
第24章 VTK
原文链接:http://www.aosabook.org/en/vtk.html
作者:Berk Geveci 与 Will Schroeder
可视化工具箱(Visualization Toolkit, VTK)是一种广泛使用的数据处理与可视化软件系统。它应用于科学计算、医学影像分析、计算几何、渲染、图像处理以及信息学等领域。本章,我们展示一个VTK的简要概览,包括一些使之成为一个成功系统的基本设计模式。
要真正理解一个软件系统,关键之处不仅要理解它能够解决什么问题,而且还要了解它出现时的特定文化环境。在VTK的案例中,系统表面看起来要设计成用于科学数据的三维可视化系统。但VTK出现时的文化语境为奋斗者们添上了一个意义深远的背后故事,这有助于解释软件为什么是这样设计和部署的。
在VTK创生和开始编写之时,它的初始作者(Will Schroeder、Ken Martin、Bill Lorensen)还是GE研发部门的科研人员。我们向一个名为LYMB的先驱性系统投入了大量精力,该系统是一种以C实现的、类似Smalltalk的开发环境。在那个时代,它是一个伟大的系统,我们作为科研人员一再地被阻止在两大障碍上:1)IP问题(此处意指知识产权(Intellectual Property, IP)——译注。)和2)非标准的、有所有权的软件。IP问题之所以是个问题,是因为一旦GE公司的律师介入,那么尝试将软件向公司外部公布软件就几乎不可能了。第二,即使我们在GE公司内部部署软件,许多我们的用户也会受制于学习一个有所有权的、非标准系统,因为为了掌握它而作出的努力不能在他离开公司后转移到新的雇主那里;并且,这种软件没有标准工具集所提供的广泛支持。于是,VTK的原始动机就是开发一个开放标准,或曰“协作平台”,通过它,我们能够很容易地将技术传授给我们的用户。因此,为VTK选择一个开源许可证或许是我们所做出的最重要的设计决策。
最终选择了非互利的、自由的许可证(比如:选BSD(即BSD许可证(Berkeley Software Distribution License,BSD)。——译注。)而不选GPL(即GPL许可证(GNU General Public License)。——译注。))在事后证明是一个值得效仿的决策,因为它最终使基于商业的服务和咨询成为可能,而这正成就了Kitware。在我们做出这个决定的时候,我们最感兴趣的是降低与学术界、研究机构以及商务实体之间合作的壁垒。我们从那时也发现,许多组织都避免使用互利性许可证,由于它们可能造成的严重问题。事实上,我们可能会争论互利性许可证在延缓开源软件的接收上有很大作用,但这另当别论。这里的要点是:与任何软件系统相关的重要设计决策之一就是著作权许可证的选择。重新审视项目的目标,然后再恰当地解决IP问题是很重要的。
24.1 VTK是什么?
VTK最初是以一个科学数据可视化系统出现的。可视化领域之外的许多人都天真地把它当成一种特殊的几何渲染:查看虚拟物体并与之交互。尽管这些确实是可视化的一部分,但是通常的数据可视化还包括把数据转换成感知性输入的整个过程,典型的数据是图像,此外还包括触觉、听觉等其他形式。数据形式不仅由几何拓扑结构组成——比如像网格或者复杂空间分解等抽象形式,还有核心结构的属性,诸如标量(如:温度或压强),矢量(如:速度),张量(如:应力与张力),以及渲染属性,诸如表面法线和纹理坐标等。
注意,通常情况下,表示时空信息的数据被看做是科学可视化的一部分。然而,还有更抽象数据形式,比如市场统计资料、网页、文档以及其它信息,它们只能通过诸如非结构文档、表格、图和树等抽象(即:非时空)关系来表示。这些抽象数据一般通过信息可视化的方法来处理。在社区的帮助下,VTK现在能够完成科学可视化和信息可视化方面的工作。
作为一种可视化系统,VTK的角色是以这些形式获取数据,并最终将它们转换成利于人类感官理解的形式。因此,VTK的核心需求之一就是创建数据流管线的能力,这种管线能够读入、处理、表示并最终渲染数据。这样,工具箱就必须构建成一个灵活的系统,它的设计在许多层面上反映了这一点。例如,我们有目的地将VTK设计成这样一种工具箱,它具有许多可互换的组件,这些组件可以组合起来用于处理多种数据。
24.2 架构特性
在深入介绍VTK特殊的架构特性之前,先介绍顶层的概念,它们系统的开发和使用都产生了深远的影响。其中之一就是VTK的混合包装设施。该设施从VTK的C++实现自动生成Python,Java,和Tcl等的语言绑定(还可绑定更多的语言,并且有些已经实现了——译注)。最具实力的开发者将使用C++进行工作。使用者和应用程序开发者也可以使用C++,但是通常情况下,上文提到的解释性语言更加适合这两个群体。混合的编译性/解释性环境将这两个领域的优势结合在了一起:计算密集型算法的高性能和样机或开发的灵活性。事实上,这种多语言计算的方法在许多科学计算社区中得到广泛应用,并且许多团队将VTK作为他们自己软件的一个范本。
就软件过程而言,VTK采用CMake来控制构建过程;CDash/CTest用于测试;然后CPack用于跨平台部署。VTK确实可以在几乎任何计算机上进行编译,包括因其简陋的开发环境而声名狼藉的超级计算机。此外,开发工具外围还包括网页、wiki、邮件列表(用户区和开发者区),文档生成设施(即:Doxygen)和bug追踪系统(Mantis)。
24.2.1 核心特性
由于VTK是面向对象系统,在其内部,对类的访问和数据成员的实例化都被小心地管理起来。通常情况下,所有的数据成员的访问权限均为protected或private。通过Set和Get方法来访问这些数据成员,这两种方法具有各种类型的形参,例如:布尔型数据、模态数据、字符串、以及向量。这些方法中的多数的创建是通过向类的头文件中插入宏来实现的。例如:
vtkSetMacro(Tolerance, double);
vtkGetMacro(Tolerance, double);
可以展开为如下形式:
virtual void SetTolerance(double);
virtual double GetTolerance();
使用这些宏的原因已经超出了仅仅使代码清晰。VTK中有重要的数据成员控制调试、更新对象的修改时间(MTime)、并恰当地管理引用计数。这些宏正确地操作这些数据,因而强烈推荐使用它们。例如,当一个对象的修改时间没有得到恰当的管理时,VTK中就会出现一个尤其严重的bug。在这种情况下,代码就不会按其应该运行的方式运行,或者还会执行多次。
VTK的优势之一就是其相对简单的用于表示和管理数据的方法。典型的情况下,各种特殊数据(例如:vtkFloatArray)的数组用于表示信息的连续片段。例如:一个装载有三个三维坐标点的表可以用具有9个元素的vtkFloatArray来表示。这些数组有一种元组的记法,故有一个三维坐标点即一个3元组,而一个对称的3×3张量矩阵可以由一个6元组表示()。专门采用这种设计是因为在科学计算中,与操作数组的系统(例如:Fortran)接口是很常见的,并且这样还能使对大块连续数据的内存分配与回收变得更加高效。再者,连续数据的通信、串行、以及IO操作通常更有效率。这些(可以加载各种类型数据的)核心数据数组表示了VTK中的大部分数据,且具有多种方便的方法,以进行信息的插入和访问,包括用于快速访问的方法、以及在添加更多数据时所需要的自动分配内存的方法。数据数组是抽象类vtkDataArray的子类,该抽象类的意义在于:通用的虚方法可用于简化编码。但是,为了实现更高的性能,静态的、模版化的函数被引入,这样就可以根据不同的参数类型进行切换,并实现随后对连续数据数组的直接访问。
即使由于性能方面的原因,模板被广泛地使用,C++模板通常在公有类的API中也是不可见的。这点在STL中也是如此:我们采用了PIMPL设计模式来隐藏模版实现的复杂细节。这种模式为我们提供了很大帮助,尤其是在以前文所述将代码包装为解释性代码的时候。避免公有API中模板的复杂性意思是:在应用程序开发者看来,VTK实现大部分是无需考虑数据类型的选择的。当然,在其外壳之下,代码的执行是由数据类型来驱动的,而该数据类型则一般是运行时访问数据时确定的。
一些用户很想知道为什么VTK使用引用计数来管理内存而不是垃圾回收这一对用户来说更为友好的方式。基本的答案是当数据被删除的时候,VTK需要对其完全控制,因为要处理的数据量可能十分巨大。例如,一组1000×1000×1000字节的体数据的数据量是1G字节。把这么大的数据留在内存中等待垃圾回收器来决定是否应该释放它们,确实不是一个好主意。在VTK中,大部分类(vtkObject的子类)具有内建的引用计数能力。每个对象都包含有一个引用计数,它在该对象实例化时被初始化为1。每次使用该对象都会进行注册,然后引用计数就加1。类似地,当使用该对象进行了反注册(或者等效地认为该对象被删除),那么引用计数就会减1。最终的对象引用计数减至0,此时该对象自毁。下面列举一个典型的例子:
vtkCamera *camera = vtkCamera::New(); // reference count is 1
camera->Register(this); // reference count is 2
camera->Unregister(this); // reference count is 1
renderer->SetActiveCamera(camera); // reference count is 2
renderer->Delete(); // ref count is 1 when renderer is deleted
camera->Delete(); // camera self destructs
这里还有另外一个关于为什么引用计数对于VTK很重要的原因——它提供了有效复制数据的能力。例如:想象有一个数据对象D1,它由许多数据数组组成:点、多边形、颜色、标量、以及纹理坐标等。现在假设处理该数据来生成一个新的数据对象D2,此对象与第一个对象相同,还外加了向量数据(用于定位点)。一种浪费资源的方式是完全复制(深拷贝)D1来创建D2,然后向其中加入新的向量数据数组。另有一种方法,我们创建一个空的D2,然后将D1中的数组传给D2(浅拷贝),使用引用计数来追踪数据所有权,最终向添加新的向量数组。后者方法避免了复制数据,这正如前文所述,对一个优秀可视化系统是必不可少的。我们在本章的稍后内容中可以看到,数据处理的管线例行公事式地实现了这种运行机制,即:将数据从算法的数据复制至输出,此时引用计数对于VTK是必不可少的。
当然,引用计数也有一些臭名昭著的问题。偶尔会存在引用周期,这时循环中的对象以一种相互支持的配置来引用彼此。这种情况下,就需要明智的介入,或者在VTK中,一种在vtkGarbageCollector中实现的特殊设施就可以用来管理牵涉与上述循环中的对象。当这样的类被鉴别到的时候(这被期望发生在开发过程中),该类就会将其自身注册至垃圾回收器,并管理其自己的Register和Unregister方法的开销。然后紧接着的对象销毁(或者反注册)方法对局部的引用计数网络进行拓扑分析,搜索已经分离了的相互引用的对象群。这些都将被垃圾回收器予以删除。
VTK中的多数实例化过程是通过一种以静态类成员实现的对象工厂运行。典型的语义表达如下:
vtkLight *a = vtkLight::New();
这里要认识到的重要之处是:这里实际被实例化的可能不是vtkLight,可能是vtkLight的子类(例如:vtkOpenGLLight)。采用对象工厂的动机多种多样,最为重要的是应用的可移植性和设备不相关性。例如,前文中我们在一个渲染场景中创建了一个光源。在一个运行于特定平台上的特定的应用程序中,vtkLight::New可能会生成一个OpenGL光源,然而在不同的平台上,存在着图形系统中其他渲染库或方法来创建光源的可能性。到底实例化什么样的派生类是一种运行时系统信息的功能。在早期的VTK中,可以有包括gl、PHIGS、Starbase、XGL、以及OpenGL等多种选择。然而这些图形库中的多数现在已经消失了,出现了包括DirectX和基于GPU方法在内的新方法。随着时间的推移,一个利用VTK写成的应用程序没必要进行修改,因为开发者已经派生出了特定的对应于新设备的vtkLight的子类和其他渲染类来支持不断发展的技术。另外一个对象工厂的重要用处是使性能增强变动的运行时替换成为可能。例如,一个vtkImageFFT可能取代一个访问特种用途硬件或数值计算库的类。
24.2.2 数据表示
VTK的一个优点就是其表示数据复杂形式的能力。这些数据形式包括从简单表格到有限元网格之类的复杂结构。所有这些数据形式都是vtkDataObject的子类,如图24.1所示(注意这是数据对象类的继承图的一部分)。
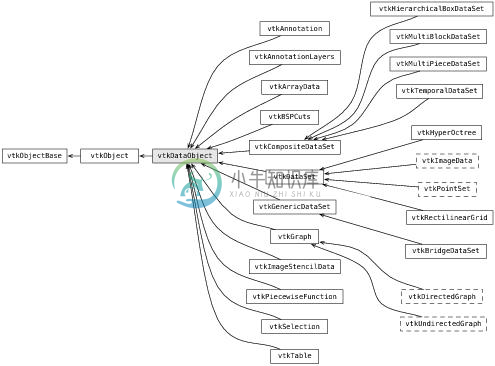
图24.1:数据对象类
vtkDataObject类的最重要的特点之一是它能被可视化管线(见下节)处理。上图展示的类中,只有一部分典型地应用于大多数实际的应用程序中。vtkDataSet及其派生类被用于科学可视化(见图24.2)。例如,vtkPolyData用于表示多边形网格;vtkUnstructuredGrid用于表示网格,而vtkImageData表示二维或者三维的像素和体素数据。
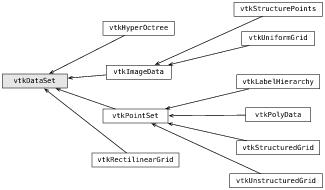
图24.2:数据集类
24.2.3 管线架构
VTK由若干主干子系统组成。与可视化包关联最紧密的子系统或许应该是数据流/管线架构了。从概念上讲,管线架构由三类基本对象组成:表示数据的对象(上文中的vtkDataObject),将数据从一种形式处理、变换、滤波或者映射成另外一种形式的对象(vtkAlgorithm),以及执行管线的对象(vtkExecutive)——此管线控制着一个由交错数据(?)和过程对象(即:管线)组成的连通图。图24.3展示了一个典型的管线。
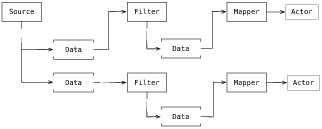
图24.3:典型的管线
尽管概念上很简单,但真正地实现这种管线架构却是挑战性的。一个原因就是数据的表示可能会很复杂。例如,某些数据集由层次化的或分组的数据组成,那么执行这种数据就需要特殊的迭代或递归。对于复合性的事务,并行处理(不论使用内存共享还是可扩展的、分布式的方法)需要将数据划分成片段,这些片段可能需要重叠,以一致地计算比如导数等的边界信息。
算法对象也同样引入了其自身的复杂性。某些算法可能需要多个输入并且/或者产生多个不同类型的输出。某些可以对数据进行局部运算(例如:计算一个网格的中心),而另外一些则需要全局性的信息,例如计算直方图。任何情况下,算法将其输入看作是不变量,算法只是读取输入、以求得输出。这是因为数据可能是多个算法的输入,一个算法可以践踏另外一个算法的输入可不是什么好主意。
最后,执行过程的复杂程度视执行策略的特点而定。有些场合,我们可能希望将滤波器之间的处理结果暂存。这将使那些如果管线发生变化就必须进行的重新计算量最小化。另一方面,可视化数据集可能很大,这种情况下我们可能希望在计算过程不再需要这些数据的时候释放它们。最后,有一些复杂的执行策略,例如数据的多分辨率处理,它需要管线以迭代的方式运行。
为了展示这些概念中的一部分,并进一步解释管线架构,来看下面的C++示例:
vtkPExodusIIReader *reader = vtkPExodusIIReader::New();
reader->SetFileName("example.exe");
vtkContourFilter *cont = vtkContour::New();
cont->SetInputConnection(reader->GetOutputPort());
cont->SetNumberOfContours(1);
cont->SetValue(0, 200);
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(cont->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOutputPort());
writer->SetFileName("outputFile.vtp");
writer->Write();
这个示例中,reader对象读取一个巨大的非结构网格(或网)数据文件。接下来的滤波器从该网格中生成一个等值面。vtkQuadricDecimation滤波器通过大量削减(即:减少表示等值围线的三角形的数量)来降低等值面的数据大小,该等值面是一个多边形数据集。最后大量削减后,新的减少了数据量的结果将被写回磁盘。实际的管线执行在writer调用Write方法的时候(即:需要数据的时候)发生。
正如这个示例所展示的,VTK的管线执行机制是实际要求驱使的。当一个像是writer或者mapper(一个数据渲染对象)的漏(sink)需要数据的时候,它就向其输入发出请求。如果作为输入的滤波器已经有了合适的数据,它就简单地向漏返回执行控制权。然而,若输入并没有合适的数据,它就需要进行计算。随后,它就必须先向它自己的输入请求数据。这个过程将会沿着管线继续上溯,直到有滤波器或者源拥有“合适的数据”或者到达了管线的始端,这时,滤波器就会按照正确的顺序依次执行,而数据就会沿管线流向请求需要它的地方。
这里我们将展开来讲什么是“合适的数据”。缺省情况下,VTK源或是滤波器执行后,其输出被管线缓存以避免将来不必要的执行。这样做是为了以存储为代价,使计算量和/或I/O最小化,这是可配置的行为。管线缓存的不仅是数据对象,还有关于这些数据对象生成的条件的元数据。这种元数据包括时间戳(即:计算时间),它捕捉这些数据对象何时被用于计算。因此,在最简单的情况下,“合适的数据”就是指从其开始上溯的所有管线对象变动之后被计算得出的数据。通过下面的示例展示这种特征更容易。我们在上面的VTK程序的最后加入如下代码:
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOutputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
如前文所述,第一个writer->Write调用引发整个管线的执行。当writer2->Write被调用时,管线将缓存的时间戳与削减滤波器、围线滤波器以及reader的变动时间对比后会发现削减滤波器的输出缓存是即时的。于是,数据请求无需传播的远于writer2。现在,我们来考虑下面的变化。
cont->SetValue(0, 400);
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOutputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
现在,管线执行对象会发现围线滤波器在围线滤波器和削减滤波器的输出最后一次被执行之后又发生了变动。因此,这两个滤波器的缓存就是过时的,它们需要重新执行。然而,鉴于reader在围线滤波器之前就发生了变动,所以它的缓存是有效的,因此reader不需要重新执行。
这里描述的场景是要求驱动的管线系统的最简单的例子。VTK管线远比此复杂。当滤波器或者漏请求数据,它可以提供附加的信息以请求特殊的数据子集。例如,一个滤波器可以通过数据的流片段进行核心外分析。我们通过修改之前的示例来展示。
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOutputPort());
writer->SetNumberOfPieces(2);
writer->SetWritePiece(0);
writer->SetFileName("outputFile0.vtp");
writer->Write();
writer->SetWritePiece(1);
writer->SetFileName("outputFile1.vtp");
writer->Write();
这里writer请求管线的上游载入并以两个片段来处理数据,每个片段独立地流向下游。你可能会注意到之前所述的那种简单的执行逻辑在这里行不通了。根据这种逻辑,Write函数第二次被调用时,管线不应该重新执行,因为上游没有发生任何变动。于是为了着力解决这一更加复杂的情况,执行对象具有附加的逻辑以处理这里所说的片段请求。VTK管线执行事实上由多重关卡组成。数据对象的计算实际上最后一关。这一关之前是请求关。这里是漏和滤波器告诉上游它们需要从即将进行的计算中获得什么数据的地方。在上面的示例中,writer将会提醒它的输入,它需要两个片段中的第0个。这一请求实际上会沿路传播到reader。当管线执行时,reader就会知道它需要读取一个数据的子集。再者,关于缓存数据对应的是哪个片段的信息存储于对象的元数据中。下次滤波器向其输入请求数据时,这个元数据就会被与当前请求作比较。于是该示例中的管线就会重新执行,以处理一个不同的片段请求。
滤波器可以发出若干更多类型的请求。这些请求包括特定时间戳的请求、特殊结构化范围的请求、或者幽灵层数量的请求(即:用于计算邻域信息的边界层)。此外,在请求通过的过程中,每一个滤波器都允许修改来自下游的请求。例如,一个无法通行流的滤波器(例如:流水线滤波器)可以忽略片段请求并要求整个数据。
24.2.4 渲染子系统
乍看VTK拥有一个简洁的面向对象的渲染模型,这个模型由对应于构建三维场景的组件的类组成。例如:vtkActor是由与vtkCamera结合在一起的vtkRenderer来渲染的对象,一个vtkRenderWindow中可能具有多个vtkRenderer。该场景由一个或多个vtkLight提供光照。每个vtkActor的位置由vtkTransform控制,而该演员的外观则通过vtkProperty来制订。最后,该演员的几何表示由vtkMapper来定义。映射在VTK中扮演着重要的角色,它们用于数据处理管线的结尾,同时向渲染系统提供接口。考虑下面的例子,我们在这个例子中大幅削减数据,然后将结果写入一个文件,最后通过映射将其可视化,并实现与该结果的交互。
vtkOBJReader *reader = vtkOBJReader::New();
reader->SetFileName("exampleFile.obj");
vtkTriangleFilter *tri = vtkTriangleFilter::New();
tri->SetInputConnection(reader->GetOutputPort());
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(tri->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkPolyDataMapper *mapper = vtkPolyDataMapper::New();
mapper->SetInputConnection(deci->GetOutputPort());
vtkActor *actor = vtkActor::New();
actor->SetMapper(mapper);
vtkRenderer *renderer = vtkRenderer::New();
renderer->AddActor(actor);
vtkRenderWindow *renWin = vtkRenderWindow::New();
renWin->AddRenderer(renderer);
vtkRenderWindowInteractor *interactor = vtkRenderWindowInteractor::New();
interactor->SetRenderWindow(renWin);
renWin->Render();
这里只有一个演员,渲染器 和 渲染窗与映射一同创建,该映射将管线与渲染系统连接起来。也要注意vtkRenderWindowInteractor的引入,其实例捕捉鼠标与键盘事件,并将之转换为摄像机操作以及其它动作。这一转换过程由vtkInteractorStyle进行定义(下文还会就此详述)。缺省情况下,许多实例和数据值被置于场景之后。例如:创建了恒等变换,以及一个单独的光源和性质。
随着时间的推进,该对象模型变得更加复杂。多数复杂性来源于开发派生类,这些派生类用于具体指定渲染过程中的某一方面。vtkActor目前是vtkProp的特例(prop正如戏台上的道具),而且还有一群这样的道具用于渲染二维的图形叠加和文本,指定三维物体,甚至用于支持诸如体绘制或GPU实现等的高级渲染技术(见图24.4)。
类似地,随着VTK支持的数据模型的增长,各式用于实现数据于渲染系统接口的映射也随之出现。另外一个发生显著扩展的领域是变换的层次结构。这里最初只有一个简易的4×4变换矩阵,现在变成了一个强悍的类层次结构,它们支持包括薄板样条变换(thin-plate spline transformation)在内的非线性变换。例如:原始的vtkPolyDataMapper拥有支持具体设备的子类(如:vtkOpenGLPolyDataMapper)。近几年,它已经被图24.4所展示的一种称为“painter”的复杂的图形学管线所取代。
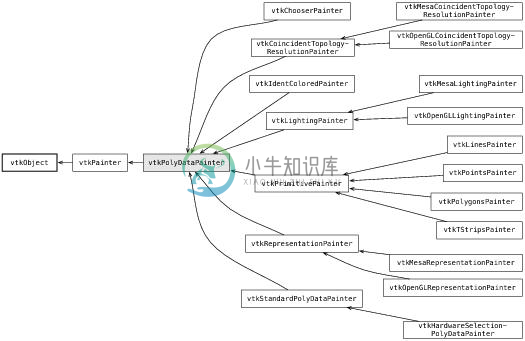
图24.4:显示功能类
painter的设计支持一大类渲染数据的技术,这些技术能够组合起来以提供特殊的渲染效果。这种能力远远超出了于1994年最初实现的简易的vtkPolyDataMapper。
可视化系统的另外一个重要方面是子系统的选择。在VTK中,有一个类层次picker,被粗略地分成两类对象:一类对象根据与硬件相关方法和软件方法作比对来选择vtkProp(例如:ray-casting);另一类对象在一次picker运算之后,提供不同水平的信息。例如:一些picker仅提供XYZ世界空间的位置,而不指明它们选择了哪个vtkProp;其它picker不但给出所选的vtkProp,还给出组成用于定义道具几何特征网格的具体的点或单元。
24.2.4 事件与交互
与数据交互是可视化的关键一环。在VTK中,交互的方式有多种。最简单的方式是,用户通过命令观察事件并做出合适的反应(命令模式/观察者模式)。vtkObject的所有子类都保有一列观察者,这些观察者将其自身寄存于对象中。寄存过程中,观察者指出其感兴趣的特殊事件,并加入关联的命令,此命令将在事件发生时被调用。为了说明这一工作原理,来考虑下面的例子,该例中有一个带有观察者的滤波器(本例中是一个多边形削减滤波器),此观察者观察三种事件:StartEvent,ProgressEvent,和EndEvent。这些事件在这三种情况下被该滤波器所调用:滤波器开始执行时,滤波器执行过程中(周期性调用),以及滤波器执行结束时。下面的代码中,vtkCommand类拥有一个Execute方法,该方法用于打印与该类执行算法所花费时间有关的恰当信息。
class vtkProgressCommand : vtk Command
{
public:
static vtkProgressCommand *New() { return new vtkProgressCommand; }
virtual void Execute(vtkObject *caller, unsigned long, void *callData)
{
double progress = *(static_cast<double*>(callData));
std::cout << "Progress at " << progress << std::endl;
}
};
vtkCommand* pobserver = vtkProgressCommand::New();
vtkDecimatePro *deci = vtkDecimatePro::New();
deci->SetInputConnection( byu->GetOutputPort() );
deci->SetTargetReduction( 0.75 );
deci->AddObserver( vtkCommand::ProgressEvent, pobserver );
尽管这是交互的一种原始形式,它也是许多使用VTK的应用程序的基本要素。例如:上述的简短代码可以很容易地转换、用于显示并管理图形界面中的进度条。这一命令/观察者子系统也是VTK中三维挂件的核心,这些挂件是用于数据的请求、操纵以及编辑的复杂的交互性对象,下文将予以描述。
提到上面的例子,很重要的一点是,VTK中的事件都是预定义的,但是这里也为自定义事件开了后门。vtkCommand类定义了一组枚举型事件(例如:上面例子中的vtkCommand::ProgressEvent)以及一个用户事件。UserEvent只是一个整形数值,一般用作一组应用程序中自定义事件的起始抵消值。于是,vtkCommand::UserEvent+100可能是指一个VTK预定义的事件之外的某个事件。
从用户的角度来看,一个VTK挂件可以看作是场景中的一个演员,只是用户可以通过操纵句柄或者其它几何特性(句柄操纵与几何特性操纵均是基于前文所述之抓取功能——原文:picking functionality,即24.2.4一节中最后一段所述——的)来与之交互。与挂件的交互是很直观的:用户抓住球面句柄并将其移动,或者抓住一条直线并将其移动。然而,在场景的背后,事件被发送出去(例如:InteractionEvent),而一个编写合理的应用程序就能够观察到这些事件,并采取恰当的行动。例如,它们通常由下面所给出的vtkCommand::InteractorEvent所触发:
vtkLW2Callback *myCallback = vtkLW2Callback::New();
myCallback->PolyData = seeds; // streamlines seed points, updated on interaction
myCallback->Actor = streamline; // streamline actor, made visible on interaction
vtkLineWidget2 *lineWidget = vtkLineWidget::New();
lineWidget->SetInteractor(iren);
lineWidget->SetRepresentation(rep);
lineWidget->AddObserver(vtkCommand::InteractionEvent, myCallback);
实际上,VTK挂件由两个对象构建而成:一个是vtkInteractorObserver的子类,另一个是vtkProp的子类。vtkInteractorObserver只是观察渲染窗中的用户交互(例如:鼠标事件和键盘事件)并处理之。这些操纵通常由突出显示句柄,改变鼠标指针的外观,以及变换数据等所组成,它们都会修改vtkProp的几何特征。当然,这些挂件的特殊细节要求编写子类来控制其行为的细微差别,目前系统中拥有50多个不同的挂件。
24.2.4 库的总结
VTK是一个大型软件工具箱。目前,系统由大约1500万行代码(包括注释,但是不包括自动生成的包裹层软件),约1000个C++类组成。为了管理系统的复杂度并减少构建和链接的时间,系统被分割放置在十几个子路径中。表24.1列出了这些子路径,并简要总结了这些库所提供的功能。
Common | VTK核心类 |
Filtering | 用于管理管线数据流的类 |
Rendering | 渲染,抓取,查看图像,以及交互 |
VolumeRendering | 体绘制技术 |
Graphics | 三维几何处理 |
GenericFiltering | 非线性三维几何处理 |
Imaging | 图像处理管线 |
Hybrid | 同时要求使用图形学和图像处理功能的类 |
Widgets | 复杂的交互 |
IO | VTK的输入和输出 |
Infovis | 信息可视化 |
Parallel | 并行处理(控制器和通信器) |
Wrapping | 对Tcl,Python以及Java的包裹的支持 |
Examples | 内容广泛、文档良好的示例 |
表24.1:VTK的子路径
24.3 回顾与展望
VTK一直是一个非常成功的系统。虽然第一行代码于1993年写出,但是目前,VTK仍然在不断成长壮大、其开发速度也在不断加快2。本节,我们将谈谈一些经验和将来的挑战。
24.3.1 成长管理
VTK发展历程中,最令人惊叹的方面之一就是项目的寿命。开发的速度归因于若干主要原因:
- 新算法和功能被持续不断地加入。例如,信息学子系统(Titan,最初由Sandia国立实验室和Kitware软件共同开发)是最近加入的一个重要的部分。额外的绘图和渲染类也同时加入进来,还有新的科学数据类型功能。另外一个加入的重要部分是三维交互挂件。最后,基于GPU的渲染以及数据处理的持续演进正在催生新的VTK功能。
- VTK不断增多的曝光和使用是一个自我保持的过程,该过程向社区加入了更多的使用者和开发者。例如,ParaView是最受欢迎的基于VTK的科学可视化应用程序,并且受到了高性能计算社区的高度重视。3D Slicer是主要的生物医学计算平台,它大部分也建立于VTK之上,并且每年受到数百万美元的资助。
- VTK的开发过程持续演进。近年来,CMake、CDash、CTest、以及CPack等软件过程工具已经集成到了VTK的构建环境中。最近,VTK的代码库已经迁移至Git和一个更为复杂的工作流。这些改进确保VTK保持科学计算社区内软件开发的领先地位。
虽然成长是令人兴奋的,确证软件系统的建立,预测VTK的未来,但妥善的管理却是极其困难的。因此,近期VTK将更多地专注于管理社区以及软件的成长。为此,已经采取了若干措施。
首先,创立了正式的管理架构。创建了架构审查委员会(Architectural Review Board),来指导社区和技术的发展,专注于高层次的、战略性的议题。VTK社区也正在组建一个由意见领袖组成的公认的团队,来指导某些VTK子系统的技术开发。
其次,制定了关于更进一步使工具箱模块化的计划,尤其是应对由git引入的工作流功能,还认识到使用者和开发者一般都想在工作中使用工具箱中小的子系统,并且不想构建并链接整个包。此外,为了支持不断成长的社区,对新的功能和子系统的支持是很重要的,即使它们并不一定是工具箱的核心部分。通过创建松散的、模块化的一群模块,在维持核心的稳定性的同时,适应外围的大量代码贡献是可能的。
24.3.2 技术整合
除了软件过程之外,在开发管线当中还有许多技术创新。
- 共同处理是这样一种功能,可视化引擎被集成于仿真代码之中,而且周期性地提取生成用于可视化的数据。这一技术极大地降低了完整解决方案数据的大的输出数据量。
- VTK中的数据处理管线还是太复杂。正在寻求简化和重构这些子系统的方法。
- 直接与数据交互的能力正在使用者中间流行。尽管VTK拥有一大票挂件,但是更多的交互技术正在不断涌现,包括基于触摸屏的方法和三维方法。交互技术将会继续快速开发。
- 计算化学对于材料设计人员和工程师的重要性正在不断提升。对化学数据的可视化与交互的功能正在加入VTK。
- VTK的渲染系统素来因其过于复杂而饱受诟病,这使它难以派生出新的类或者支持新的渲染技术。此外,VTK不直接支持场景图概念,这同样也是许多使用者要求过的功能。
- 最后是数据的新形式不断出现。例如,在医疗领域,变分辨率的层次化体数据(如:具有局部放大的共焦显微镜影像)。
24.3.3 开放科学
最后,Kitware和更加广泛的VTK社区决定加入Open Science。从务实的角度讲,它一个这样的方式,我们将传播公开的数据、公开的发表、以及公开的源代码——这是确保我们正在创建可重现的科学系统所必需的特征。虽然VTK一直以来都以开源和公开数据的系统的形式传播,但是文档过程却一直缺乏。在拥有正式书籍[Kit10,SML06]的同时,还一直有各种非正式的方法来收集包括新的源码在内的技术发表物。我们正在通过开发像是VTK Journal3的新的发表机制来改善这种状况,该期刊可以发表由文档、源代码、数据、以及有效的测试图像组成的文章。它还实现了自动化的代码审查(利用VTK的高质量的软件测试过程)以及人对递交文章的审查。
24.3.4 经验教训
虽然VTK很成功,但是还有许多事情我们没有处理好:
- 设计的模块性。我们在选择我们的类的模块性上做得不错。例如,我们不会做类似为每个像素都创建一个对象的这种傻事,而是创建了高层次的
vtkImageClass,它内部处理像素数据组成的数组。然而,在某些情况下,我们不得不将之重构为小的片段,并继续这一过程。一个基本的例子就是数据处理管线。最初,数据管线是通过数据和算法对象的交互而隐式实现的。我们最终认识到我们得创建一种显式的管线执行对象来协调数据与算法之间的交互,并且用于实现不同的数据处理策略。 - 遗漏的关键概念。我们曾经的最大遗憾就是没有广泛的利用C++的迭代器。在许多情况下,VTK中的数据的遍历与科学编程语言Fortran十分类似。迭代器所提供的额外的灵活性本来可能对系统有很大帮助。例如,在处理局部区域的数据,或者仅仅是那些满足某种迭代准则的数据时,这是极具优势的。
- 设计上的问题。当然,有一长列非最优的设计决策。我们同数据处理管线斗争,已经经历了许多代,每次都设计得更好些。渲染系统也是很复杂的,并且难以从其中派生出新类。另外一个由VTK的最初概念所引起的挑战是:我们将其看作是用于观察数据的只读可视化系统。然而,目前的客户经常希望它能够编辑数据,这就需要完全不同的数据结构。
像VTK这样的开源系统的好处之一是许多这些错误能够并且将会随着时间而得以纠正。我们拥有一个积极的、有能力的开发社区,他们每天都在改进着这个系统,并且我们希望在可预见的将来,这一状态能够维持下去。
脚注
1. http://en.wikipedia.org/wiki/Opaque_pointer.
2. See the latest VTK code analysis at http://www.ohloh.net/p/vtk/analyses/latest.
3. http://www.midasjournal.org/?journal=35.