并行执行其他操作。
推迟对某些节点的求值,一个简单的解决方案是添加控制依赖关系。 例如,下面的代码告诉 TensorFlow 仅在求值完a和b之后才求值x和y:
a = tf.constant(1.0)
b = a + 2.0
with tf.control_dependencies([a, b]):
x = tf.constant(3.0)
y = tf.constant(4.0)
z = x + y
显然,由于z依赖于x和y,所以求值z也意味着等待a和b进行求值,即使它并未显式存在于control_dependencies()块中。 此外,由于b依赖于a,所以我们可以通过在[b]而不是[a,b]上创建控制依赖关系来简化前面的代码,但在某些情况下,“显式比隐式更好”。
很好!现在你知道了:
- 如何以任何您喜欢的方式在多个设备上进行操作
- 这些操作如何并行执行
- 如何创建控制依赖性来优化并行执行
是时候将计算分布在多个服务器上了!
多个服务器的多个设备
要跨多台服务器运行图形,首先需要定义一个集群。 一个集群由一个或多个 TensorFlow 服务器组成,称为任务,通常分布在多台机器上(见图 12-6)。 每项任务都属于一项作业。 作业只是一组通常具有共同作用的任务,例如跟踪模型参数(例如,参数服务器通常命名为"ps",parameter server)或执行计算(这样的作业通常被命名为"worker")。
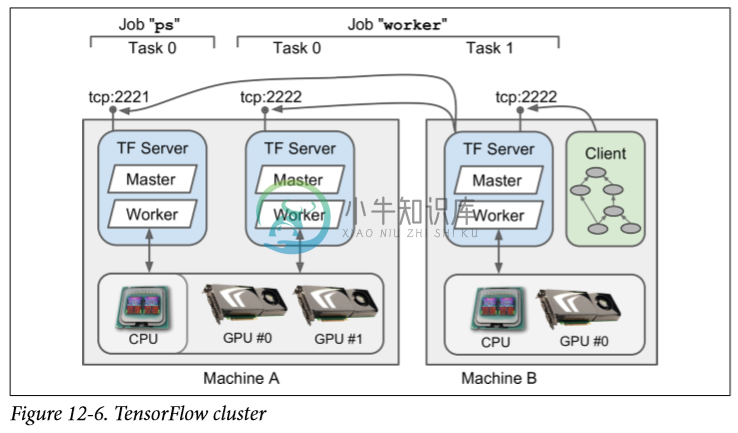
以下集群规范定义了两个作业"ps"和"worker",分别包含一个任务和两个任务。 在这个例子中,机器A托管着两个 TensorFlow 服务器(即任务),监听不同的端口:一个是"ps"作业的一部分,另一个是"worker"作业的一部分。 机器B仅托管一台 TensorFlow 服务器,这是"worker"作业的一部分。
cluster_spec = tf.train.ClusterSpec({
"ps": [
"machine-a.example.com:2221", # /job:ps/task:0
],
"worker": [
"machine-a.example.com:2222", # /job:worker/task:0
"machine-b.example.com:2222", # /job:worker/task:1
]})
要启动 TensorFlow 服务器,您必须创建一个服务器对象,并向其传递集群规范(以便它可以与其他服务器通信)以及它自己的作业名称和任务编号。 例如,要启动第一个辅助任务,您需要在机器 A 上运行以下代码:
server = tf.train.Server(cluster_spec, job_name="worker", task_index=0)
每台机器只运行一个任务通常比较简单,但前面的例子表明 TensorFlow 允许您在同一台机器上运行多个任务(如果需要的话)。 如果您在一台机器上安装了多台服务器,则需要确保它们不会全部尝试抓取每个 GPU 的所有 RAM,如前所述。 例如,在图12-6中,"ps"任务没有看到 GPU 设备,想必其进程是使用CUDA_VISIBLE_DEVICES =""启动的。 请注意,CPU由位于同一台计算机上的所有任务共享。
如果您希望进程除了运行 TensorFlow 服务器之外什么都不做,您可以通过告诉它等待服务器使用join()方法来完成,从而阻塞主线程(否则服务器将在您的主线程退出)。 由于目前没有办法阻止服务器,这实际上会永远阻止:
server.join() # blocks until the server stops (i.e., never)
开始一个会话
一旦所有任务启动并运行(但还什么都没做),您可以从位于任何机器上的任何进程(甚至是运行中的进程)中的客户机上的任何服务器上打开会话,并使用该会话像普通的本地会议一样。比如:
a = tf.constant(1.0)
b = a + 2
c = a * 3
with tf.Session("grpc://machine-b.example.com:2222") as sess:
print(c.eval()) # 9.0
这个客户端代码首先创建一个简单的图形,然后在位于机器 B(我们称之为主机)上的 TensorFlow 服务器上打开一个会话,并指示它求值c。 主设备首先将操作放在适当的设备上。 在这个例子中,因为我们没有在任何设备上进行任何操作,所以主设备只将它们全部放在它自己的默认设备上 - 在这种情况下是机器 B 的 GPU 设备。 然后它只是按照客户的指示求值c,并返回结果。
主机和辅助服务
客户端使用 gRPC 协议(Google Remote Procedure Call)与服务器进行通信。 这是一个高效的开源框架,可以调用远程函数,并通过各种平台和语言获取它们的输出。它基于 HTTP2,打开一个连接并在整个会话期间保持打开状态,一旦建立连接就可以进行高效的双向通信。
数据以协议缓冲区的形式传输,这是另一种开源 Google 技术。 这是一种轻量级的二进制数据交换格式。
TensorFlow 集群中的所有服务器都可能与集群中的任何其他服务器通信,因此请确保在防火墙上打开适当的端口。
每台 TensorFlow 服务器都提供两种服务:主服务和辅助服务。 主服务允许客户打开会话并使用它们来运行图形。 它协调跨任务的计算,依靠辅助服务实际执行其他任务的计算并获得结果。
固定任务的操作
通过指定作业名称,任务索引,设备类型和设备索引,可以使用设备块来锁定由任何任务管理的任何设备上的操作。 例如,以下代码将a固定在"ps"作业(即机器 A 上的 CPU)中第一个任务的 CPU,并将b固定在"worker"作业的第一个任务管理的第二个 GPU (这是 A 机上的 GPU#1)。 最后,c没有固定在任何设备上,所以主设备将它放在它自己的默认设备上(机器 B 的 GPU 设备)。
with tf.device("/job:ps/task:0/cpu:0")
a = tf.constant(1.0)
with tf.device("/job:worker/task:0/gpu:1")
b = a + 2
c = a + b
如前所述,如果您省略设备类型和索引,则 TensorFlow 将默认为该任务的默认设备; 例如,将操作固定到"/job:ps/task:0"会将其放置在"ps"作业(机器 A 的 CPU)的第一个任务的默认设备上。 如果您还省略了任务索引(例如,"/job:ps"),则 TensorFlow 默认为"/task:0"。如果省略作业名称和任务索引,则 TensorFlow 默认为会话的主任务。
跨多个参数服务器的分片变量
正如我们很快会看到的那样,在分布式设置上训练神经网络时,常见模式是将模型参数存储在一组参数服务器上(即"ps"作业中的任务),而其他任务则集中在计算上(即 ,"worker"工作中的任务)。 对于具有数百万参数的大型模型,在多个参数服务器上分割这些参数非常有用,可以降低饱和单个参数服务器网卡的风险。 如果您要将每个变量手动固定到不同的参数服务器,那将非常繁琐。 幸运的是,TensorFlow 提供了replica_device_setter()函数,它以循环方式在所有"ps"任务中分配变量。 例如,以下代码将五个变量引入两个参数服务器:
with tf.device(tf.train.replica_device_setter(ps_tasks=2):
v1 = tf.Variable(1.0) # pinned to /job:ps/task:0
v2 = tf.Variable(2.0) # pinned to /job:ps/task:1
v3 = tf.Variable(3.0) # pinned to /job:ps/task:0
v4 = tf.Variable(4.0) # pinned to /job:ps/task:1
v5 = tf.Variable(5.0) # pinned to /job:ps/task:0
您不必传递ps_tasks的数量,您可以传递集群spec = cluster_spec,TensorFlow 将简单计算"ps"作业中的任务数。
如果您在块中创建其他操作,则不仅仅是变量,TensorFlow 会自动将它们连接到"/job:worker",默认为第一个由"worker"作业中第一个任务管理的设备。 您可以通过设置worker_device参数将它们固定到其他设备,但更好的方法是使用嵌入式设备块。 内部设备块可以覆盖在外部块中定义的作业,任务或设备。 例如:
with tf.device(tf.train.replica_device_setter(ps_tasks=2)):
v1 = tf.Variable(1.0) # pinned to /job:ps/task:0 (+ defaults to /cpu:0)
v2 = tf.Variable(2.0) # pinned to /job:ps/task:1 (+ defaults to /cpu:0)
v3 = tf.Variable(3.0) # pinned to /job:ps/task:0 (+ defaults to /cpu:0)
[...]
s = v1 + v2 # pinned to /job:worker (+ defaults to task:0/gpu:0)
with tf.device("/gpu:1"):
p1 = 2 * s # pinned to /job:worker/gpu:1 (+ defaults to /task:0)
with tf.device("/task:1"):
p2 = 3 * s # pinned to /job:worker/task:1/gpu:1
这个例子假设参数服务器是纯 CPU 的,这通常是这种情况,因为它们只需要存储和传送参数,而不是执行密集计算。
(未完成)