
进一步探索分类 - 留一法
在数据挖掘领域,N折交叉验证又称为留一法。
上面已经提到了留一法的优点之一:我们用几乎所有的数据进行训练,然后用一个数据进行测试。
留一法的另一个优点是:确定性。
什么是确定性?
试想Lucy花了一整周的时间编写了一个分类器。周五的时候她请两位同事(Emily和Li)来对这个分类器进行测试,并给了他们相同的数据集。
这两位同事都使用十折交叉验证,结果是:

Emily:这个分类器的准确率是73.69%,很不错!
Li:它的准确率只有71.27%。
为什么她们的结果不一样?是某个人计算发生错误了吗?其实不是。
在十折交叉验证中,我们需要将数据随机等分成十份,因此Emily和Li的分法很有可能是不一样的。这样一来,她们的训练集和测试集也都不相同了,得到的结果自然不同。
即使是同一个人进行检验,如果两次使用了不同的分法,得到的结果也会有差异。
因此,十折交叉验证是一种不确定的验证。相反,留一法得到的结果总是相同的,这是它的一个优点。
留一法的缺点
最大的缺点是计算时间很长。
假设我们有一个包含1000条记录的数据集,使用十折交叉验证需要运行10分钟,而使用留一法则需要16个小时。如果我们的数据集更大,达到百万级,那检验的时间就更长了。

我两年后再给你检验结果!
留一法的另一个缺点是分层问题。
分层问题
让我们回到运动员分类的例子——判断女运动员参与的项目是篮球、体操、还是田径。
在训练分类器的时候,我们会试图让训练集包含全部三种类别。如果我们完全随机分配,训练集中有可能会不包含篮球运动员,在测试的时候就会影响结果。
比如说,我们来构建一个包含100个运动员的数据集:从女子NBA网站上获取33名篮球运动员的信息,到Wikipedia上获取33个参加过2012奥运会体操项目的运动员,以及34名田径运动员的信息。
这个数据集看起来是这样的:
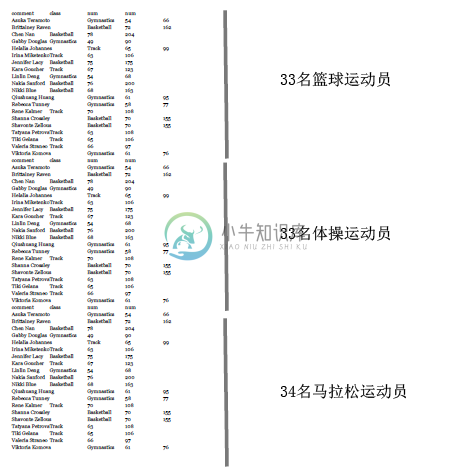
现在我们来做十折交叉验证。我们按顺序将这些运动员放到10个桶中,所以前三个桶放的都是篮球运动员,第四个桶有篮球运动员也有体操运动员,以此类推。
这样一来,没有一个桶能真正代表这个数据集的全貌。最好的方法是将不同类别的运动员按比例分发到各个桶中,这样每个桶都会包含三分之一篮球运动员、三分之一体操运动员、以及三分之一田径运动员。
这种做法叫做分层。而在留一法中,所有的测试集都只包含一个数据。所以说,留一法对小数据集是合适的,但大多数情况下我们会选择十折交叉验证。