
第4章 GDB
原文链接:http://www.aosabook.org/en/gdb.html
作者:Stan Shebs
GDB, 即GNU调试器(GNU Debugger)。它诞生自开源软件基金会(Free Software Foundation)成立之初的第一批程序,并一直是免费和开源软件系统中的主要成员。最初GDB只是Unix系统上一个简单的源码层次的调试器,代码量不过数千行C代码,后来逐步发展壮大,拓展到包括嵌入式系统在内多个平台,代码量也达到了上百万行。
GDB在发展,不断地满足着新的用户需求并增加新的功能。这一章将我们将介绍GDB的整体内部结构,探讨一下GDB是如何做到这一点的。
4.1 目标
GDB的设计目标是一个针对使用命令式(imperative)语言(例如C,C++,Ada,Fortran等)编写的程序的符号调试器。使用GDB原始命令行界面的一个示例如下:
% gdb myprog
[...]
(gdb) break buggy_function
Breakpoint 1 at 0x12345678: file myprog.c, line 232.
(gdb) run 45 92
Starting program: myprog
Breakpoint 1, buggy_function (arg1=45, arg2=92) at myprog.c:232
232 result = positive_variable * arg1 + arg2;
(gdb) print positive_variable
$$1 = -34
(gdb)
GDB能显示程序中的错误,开发者据此判断错误的类型并找到解决的方案。
设计GDB最需要考虑的是调试工具的交互性,因为用户在调试时提交的请求是不可预测的。此外,GDB还需要深入到系统最底层,因为编译器会充分利用硬件的各种选项来优化程序的性能。
GDB还要求能够调试不同编译器编译的程序(不仅仅是GNU C编译器),能够调试过时编译器编译的程序,能够调试符号信息丢失、过时或错误的程序。所以,另外一个设计要求是,即使程序中的数据丢失、损坏或干脆无法理解,GDB也能够继续工作并发挥作用。
接下来的几章假定读者熟悉GDB基本的命令行使用方法。如果你还是新手,建议先用一用GDB并细读一下手册[SPS+00]。
4.2 GDB的起源
GDB程序历史悠久,早在1985年就已经存在。它的作者是Richard Stallman,这个人还编写了GCC,GNU Emacs和其它一些早期的GNU软件。(由于当时并没有软件仓库,GDB开发过程的细节已不为人所知。)
GDB的最早的稳定版本在1988年发布,但在今天的GDB源码中已经找不到多少相似的地方了,GDB被完全重写过至少一次。 令人惊讶的是,早期的GDB并没有太大的野心,后来的平台移植和功能扩展并没有包括在GDB最初的计划之中。
4.3 GDB结构框图
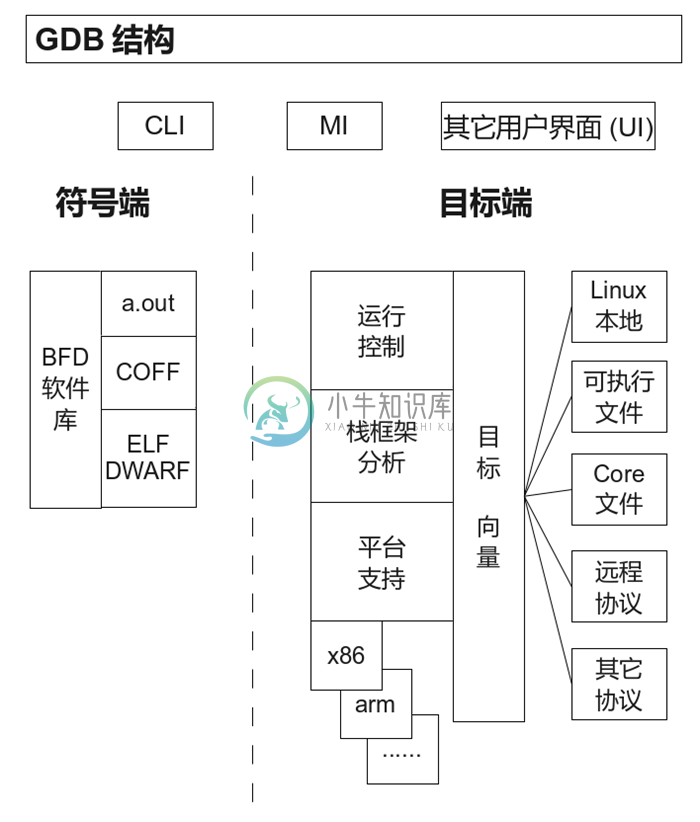 图4.1 GDB总体结构图
图4.1 GDB总体结构图
总体来讲,GDB内部结构可分为两大块:
- 符号端,涉及到程序的符号信息。符号信息包含函数名,变量名,变量类型,行号,机器寄存器使用情况,等等。符号端将程序可执行文件中的符号信息提取出来,解析表达式,找到指定行号的内存地址,列出源代码,并大体上获取程序中的文本信息。
目标端,涉及到目标系统的操控。目标端包含了基本的调试工具,包括启动和终止程序,读取或修改内存和寄存器,捕捉信号,等等。这些工具的实现在不同的系统上可能会相差很大。大部分Unix类操作系统上都提供了一个系统函数
ptrace,ptrace可以让一个进程读写另一个进程的状态。因此,GDB的目标端的主要工作就是调用ptrace和解析结果。对于嵌入式系统的交叉调试,过程有所不同,目标端通过数据线发送消息包,然后等待应答。这两大模块相互较为独立,用户可以查看程序的代码,显示变量类型,但不需要实际地运行程序。反过来,不用符号信息完全使用机器码调试也是可能的。
将符号端和目标端连接起来的中间层是命令解释器和主程序运行控制循环。
4.4 操作实例
为了解GDB各部分是如何协同工作的,不妨考虑一下前面示例中提到的print命令。命令解释器会搜索print命令函数,该函数将表达式转化为一个简单的树结构,通过遍历树结构来运算这个表达式。运算器会查询符号表,它发现positive_variable是一个全局整型变量,其存储地址是0x601028。随后,它会调用一个目标端中的函数来获取该地址中的4个字节内容,将结果传递给格式化函数,并显示为一个数字。
为了同步显示源码和对应的编译后代码,GDB同时读取源码文件和目标文件,然后使用编译器产生的行号信息将两者联系起来。在本例中,232行的地址是0x4004be,233行是0x4004ce,等等。
[...]
232 result = positive_variable * arg1 + arg2;
0x4004be <+10>: mov 0x200b64(%rip),%eax # 0x601028 <positive_variable>
0x4004c4 <+16>: imul -0x14(%rbp),%eax
0x4004c8 <+20>: add -0x18(%rbp),%eax
0x4004cb <+23>: mov %eax,-0x4(%rbp)
233 return result;
0x4004ce <+26>: mov -0x4(%rbp),%eax
[...]
单步执行命令step背后则稍为复杂。当用户使用step请求执行到下一行时,目标端只执行程序的一个指令后就再次暂停(ptrace支持类似的操作)。当获悉程序已经停止了,GDB读取程序计数器(PC, program counter)寄存器(另外一个目标端操作),并与符号端中记录的当前行的地址范围进行比较。如果程序计数器在这个范围之外,GDB允许程序停止,并获取新的代码行反馈给用户。如果程序计数器仍然在地址范围之内,GDB会重复执行指令和检查计数器的操作,直到程序计数器到达新的代码行。这个简单的算法保证了调试的逻辑正确性,无论当前行是跳转还是子函数调用都不会出错,而且也不要求GDB去理解机器指令集的所有细节。但不足之处是,一个单步执行命令(step)会产生与目标之间的多个交互过程。对于嵌入式调试,这个算法会导致单步执行变得很慢。
4.5 可移植性
由于需要大量地访问芯片上的物理寄存器,GDB最初的设计就考虑了面向不同系统的可移植性问题。 但是GDB的可移植性策略却是与时俱进的。
最初, GDB和当时的其它GNU程序一样, 使用C语言的最小子集编码, 结合预处理宏和Makefile脚本来适应特定的硬件结构和操作系统。 GNU项目的目标是完备的"GNU操作系统"(实际上,很多年之后Linux内核才问世), 因此其系统引导程序(bootstrapping)必须考虑多种已有平台。在面向多平台移植的过程中, configure脚本是第一个关键步骤。configure要做的事情很多,比如用符号链接将特定平台的文件统一为通用的头文件,比如从多个配置文件出发生成结果文件(在构建软件时,主要目标是生成Makefile文件)。
和cat,diff之类的程序一样,GCC和GDB也有额外的平台移植需求。随时间变化,GDB的可移植性问题分成了三类,每一类都有独立的Makefile脚本和头文件。
"主机(host)"定义。指GDB运行时所在的机器的信息,包含了主机整型大小等信息。原来这些头文件是手工编写的,渐渐地人们发现
configure可以自动完成这个工作。configure脚本会调用一些测试程序,这些测试程序与GDB使用的是同一个编译器。这些都是autoconf[aut12]的工作, 几乎所有的GNU工具和许多Unix程序都在使用autoconf来生成configure脚本。"目标(target)"定义。待调试程序所在的特定机器上的信息。如果目标机器和主机是同一台机器,这样的调试称为本地(native)调试,否则称为交叉(cross)调试(主机和目标机器通过数据线连接)。目标定义又分为两个主要类别:
- "结构(architecture)"定义:定义了如何分解机器码,如何访问调用堆栈,在断点处插入何种trap指令。最初这些工作由宏来完成,后来使用C语言编写的所谓"
gdbarch"对象(后面会进一步介绍)。 - "本地(native)"定义:定义了
ptrace的参数规范(不同Unix之间变化很大),如何搜索已加载的动态链接库,等等。本地定义只适用于本地调试的情况,它是从80年代的那些宏中遗留下来的,其它的都已经被autoconf取代了。
- "结构(architecture)"定义:定义了如何分解机器码,如何访问调用堆栈,在断点处插入何种trap指令。最初这些工作由宏来完成,后来使用C语言编写的所谓"
4.6 数据结构
在深入了解GDB各部分之前, 让我们先看看GDB主要的数据结构。作为一个C程序,GDB必然使用struct而非C++对象(object)。但是,struct也是可以视为对象(object)的,而GDB开发者也喜欢称其为对象, 那么我们也就入乡随俗了。
断点(breakpoint)
断点是用户能够直接访问得到的主要对象。用户使用break命令创建一个断点,其参数为断点的位置,位置可以是函数名,源码行号或机器地址。GDB为每个断点对象指定一个正整数作为其标识符,用户将通过这个正整数来操纵断点。在GDB中,断点是一个内容丰富的C语言结构体。位置信息会被翻译为机器地址,但仍然保留其原始形式,因为机器地址可能会发生变化(比如在不退出会话的情况下重新编译运行)。
还有其它一些断点类对象也使用断点的数据结构,包括观察点(watchpoint),捕捉点(catchpoint),跟踪点(tracepoint)。数据结构的共享保证了一些公共操作(创建,操纵和删除)对这些对象的通用性。
"位置"一词还可以指断点定义处的内存地址。对于inline函数和C++模板,用户定义的一个断点可能会对应到多个地址。比如当一个断点定义到inline函数上时,代码中所有使用这个函数的位置都会有断点存在。
符号和符号表
符号表是GDB中的核心数据结构, 它的数据量很大, 有时甚至会达到数G字节。 从某种意义上说, 这也是无法避免的。 每个局部变量,每种类型,每个枚举值,都是独立的符号。一个大型C++程序本身就包含了数百万个符号,而 它所引用的头文件同样会有数百万符号。
GDB使用了很多技巧来减少符号表占用的空间,比如使用不完全符号表(partial symbol table,后面会有介绍),在结构体中使用比特位,等等。
符号表的作用是建立字符串到地址和类型信息之间的映射,除此之外, GDB还建立了一些支持双向查询的行号表: 从源码行查询地址,从地址查询源码行。(早前介绍的单步执行算法就严重依赖于地址到源码的映射。)
栈帧
GDB支持的过程式语言运行时都有一个相似过程, 即函数调用会引起程序计数器,函数参数,以及局部参数的入栈。这些入栈数据的组合体称为"栈帧(stack frame)", 或简称"帧"。在程序执行的任何时刻,栈中都包含了多个串连在一起的帧。栈帧的细节取决于芯片体系结构,还和操作系统,编译器,以及优化选项有关系。
将GDB迁移到新的芯片时需要编写大量的代码来分析栈,因为用户程序(特别是带Bug的程序)可能在任何地方暂停运行,届时帧可能并不完整,部分甚至会被程序覆盖。更糟糕的是,为每个函数调用创建一个栈帧会影响程序效率,因而编译器在优化时会尽可能地简化栈帧,甚至完全消除(tail调用即是如此)。
对于特定芯片的栈的分析结果保存在一系列的帧对象中。最初,GDB使用一个固定帧指针寄存器来跟踪帧。但这个方法对inline函数调用以及其它编译器优化不起作用。从2002年开始,GDB开发人员引入了显式帧对象(explicit frame object)来记录每一帧的信息,这些显式帧对象链接在一起,并映射到程序的栈帧上。
表达式
对于栈帧,GDB假定它所支持的不同语言的表达式具有一定的共性,并将表达式表达为一个由结点对象构成的树结构。实际上, 结点的类型集合是所有不同语言中所有可能的表达式类型的一个联合。和编译器不一样,GDB允许Fortran变量和C变量之间的减法,虽然两种变量类型相差甚远并且结果会人大吃一惊。
值(value)
表达式计算得到的结果可能要比一个整数或内存地址更为复杂,GDB将这些结果保存在一个经过编号的历史列表中,以便在后面的表达式中能够访问得到。为实现这个功能,GDB有一个关于值(value)的数据结构。value结构体(struct)包含了大量的成员来记录其属性,包括标记这个值是左值还是右值(左值可以被赋值),以及这个值是否由懒构造(lazy construction)得到。
4.7. 符号端
GDB的符号端的功能主要是读取可执行文件,提取所有的符号信息,然后构造一个符号表。
读取可执行文件的首先要调用BFD软件库。 BFD是一个通用的处理二进制和对象(object)文件的软件库,支持从任意主机上读取Unix的a.out格式,COFF格式(用于System V Unix系统和微软Windows操作系统),ELF格式(用于现代Unix, GNU/Linux和大部分嵌入式系统),以及其它文件格式。BFD内部采用一个复杂的C语言宏,这个宏展开成代码之后能够深入到对象文件格式的复杂细节中去,而这些对象文件可能来自于几十个不同平台。BFD从1990年被引入到GNU汇编器和链接器,它对多种对象文件输出的支持成为跨平台开发的关键因素。(自然,将GDB移植到一个新的平台的首要条件是将BFD移植过去。)
GDB只用BFD来读取文件,将可执行文件中的数据块读到GDB的内存空间中去。GDB本身拥有两个层次的读入函数。第一个层次针对基本符号,或最简符号(minimal symbols),只包含了链接器需要的名称。这些基本符号只是一些带地址的字符串,在这一层次下,我们假定文本节(text section)中的地址都是函数,而数据节(data section)中的都是数据,依此类推。
第二个层次针对详细的符号信息,通常这种符号信息拥有与可执行文件不同的格式。例如,DWARF调试格式中的信息存储在ELF文件中单独命名的节(section)内。而Berkeley Unix系统中用到的旧的stabs调试格式将这些详细符号信息加上特别的标记后存储在通用符号表中。
阅读符号信息的代码非常无聊,因为不同的符号格式都需要将源码中的每个类型信息进行编码,而每一种符号格式的编码方式又都不一样。GDB的文件阅读器的工作就是扫描符号格式,将其转化为原来的形式。
不完全符号表
对于较大规模的程序(如Emacs或Firefox),建立符号表是比较费时的,有可能会达到几分钟的时间。实践表明文件加载时间倒不是主要的,主要是瓶颈在于内存中GDB符号的构造。一个程序中往往存在着上百万个小对象相互联系着,处理起来时间开销非常大。
大部分符号信息在一个GDB会话中从来不会用到,因为它们来自于函数的局部作用域。所以,GDB第一次导入程序的符号时,它先扫描一下符号信息,只把全局可见的符号存进符号表。当用户在某个函数内暂停运行时,这个函数的完整的符号信息才会动态加载进来。
在GDB中,不完全符号表使得大程序也能在数秒内启动。(动态链接库的符号也会动态加载,但过程完全不同。当动态链接库被加载时, 平台会通知GDB建立一个符号表,符号表中存储了动态链接地址对应的那些函数。这个过程取决于特定平台的消息机制,不同的平台会有所不同。)
语言支持
对源码语言的支持主要包括表达式解析和值的打印。表达式解析由语言自身负责,但一般来说表达式解析器是一个基于Yacc语法的词法分析器。为了让GDB在用户交互操作时具有更大的灵活性,解析器不需要对语法有严格的要求。比如,如果用户能合理地猜出来表达式的类型,那他就不需要显式地做类型转换。
GDB表达式解析器不需要考虑变量声明和类型声明,比完整的语言解析器要简单得多。类似的,值的打印,也只有考虑一部分类型的值,甚至还可以由特定语言的函数来实现。
4.8. 目标端
目标端的功能是操纵程序的执行和处理底层原始数据。从某种意义上讲,目标端是一个完全低层次的调试器。如果只是逐个指令调试并打印原始内存,用户根本就不需符号信息。(如果程序刚好在一个被剥离符号的软件库中暂停,你也只能使用这种模式。)
目标向量和目标向量栈
最初,GDB的目标端由一些特定平台上的文件组成,用于处理ptrace的调用,启动可执行文件等等。但这对于长时间运行的GDB会话来说是不够灵活的,因为用户可能会中途变化调试目标或方式,比如从本地调试切换到远程调试,从调试core文件切换到调试运行的程序,从附加(attach)线程变为分离(detach),等等。1990年,John Gilmore重新设计了GDB的目标端,使用目标向量来流水处理特定目标的操作。目标向量主要是由一类定义了目标系统特性的对象,每个目标向量是多个函数指针(通常称为"方法")构成的结构体,这些方法的功能包括读写寄存器内存,恢复程序运行,设置处理共享库时的参数。GDB中大概有40多个目标向量,包括有名的针对Linux的目标向量,以及不那么出名的操纵Xilinx MicroBlaze的目标向量。对Core dump的支持使用了一个从corefile中获取数据的目标向量,对应的,还有从可执行文件中获取数据的目标向量。
通常将几个目标向量混合使用比较有利。以在Unix上打印一个已初始化的全局变量为例,在程序开始运行之前,GDB也要能够支持对这个变量的打印,但这个时候进程并没有启动,数据只能从可执行文件的.data节(section)获取,所以GDB只能使用针对可执行文件的目标向量来读取二进制文件。但是如果程序已经运行,数据就应该从进程的地址空间中获取。这时候,GDB就会使用"目标向量栈",运行进程目标向量被推入栈顶,置于可执行文件目标向量之上,当进程退出时栈顶目标向量就会被弹出。
实际上,目标向量栈和你想像中的栈并不完全相同,目标向量之间并不是完全独立的。如果一个GDB会话同时调试一个可执行文件和一个运行进程,几乎总是让进程的方法覆盖可执行文件的方法。所以GDB提出"阶层(stratum)"的概念,令所有"进程类"的目标向量位于较高的阶层,而所有"文件类"的目标向量位于较低阶层,目标向量栈支持目标向量的推入(push)和弹出(pop),还支持插入操作。
(虽然GDB的维护者们并不怎么喜欢目标向量栈,但是还没有人能提出或实现更好的的方案。)
Gdbarch
因为程序直接和CPU的指令打交道,GDB需要深入了解芯片的细节,比如,所有的寄存器的信息,不同种类数据的大小,地址空间的大小和形状,调用约定是怎么工作的,什么指令会导致trap异常,等等。GDB中这一类工作的代码量取决于芯片的复杂度,从1000行到10000行的C代码都是有可能的。
最初,这个工作是由特定目标的预处理宏来完成的,但是随着调试器变得越来越复杂,这些宏变得越来越长,以致于不得不让部分宏变成了C函数(由其它宏来调用)。虽然这暂时减小了宏的复杂度,但是无助于解决平台的多样性问题(ARM或Thumb, 32位或64位, 64位MPIS或x86,等等)。更糟糕的是,多体系结构设计开始出现,对此,宏已经无能为力。1995年,我提出使用面向对象的设计来解决这个问题。从1998年开始Cygnus Solutions公司资助Andrew Cagney来开始实现这个设计。(Cygnus Solutions是一家1989年创立的提供免费软件商业支持的公司,2000年被Red Hat收购)。在几十个黑客数年的努力下,这个工作终于完成,其代码量大概有80000行。
新引入的结构称为gdbarch对象, 目前它包含了多达130个方法和变量来定义目标体系结构, 其实一个简单的目标平台也许只需要几十个。
为了比较其差异,我们来看一下"将x86平台下long doubles类型的大小定义为96"在新旧方式下分别是如何实现的:
gdb/i38-tdep.c中2012行处的代码(旧方式)
#define TARGET_LONG_DOUBLE_BIT 96
gdb/config/i386/tm-i386.h中2002行(新方式)
i386_gdbarch_init( [...] )
{
[...]
set_gdbarch_long_double_bit (gdbarch, 96);
[...]
}
运行控制
GDB的核心是运行控制循环, 前面描述单步执行一行代码时提到过这个名词: 用一个简单的循环,来判断指令是否运行到了下一行源代码。这个循环称为wait_for_inferior,或简称为wfi。
从概念上看, wfi位于主程序命令循环内部, 并且只有在程序恢复执行时才会进入wfi循环。当用户提交continue或step命令时,看起来似乎什么也没发生,其实这时候的GDB忙得很。除了前面提到的单步运行循环,程序还可能会执行到trap指令并将此异常汇报给GDB。如果遇到一个由断点引发的trap异常,GDB会判断这个断点的条件,如果条件为假,则移除此trap指令,继续执行单步运行循环,然后重新插入trap指令并令程序恢复执行。类似的,如果接收到一个信号,GDB可能会选择忽略,或根据预先指定的方式来处理。
所有这些活动都由wait_for_inferior来管理。最初wfi只是一个简单的循环,等待目标停止执行然后决定接下来怎么办,但移植到新的平台意味着增加新的需求,这个循环渐渐地增加到了1000行代码,而且变得难懂以至于不得不使用goto语句。随着增加对更多种Unix系统的支持,没有一个人能够理解所有的代码,也没有人能够对所有的代码进行回归测试。所以代码重构显得非常有必要,保留已有平台的行为然后使用goto语句跳过循环中的部分代码只是一个权宜之计。
这个庞大的循环在异步处理时也是有问题的。 因为,在调试多线程程序时, 用户需要在程序其它部分保持运行的同时调试某一个线程。
GDB从wfi转变为事件驱动模型花费了数年的时间。1999年,我将wait_for_inferior拆分开来,引入了一个执行控制状态结构体,取代本地和全局的大量杂乱的变量,并将复杂的跳转封装到一些小型独立的函数中。同时Elena Zannoni和其它人引入了事件队列,该队列的输入既包含用户的操作,还包括来自底层的通知。
远程协议
虽然GDB的目标向量体系允许在不同计算机上以多种方式来控制程序的运行, 但是我们倾向于使用单一的协议。这个协议并没有一个独立而准确的名称,它使用过的名称包括"远程协议(remote protocol)","GDB远程协议", "远程串行协议(Remote serial protocal, 简写为RSP)","远程C协议(用实现语言命名)",或"桩协议(stub protocol)",其实都是指目标系统对这个协议的实现。
基本的协议比较简单,主要面向19世纪80年代的小型嵌入式系统,其内存不过几千字节。GDB向所有的寄存器发出协议数据包$g,请求获得所有寄存器的所有内容,GDB假定这些寄存器的数目,大小和顺序都是已知的。
协议假定连接是可靠的,且每个发出去的数据包都能得到应答,在发包时只是加上一个检验和数字($g发送成$g#67)。
远程协议中必要的数据包类型并不多(对应于6个最重要的目标向量方法),但为了支持硬件断点,跟踪点(tracepoint)和共享库, 又逐步加入了数十个可选的数据包格式。
对于目标平台本身来说,远程协议可以以多种形式来实现。GDB的手册中有完整的协议文档,只要用户不违反GNU协议就可以实现自己的协议。事实上,许多设备制造商已经在实验或实践中实现了一些使用GDB远程协议的代码。比如,广为人知的Cisco的IOS,就一直运行在该公司的许多网络设备上。
目标平台对于远程协议的实现通常称为"调试桩(debugging stub)",或者简称为"桩(stub)",意指它不会独立完成任何工作。GDB的源码中包含了一些桩的示例代码,大约只有1000行左右的C代码。对于一个没有操作系统的电路板, 桩必须能够自己处理硬件异常, 特别是能够捕捉trap指令。如果硬件链接是串行的,它还需要有串行驱动的支持。实际的协议处理过程是比较简单的,因为所有必须的数据包都是单个字符,可以使用一个简单的switch语句来解码。
另外一个实现远程协议的方法是构建一个"sprite",作为GDB和调试硬件(包括JTAG设备,"wiggler"等)之间的接口。通常这些设备需要在与目标板相连的计算机上运行一个特殊的软件库,这个库的API往往与GDB内部结构不相容。所以,与其让GDB直接使用硬件控制库,还不如更简单地让sprite作为一个独立的程序运行,它能够理解远程协议并将数据包翻译成设备软件库函数。
GDBserver
GDB源码中已经包含了一个完整和可靠的目标端远程协议的实现: GDBserver。GDBserver是一个在目标操作系统上运行的本地程序,它响应通过远程协议接收到的数据包,控制目标操作系统上的其它程序来提供本地调试支持。换句话说,它类似于本地调试的一个代理。
GDBserver不做本地GDB能力范围之外的事,也就是说,如果目标系统可以运行GDBserver,那么理论上它也可以运行GDB。但是,GDBserver只有GDB软件规模的1/10,而且不需要管理符号表,所以用于嵌入式GNU/Linux之类的系统的调试是非常方便。
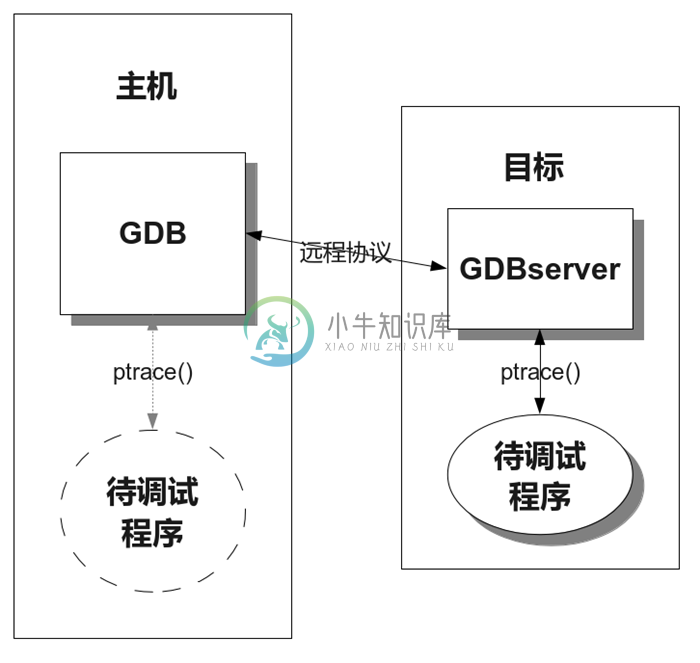 图4.2: GDBserver
图4.2: GDBserver
GDB和GDBServer共享相同的代码,虽然大家都知道要将平台依赖的控制代码封装起来,但是实际中GDB的这个迁移工作进展缓慢,因为将本地GDB中的依赖关系分离开来是比较困难的。
4.9. GDB界面
GDB本质上是一个命令行调试器。人们始终没有放弃尝试将其发展为一个图形窗口调试器,但是即使投入了大量的时间和努力,至今也没有一个得到广泛接受的方案。
命令行界面
命令行接口使用了标准的GNU软件库readline来处理GDB和用户之间的交互。readline用于命令行的编辑和自动补全,因而用户可以像使用光标一样在命令行中移动和修改。
GDB接收readline返回的命令,然后在一个瀑布型的命令表结构中查询这条命令,命令中每个后续单词会选择一个额外的表格。比如,"set print elements 80"使用了3个表格,第一个是包含了所有命令的表格,第二个是包含了set选项的表格,第三个是print选项的表格,其中elements选项用于控制打印一个集合体(如字符串或数组)中输出对象的个数。最后瀑布型表格将控制权交给一个实际的命令处理函数,命令的参数将传递给这个函数来解析。一些命令, 比如run, 处理参数的方式和传统C语言的argc/argv标准类似, 而其它一些命令, 比如print, 则假定参数是一个程序表达式, 并将其完整传递给源码解析器。
机器界面
一种GUI调试器方案是将GDB作为图形用户界面程序的后端,将鼠标点击翻译成GDB命令,然后将打印的结果显示在窗口中。这种方案已经在一些软件中实现,比如KDbg和DDD(Data Display Debugger)。但这个方法仍然不理想,因为有时候显示结果时为了可读性会省略掉一些细节,前端提供上下文的能力也会影响到结果的显示。
为解决这个问题,GDB提供了一个被称为机器界面(Machine Interface,MI)的接口。本质上MI仍然是一个命令行界面,但是命令和结果都增加了额外的语法,使得其意义更为显然:每个参数都使用了引号,复杂输出则使用定界符来分组,使用参数名来分块。此外, MI的命令还可以加上顺序标识符作为前缀, 并在结果中返回,保证了结果和命令的匹配。
为了比较两种界面, 分别给出它们对于同一命令的使用情况。下面是正常的step命令及GDB的响应
(gdb) step
buggy_function (arg1=45, arg2=92) at ex.c:232
232 result = positive_variable * arg1 + arg2;
With the MI, the input and output are more verbose, but easier for other software to parse accurately:
下面是MI的输入和输出,虽然显得有些冗余,但更加精确,便于第三方软件进行解析。
4321-exec-step
4321^done,reason="end-stepping-range",
frame={addr="0x00000000004004be",
func="buggy_function",
args=[{name="arg1",value="45"},
{name="arg2",value="92"}],
file="ex.c",
fullname="/home/sshebs/ex.c",
line="232"}
Eclipse[ecl12]开发环境是最著名的使用MI的调试环境。
其它用户界面
其它GDB前端软件包括基于tcl/tk的GDBtk或Insight,基于文字界面的TUI(最初由Hewlett-Packard开发)。GDBtk是一个传统的多面板图形用户界面,使用tk软件库开发,而TUI是一个在终端中使用的分屏文字界面。
4.10. 开发过程
维护者
作为一个GNU程序,GDB的开发遵循"大教堂(cathedral)"开发模型。GDB最初由Stallman编写,随后维护者几易其人,每个人都是身兼设计师,补丁审查员,发布管理员数职,他们有权访问仅向少数Cygnus雇员开放的源码仓库。
1999年,GDB被迁移到一个公共源码仓库,维护团队也扩展到了几十人,并且还有一些拥有签入(commit)权限的个人从旁协助。这个模式显著加速了GDB的开发,从原来的每周10个签入增加到了100个以上。
测试,测试
由于GDB高度依赖于特定平台,几乎涵盖全系列的计算设备,而且包含了数以百计的命令,选项以及使用风格,即使是一个经验丰富的GDB黑客也难以完全预料一个修改所产生的后果。
于是,测试套件变得举足轻重。GDB的测试套件包含了众多测试程序以及expect脚本,使用一个基于tcl被称为DejaGNU的测试框架。其基本模式是, 每个脚本驱动GDB去调试一个测试程序, 然后向其发送命令, 并使用模式匹配来判断结果正确与否。
这个测试套件还能进行交叉调试,既支持真实硬件也支持模拟器,它还能对于特定平台或配置进行测试。
到2011年底,GDB测试套件包含了大约18000个测试用例,包括了基本功能测试,语言特性测试,体系特性测试,和MI测试。所有这些测试都是通用的,适用于所有配置。GDB需要志愿者来测试打补丁后的源码,新的功能也需要新的测试。但是,因为没有人能在所有平台上测试同一修改,要实现测试的完全通过是不现实的。对于本地调试来说, 主干GDB测试时失败10-20次左右是可以授受的, 嵌入式系统则更容易出错。
4.11. 经验教训
开放是王道
GDB是"大教堂"开发模型的典范,在该模式下,维护者严密控制源码,而外部用户则跟踪其进度。补丁提交数目较少,封闭的开发过程实际上并不鼓励补丁。自从采用开放模式之后,补丁数量显著增多,而软件质量则一如既往,甚至更好。
制订计划, 但计划赶不上变化
开源软件开发过程实际上会比较混乱,因为开发者之间是松散的,流动性很大。
但是,制订开发计划并发布仍然很有意义。这有助于指导开发者完成相关任务,而且能够吸引潜在的赞助者,另外志愿者在尝试做出贡献时也能有一定的依据。
但是不要尝试设置截止时间,即使是每个人都热情地朝着一个方向努力,也不要指望大家都能全身心地投入并按时完成任务。
鉴于此,不要坚持一个已经过时的计划。长期以来,GDB都有重构为软件库libgdb的计划,这样, 别的程序就可以通过使用libgdb来实现一个拥有GUI的调试器。开发人员甚至尝试过将构建libgdb.a作为整个构建过程的一个中间步骤。虽然这个想法一直存在,但随着Eclipse和MI的成功,libgdb被搁置了起来,到2012年1月这个想法最终寿终正寝。
无比聪明该多好
看到曾经提交的修改,我们也许会想:为什么一开始不这么做呢? 唉,只因为我们不够聪明。
我们本可以预料到GDB会如此流行,并且会移植到数以百计的平台上,还支持本地和交叉调试。如果事先知道这些,说不定一开始就会使用gdbarch对象,而不会数年来都在用陈旧的宏和全局变量,目标向量也早该出现。
我们本可以预料到GDB将会被用到GUI中, 毕竟1986年Mac和X窗口系统已经出现了2年。与其设计一个传统的命令行界面,我们更应该让其支持异步事件处理。
然而,真正的教训不在于GDB开发者们有多蠢,而是我们不可能如此聪明地未卜先知。1986年, 窗口-鼠标风格的界面的未来还并不清晰, 我们预料不到它会像今天这样流行,如果第一个版本的GDB就设计为在GUI下使用,我们就可以称得上天才了,但这种好运不是人人都能有的。相反,在一个有限的范围内让GDB有所作为,我们已经为今后的扩展和重构打下了用户基础。
学会接受缺陷
尽力完成过渡,但是时间总是太快,你只能接受缺陷。
在2003年的GCC峰会上, Zack Weinberg哀叹GCC的"不完整过渡",新的底层结构已经引入,但是旧的却尾大不掉。GDB有着同样的问题,但是我们应该看到积极的一面,因为毕竟一些过渡已经完成,比如目标向量,gdbarch等等。虽然过渡需要多年来完成,调试却要一直继续。
谨防着迷于代码
当你遇到一个对你非常重要的项目,你会花费大量时间在单个代码上, 你会很容易沉迷其中,甚至为了迎合代码而改变自己的想法。但是,很有可能你已经误入歧途,退一步说不定海阔天空。
这样的事情要杜绝发生。
所有代码都源自于一系列清醒的判断:有些来自灵感,有些则不是。1991年节省空间的小伎俩对于2011年的数个G的内存来说是毫无意义的。
GDB曾经支持Gould超级计算机。当他们在2000年关闭最后一台机器时,保留对这种机器的支持已是毫无意义。那些代码只是GDB过往历史中的一些小小篇章,然而现在大部分的发行版中仍然有些"怀旧"。
事实上,很多激进的修改已经摆上日程或已经开展,包括对Python脚本的支持,对并行多核平台的支持,重编码为C++等。这些修改可能要花费数年,但其动机却来自于今天(等到它们完成时说不定已经过时)。