
第3章 The Bourne-Again Shell
原文链接: http://www.aosabook.org/en/bash.html
作者: Chet Ramey
3.1 介绍
Unix Shell提供了一个接口,支持用户通过命令与操作系统进行交互。但shell同时也算得上是一门丰富的编程语言,因为它包含了基本的流程控制结构: 替换(alternation),循环,条件判断,还有基本的数学操作,函数定义,字符串变量,以及与命令之间的双向通信。
shell可以在终端或终端模拟器(如xterm)中以交互的方式运行,也可以存储在文件中作为脚本来使用。大部分现代shell环境(包括Bash)提供命令行编辑功能,用户可以使用Emacs或Vi风格的快捷键来编辑命令行,或访问命令的历史纪录。
Bash的处理过程类似于shell的流水线(pipe):首先由终端或脚本读入数据,然后使用一系列变换过程依次进行处理,执行到最后一个shell命令后返回。
本章将讨论Bash的主要组件:输入处理,解析,单词展开(word expansion)和其他命令处理,管道(pipeline)中的命令执行。这些组件构成一个流水线(pipeline),从键盘或脚本中获取字符,然后逐步转化为命令。
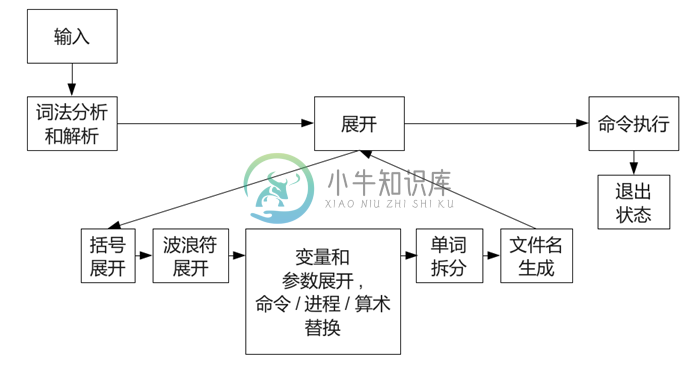 图3.1 Bash组件结构
图3.1 Bash组件结构
3.1 Bash
Bash是一种GNU操作系统中的shell,通常在Linux内核上实现,其他操作系统(比如著名的Mac OS X)也有一些不同的实现版本。Bash在sh的历史版本的基础上做了一些功能上的改进,使其更便于交互式使用或编程。
Bash是Bourne-Again SHell的缩写,为了纪念shell鼻祖Stephen Bourne(他是当代Unix Shell程序/bin/sh的创造者,该程序出现在贝尔实验室第七版Unix上)。Bash的原作者是自由软件基金会(Free Software Foundation)的一名雇员Brian Fox,而我是现在的开发者和维护员,同时还是俄亥俄州凯斯西储大学(Case Western Reserve University in Cleveland, Ohio)的志愿者。
和其他GNU软件一样,Bash具有很好的可移植性。Bash能运行在几乎每个版本的Unix上,它还被移植到了其他操作系统上(比如Windows上Cygwin和MingW),Bash同时还是某些类Unix操作系统(比如QNX和Minix)发行版的一部分。Bash的移植只依赖于一个Posix的编译和运行环境,这个条件容易满足,比如微软公司的Unix服务(Services For Unix, SFU)就能支持Posix。
3.2 句法单元和原语(primitive)
3.2.1 原语(primitive)
Bash中包含三种基本记号(token):保留关键字,单词,操作符。保留关键字指在shell中和编程语言中有明确含义的词语,这些关键字通常用来表达程序控制结构(比如if和while)。操作符由一个或多个元字符(metacharacter)构成,元字符指shell中具有特殊意义的字符,比如|和>。余下的shell的输入都可以视为普通的单词,但有时也会有特殊的含义,比如赋值语句和数字,这完全取决于在命令行中的位置。
3.2.2 变量和参数
和所有的编程语言一样,shell也提供变量,变量是一些用来指代数据并支持数据操作的名称。shell的变量包括用户变量和内置变量(称为参数)。一般,shell参数反映了shell的内部状态,它们的值可能是自动设置的,也可能由其他操作设置。
变量的值都是字符串。根据上下文的不同,有一些值会被特殊处理(后面会有解释)。变量使用"name=value"的形式来赋值,"value"这一项是可选的,将其省略表示赋值为空字符串。赋值时,shell将"value"展开并赋给"name"。shell能根据一个变量是否被设置(set)来执行不同的操作,但是赋值是设置变量的唯一方式。如果变量没有赋值,即使已经声明或已经设置属性,也会被视为没有设置(unset)。
以美元符($)开头的单词表示对变量或参数的引用。带$的单词将会被变量的值所替代。shell提供了大量的展开操作符,包括简单的值替换,根据模式匹配修改或删除变量值的一部分。
shell还支持局部变量和全局变量,但变量都默认是全局的。如果赋值语句置于简单命令(最常见的命令类型,可附带一些参数和重定向)前,那么这些赋值语句定义的变量将是局部的。shell中可以定义过程(即shell函数),函数中也可以定义局部变量。
为减小代码量,除了通常的变量之外,shell还支持整数和数组。整型变量表示数字,任何字符串赋值给整形变量时都会展开为算术表达式,计算结果并赋值。数组可以是索引数组(indexed array)或关联数组(associative array),前者使用数字下标,后者使用字符串下标。数组元素都是字符串,必要时也可视为整数。但数组不支持嵌套,即数组元素不能是其他数组。
Bash使用哈希表(hash table)来存储和访问shell变量,这些哈希表被链接起来管理变量的作用域。shell函数中支持多种变量作用域,比如命令前置赋值语句构成一个临时作用域。当被前置赋值语句的命令是shell内置命令时,shell就必须跟踪变量的顺序,以保证变量引用的正确性,作用域链表可实现这个功能。如果运行嵌套层次太多,需要遍历的作用域数目会相当惊人。
3.2.3 shell编程语言
简单的shell命令包含命令名称(比如echo或cd),可选数目的参数和重定向(redirection)。重定向允许shell用户控制命令的输入和输出。如前所述,用户可以为简单命令定义局部变量。
保留关键字可以实现复杂的shell命令。shell中包含了任何高级语言中都有的程序结构,比如if-then-else, while, 遍历列表的for循环,C风格的算术for循环等等。因而,shell中可构造诸如选择性和重复执行命令的更为复杂的命令。
Unix带给计算世界的一个重要贡献是管道(pipeline),管道指一系列顺序执行的命令,其中前一个命令的输出构成下一个命令的输入。任何shell结构都可以用于管道,我们甚至可以使用管道来生成其自身的输入。
Bash支持标准输入,标准输出,和标准错误(standard error)三个数据流,命令的结果可以重定向到一个文件或一个进程(Unix中,任何进程和设备都可视为文件)。shell程序员还可以在当前shell环境中使用重定向来打开或关闭文件。
Bash支持shell编程,shell脚本可以存储起来重复使用。shell函数和shell脚本都可以作为命令来执行,和单个命令的使用类似。shell函数定义为特殊的格式,可以在同一个shell上下文中存储和执行。shell脚本将命令存储在一个文件中,只能在一个新的shell进程中执行。shell函数共享了所在环境中的大部分上下文,但是shell脚本由于在新的shell进程中调用,只能共享一些进程间间的环境。
3.2.4 注意事项
继续往下读时,读者要时刻牢记shell的实现代码中只使用了少量的数据结构: 数组,树,单向链表和双向链表,以及哈希表。几乎所有shell结构都是用这些基本结构实现的。
shell在不同阶段传输信息并处理数据单元的数据结构是WORD_DESC。
typedef struct word_desc {
char *word; /* Zero terminated string. */
int flags; /* Flags associated with this word. */
} WORD_DESC;
单词被组合为简单的链表,比如参数列表。
typedef struct word_list {
struct word_list *next;
WORD_DESC *word;
} WORD_LIST;
WORD_LIST在shell中无处不在。一个简单的命令就是一个单词列表,展开结果同样是一个单词列表,内置命令的参数还是一个单词列表。
3.3. 输入处理
Bash流水线(pipeline)的第一个阶段是输入处理,即从终端或文件中读入字符,拆成行,传递给shell解析器,然后转换为命令。所谓行其实就是以换行符结尾的字符串。
3.3.1. readline和命令行编辑
在交互模式下,Bash的输入来自终端,而对于脚本的执行,输入则来自参数。在交互模式下,Bash允许用户编辑命令行,快捷键类似于Unix Emacs或Vi编辑器。
Bash使用readline软件库来实现命令行编辑,用户可以使用多种功能,比如保存命令行,调用前一条命令,执行csh风格的历史记录的展开。bash是readline库的主要用户,两者也是在一起开发,但readline的实现并不依赖于Bash。许多其他项目也采用readline来支持终端命令行编辑。
readline还支持为众多readline命令绑定不限长度的快捷键。readline的命令功能强大,支持光标在命令行中移动,插入或删除文字,获取以前的记录,补全文本等等。基于这些命令,用于可以自定义宏,按下指定的快捷键就可以插入一段定制的文字。readline的宏为用户提供简单字符串替换和速记功能。
readline 结构
readline是一个包含基本读入/分发/执行/重显示等步骤的循环结构。readline从键盘使用read或类似的函数读入字符,或者使用宏来获得输入。每个字符都是键映射表(或分发(dispatch)表)中的索引。虽然索引都是单字节字符,映射表的的值却可以表达更多的内容,因为它们可以指向新的映射表,这使得readline能够支持多字符快捷键。快捷键最后会被绑定到某个readline命令上(如beginning-of-line),并且触发这个命令。当敲击键盘时,字符会存入编辑缓冲区,这是因为这些字符本身是已经绑定到了self-insert命令上。readline还支持让一个快捷键绑定到一个命令,同时延长快捷键再绑定到另外一个命令上,映射表中有一个特殊的索引来标识这种情况(这个功能最近才开始支持)。将快捷键绑定到宏上带来了极大的灵活性,用户可以编辑任意字符,还可以定制复杂的快捷操作。readline的编辑缓冲区存储了绑定到self-insert命令的那些字符,缓冲区显示时占用一行或多行。
readline使用C语言字符来处理字符缓存和字符串,并基于这些简单字符来构造多字节字符。出于速度和存储方面的考虑,readline内部并不使用wchar_t类型,事实上,人们开始编码的年代还不怎么广泛支持多字符字符。如果本地设置(locale)支持多字节字符,readline自动读入整个多字节字符并插入编辑缓冲区。因为可以用一些简单字符序列来表达多字节字符,将多字节字符设为快捷键在理论上是行得通的,但是难于实现而且没人愿意这么用。比如,Emacs和Vi的命令中就全部是单字节字符构成的快捷键。
当快捷键触发编辑命令后,命令的执行可能会导致缓冲区中插入新的字符,或者编辑位置发生变化,或者部分乃至整行都被替换,但是readline始终会及时地将结果更新到终端上。有些编辑命令虽然可绑定到快捷键上,但并不会改变编辑缓冲区,比如有的只是修改历史文件。
更新终端显示虽然看起来简单,实际却非常复杂。readline必须跟踪3个地方:当前缓冲区内容,更新后的缓冲区内容,以及实际显示的字符。若考虑多字节字符,显示出来的字符可能与缓冲区内容并不一定完全相符,更新显示时必须要考虑到这个问题。当重新显示时,readline需要比较当前缓冲区内容与更新后缓冲区内容,找出差异再决定怎样高效地将差异更新到屏幕上。这个问题实际上已经被研究多年(即所谓的串对串校验问题, string-to-string correction problem)。readline采用的方法是定位出差异区域的边界点,然后计算出更新这一部分的代价,包括移动光标的代价(删除一个字符再插入一个字符显然不如直接覆盖)。readline随后以最小的代价来更新终端,删除行尾多余的字符,并将光标置于正确的位置。
更新显示引擎是readline中修改最为频繁的代码。大部分的修改都者为了增加新的功能,其中最为重要的功能是让提示符(prompt)保持稳定(比如提示符的颜色),以及处理多字节字符的能力。
readline将编辑缓冲区中的内容返回给调用程序,然后由调用程序负责存储到历史列表中。
readline扩展程序
readline不仅为用户提供了多种定制和扩展默认行为的方式,还支持让应用程序扩展默认功能。首先,可绑定的readline函数接受一个参数集合并返回特定类型的结果,应用程序可以很容易地使用定制的函数来扩展readline。以Bash为例,Bash绑定了30多个命令,支持Bash关键字的补全,调用shell内置命令等。
readling还允许应用程序使用回调函数来修改默认行为。应用程序可以传入函数指针替换readline内部函数,干涉其运行过程,从而执行特定的操作。
3.3.2. 非交互式输入处理
如果shell不使用readline,它会使用stdio或自己的输入缓冲函数来获得输入。如果shell是非交互式的,则Bash的缓冲输入模块更倾向于使用stdio,因为Posix标准对输入有特别的限制条件:shell在解释一条命令时只能占用必要的输入,而把其它的留给运行中的其它程序。这点非常重要,特别是shell从标准输入读入一个脚本的情况。shell允许在输入时尽可能多地缓冲输入,只要它能够在文件中回滚到解析器停止的位置。这意味着在不可随机访问(non-seekable)设备(如管道pipe)中shell一次只能读一个字符,对于文件来说shell则可以缓存任意多的内容。
不考虑这些特殊情况,非交互式输入的处理结果和readline一样:每个缓冲区以换行符(newline)结束。
3.3.3. 多字节字符
多字节字符的处理功能是在shell出现之后很久才加入进来的,因此其设计原则是尽可能小地影响已有代码。如果本地设置(locale)支持多字节字符,shell将输入存储在字节缓冲区中(简单的C语言字符),但是会将它们作为多字节字符进行处理。readline知道如何显示多字节字符(关键问题是一个多字节字符占用多少屏幕空间,以及屏幕上显示一个多字节字符需要使用多少个字节),如何在一行中移动一个字符(不是一个字节)的位置,等等。除了这些问题,多字节字符不会怎么影响输入处理。但需要注意的是,shell的其它部分在处理输入时需要考虑到多字节字符的影响(后面会有介绍)。
3.4. 解析
解析引擎的第一步工作是词法分析:将字符流分割成单词(word),然后赋予其意义。单词(word)是解析器操作的基本单元,是由元字符分隔的字符序列。简单的元字符如空格和制表符(tab),shell语言中的特殊字符也可构成元字符(如分号和&符号)。
Tom Duff曾在他的关于rc的文章(the Plan 9 shell)中说过,shell的一个历史遗留问题是没有人真正知道什么是Bash的语法。Posix的shell委员会最终还是发布一个Unix Shell的标准语法,虽然这个语法仍然存在大量的上下文依赖关系,而且还不能兼容以前的一些代码,但无疑这个标准是目前最好的,它的发布值得赞赏。
Bash解析器源于早期版本的Posix语法,而且,据我所知,它也是唯一一个使用Yacc或Bison实现的Bourne风格的shell。这带来了一些麻烦,shell语法本身并不特别适合yacc风格的语法解析,需要采用一些复杂的语法分析,而且解析器和词法分析器之间也要通力合作。
执行过程中,词法分析器从readline或其它输入来源中获取字符行,根据元字符将它们分割成记号(token),并根据上下文定位这些记号,然后将其传给解析器组合成语句和命令。这个过程中涉及了大量的上下文,比如,获得的单词可能是保留字,可能是标识符,可能是赋值语句的一部分,也可能是其它单词。下面是一个完全合法的命令:
for for in for; do for=for; done; echo $for
这个命令的作用是打印"for"这个字符串。
在这里顺便简单介绍一下别名(aliasing)。Bash支持使用任意文本(称为别名alias)替换简单命令的第一个单词(word),这个替换过程完全是基于文本的。因而别名可以改变shell的语法,有的别名甚至实现了一个Bash不支持的复合命令。别名完全是在Bash解析器的词法分析阶段实现的,而解析器必须告诉分析器(analyzer)什么时候允许展开别名。
和许多编程语言一样,shell支持字符的转义,用来改变字符的原有含义,使得一些元字符(如&)可以出现在命令中。Bash中三种类型的引用,相互之间稍有不同,对包含的文本的解析方式也不尽相同。第一种是反斜划线(backslash),用来转义后面的一个字符。第二种是单引号,它禁止对包含的文本进行解析。第三种是双引号,它阻止部分解析,但是允许一些单词(word)的展开(处理反斜划线的方式也不相同)。词法分析器解译被引用的字符和字符串,防止它们被解析为保留字或元字符。但有两个例外情况,$'...'和$"...",它们处理转义字符的方式和ANSI C一样,允许使用标准国际化函数来处理。前者使用更为广泛,后者则因为案例太少而不为人知。
从解析器(parser)到分析器(analyzer)剩下的工作就非常直接了。解析器对一些状态进行编码,然后共享给分析器以支持依赖上下文的语法分析。比如,词法分析器根据记号的类型将单词(word)分类为:保留字(依赖上下文),单词,赋值语句,等等。为实现这个功能,解析器提供解析命令的进度信息,比如是否正在处理一个多行文本(有时候称为here-document),或者一个case语句或条件命令,或者shell的扩展模式(extended shell pattern)或复合赋值语句。
在解析阶段,识别命令替换结点位置的大部分工作被封装在了一个函数中(parse_comsub),这个函数能够处理大量的shell语法,并且包含了大量的冗余的读取记号的代码。而且,parse_comsub函数必须要知道here-document,shell命令,元字符和单词(word)的边界,引用(quoting),以及什么时候允许保留字存在(比如,识别case语句中的保留字)。正确完成这些工作是比较费时的。
在单词展开过程中展开一个命令替换,Bash使用解析器来获得这个结构正确的结束位置。这和eval命令将字符串变成命令的过程有些类似,但不同的是命令的结束位置并不在字符串的结尾。为了实现这个功能,解析器必须将右括号视为一个合法的命令终止符,这又导致了大量特殊情况的出现,并且要求词法分析器(在恰当的上下文中)将右括号标记为EOF。在递归触发yyparse之前,解析器还必须能够保存和恢复解析器状态,因为在读取一条命令的中途,一个命令替换的解析和执行可能是展开一个提示字符过程的一部分。因为输入函数实施了预读(输入来源可能是字符串,文件,或使用readline的终端),这个函数必须最后能将输入指针(input pointer)恢复到正确的位置。这一点非常重要,不仅保证了输入不会丢失,而且使得命令替换的展开函数能构造出正确的用于执行的字符串。
可编程的单词展开也存在类似的问题,因为在解析一个命令时允许执行其它任意命令,解决方案是在执行前保存状态,在执行后恢复状态。
引用(quoting)是另外一个不兼容性和争论的来源。在Posix的shell标准发布二十年之后,标准工作组成员们仍然在争论引用的那些难以理解的行为是否合理。但是Bash一直都只是一个实现上的参考,对制订标准是无能为力的。
解析器返回一个C结构体来表达一个命令(对于复合命令,这个结构体中可能还包含有其它命令),然后将其传递给shell的下一个阶段:单词展开。命令结构体由一系列命令对象和单词列表组成。大部分的单词列表对应于各种变换,其意义随上下文的变化而变化(下面会有解释)。
3.5. 单词展开
在解析阶段之后,在执行阶段之前,解析阶段产生的许多单词对应于一个或多个单词展开,比如$OSTYPE可以展开为"linux-gnu"。
3.5.1. 参数和变量展开
变量展开是用户最熟悉的。shell变量几乎都没有类型(少数例外),都被视为字符串。展开就是将这些字符串展开和转变为新的单词和单词列表。
有的展开可以作用于变量的值上。编程人员可以获得变量值的子字符串,获得值的长度,删除匹配串首或串尾的子串,根据字符串匹配替换子串,或者修改值中的大小写。
还有一些展开依赖于变量的状态:变量是否已经设置会导致不同的展开或赋值行为。比如,若parameter已经设置(并且不为空),${parameter:-word}会被展开为parameter,否则展开为word。
3.5.2. 其他展开
Bash还支持其他多种展开,它们的规则都很诡异。处理过程中,最优先的展开是括号展开(brace exapansion),括号展开把
pre{one,two,three}post
转变为
preonepost pretwopost prethreepost
命令替换(command substitution)是shell执行命令与操纵变量的完美结合。shell运行一个命令,收集其输出,然后将输出作为展开的值。
命令替换的一个问题在于命令的立即执行然后等待结果,此过程中shell无法传入输入。Bash使用一个称为进程替换(process substitution)的功能来弥补这些不足,进程替换实际上是命令替换和管道的组合。和命令替换类似,Bash运行一个命令,但令其运行于后台而不再等待其完成。关键在于Bash为这条命令打开了一个用于读和写的管道,并且绑定到一个文件名,最后展开为结果。
下一个展开是波浪符展开(tilde expansion)。起初,~alan记号只是表示对Alan主目录的引用,多年后,这却渐渐变成了引用多个不同目录的一种方式。
最后是算术展开(arithmetic expansion)。$((expression))会执行expression表达式,其规则与C语言表达式一致。expression的计算结果变成展开的结果。
单引号和双引号之间最明显的差异在于变量展开(variable expansion)。单引号禁止所有展开,被包含的字符全部原封不动,而双引号则允许部分展开。单词展开(word expansion),命令展开,算术展开,进程替换都可以在双引号中进行(双引号只处理其结果),而括号展开和波浪符展开则被禁止。
3.5.3. 单词拆分
单词展开的结果会被拆分(split),拆分的限定符来自于shell变量IFS的值。shell使用这种方式将单个单词拆分成多个。每当$IFS1中的一个字符在结果中出现,Bash就会将单词一分为二。单引号和双引号中禁止单词拆分。
3.5.4. 名称替换(globbing)
结果拆分之后,shell将逐个处理之前展开得到的单词,使用一个模式来匹配已知的文件名,包括一些主要的文件目录。
3.5.5. 实现
如果shell的基本架构将流水线(pipeline)并行化,单词展开则是它自身的管道。单词展开的每个阶段处理一个单词,经过可能的转换,然后将其传递给下一个展开阶段。等到所有的单词展开都已执行,命令就可以开始执行了。
Bash的单词展开的实现基于前面所说的基本数据结构。对解析器输出的单词逐个展开,由一个单词获得一个或多个单词。WORD_DESC是一个通用的数据结构,足以封装单个单词展开所需的所有信息。其中,flags可用于编码单词展开阶段的信息,并把信息传递给下一个阶段。例如,解析器使用一个标志位记录某个单词是一个赋值语句,并通知展开阶段和命令执行阶段,而单词展开代码内部也使用标志位来禁止单词拆分或标记空字符串(比如"$x",其中$x未定义或为空值)。使用单个字符串来表达展开后的单词,并且用某种字符编码来表达其它信息,实现起来并不容易。
对于解析器来说,单词展开的代码还需要处理多字节字符。比如,变量长度展开(${#variable})用于计算字符数目而非字节数,这些代码能正确识别展开的结束位置或多字节字符存在情况下特殊字符的展开。
3.6. 命令执行
Bash内部流水线到命令执行阶段才真正开始执行命令。大部分时候,展开后的单词集合被分解为命令名称和参数集合,然后作为文件传递给操作系统被读入和执行,而余下的单词则作为argv剩下的部分传递给操作系统。
到目前为止,描述的主要是简单命令(命令名加上一些参数)的执行,它们是最常用的类型,但是Bash还提供了更多的功能。
命令执行阶段的输入是一些解析器创建的命令结构,以及一些展开单词的集合。这是Bash编程语言真正开始起作用的时候。编程语言使用变量和前面提到的展开来实现高级语言中常见的结构:循环(looping),条件(conditionals),替换(alternation),分组(grouping),选择(selection),基于模式匹配的条件执行,表达式求值,以及其它一些shell特有的结构。
3.6.1. 重定向
shell作为操作系统界面的表现之一是能够将输入和输出重定向到它所调用的命令上。重定向的语法反映了shell早期用户的复杂操作:直到最近,用户仍然需要跟踪正在使用的文件描述符(file descriptor),并且显式地用数字来指定(除了标准输入,标准输出和标准错误)。
重定向语法最近增加的一个功能是允许用户将shell定向到一个合适的文件描述符,然后赋值给一个指定的变量,因而用户不需要再去选择文件描述符。这个功能减少了程序员跟踪文件描述符的负担,但是增加了额外的处理过程:shell必须将文件描述符复制到正确的位置,还要确保它们赋值给指定的变量。这是又一个从词法分析器到解析器再到命令执行的信息传递过程的例子:分析器找出包含变量赋值的重定向,解析器生成重定向对象并用一个标志位标记需要赋值,然后重定向代码根据这个标志位确保文件描述符数字被赋值到正确的变量上。
实现重定向最难的地方是记得如何撤销重定向。shell有意不区分文件命令和内置命令,但是,无论是哪种命令,重定向的影响范围不应该超过命令结束的时候2。因此,shell必须跟踪重定向,保证可以将其撤销,否则,内置命令的输出重定向会改变shell的标准输出。Bash知道如何撤销每一种重定向,要么关闭之前分配的文件描述符,要么先保存文件描述符之后再使用dup2恢复。这些过程使用的重定向对象和解析器创建的重定向对象是一样的,并且用同样的函数来处理。
因为多重重定向使用简单对象列表来实现,用来撤销的那些重定向也保存在一个单独的列表中。这个列表在命令完成时进行处理,但是shell必须确认处理的时机,因为绑定到shell函数或"."内置命令上的重定向必须在它们执行完之前都一直有效。如果没有命令被执行,内置命令exec将直接丢弃这个撤销列表,因为关联到exec上的重定向在整个shell环境中都是有效的。
另外一个复杂的地方来自Bash本身。Bourne shell的历史版本只允许用户操纵文件描述符0-9,而把10和10以上保留为内部使用。后来,Bash放松了这个限制,允许用户在不超过进程文件打开数限制的条件时使用任意文件描述符。这意味着Bash必须跟踪内部的文件描述符,包括那些不是直接由shell打开而是由外部库打开的那些文件描述符,这些内部文件描述符还可能时不时被移动。因此,大量的文件描述符需要跟踪,有的使用启发式的close-on-exec标志位,有的重定向列表在整个命令执行过程中都需要维护,然后在执行完成时处理或丢弃。
3.6.2. 内置命令
Bash中包含了大量的内置命令,这些命令由shell执行,但不会创建新进程。
使用内置命令最普遍的原因是维护和修改shell内部状态。比如cd命令就是一个Unix世界中的经典案例,cd命令需要修改当前工作目录这个内部状态,因此不能用外部命令来实现。
Bash内置命令与shell其他部分使用相同的原语(primitive)。每个内置命令都是用C语言函数来实现的,以单词列表作为其参数。这些单词来自于单词展开阶段,内置命令将其视为命令名和参数。大部分情况下,内置命令使用标准的展开规则,但也有一些例外:Bash内置命令接受赋值语句作为其参数时(比如declare和export),赋值参数的展开规则与寻常变量赋值时的展开一致。WORD_DESC结构体中的flags成员在这个地方也会发挥作用,在shell内部流水线(pipeline)不同阶段之间传递信息。
3.6.3. 简单命令执行
简单命令是shell中最常遇到的命令。其过程无非是:搜索和执行文件命令,收集退出状态,简单命令覆盖了shell当前大部分功能。
shell的变量赋值(形如var=value的单词)本身也是一种简单命令。赋值语句可以置于其它命令之前,也可以单独成一行。如果置于命令前,变量将传递给该命令的局部环境(如果这个命令是内置命令或shell函数,除少数例外情况,变量赋值都将起作用)。如果单独成一行,赋值语句将修改shell状态的值。
当出现一个既不是shell函数又不内置命令的命令名称,Bash会搜索文件系统来寻找同名的可执行文件。PATH环境变量的值是一些由冒号分隔的目录列表,Bash根据这些目录来搜索文件命令。命令名称中若包含斜划线(或其它目录分隔符),Bash将直接执行此命令,而不会再搜索。
当一个命令通过PATH搜索得到,Bash将命令名称和对应的完整路径存于哈希表中,PATH搜索之前会查询这个表来提高效率。如果命令没有被搜到,Bash会执行一个特殊的函数,以命令名称和参数作为这个函数的参数。一些Linux发行版通过这个方式来提示用户安装缺失的命令。
如果Bash搜索并执行一个文件命令,它会创建一个新的执行环境并fork出一个新的进程,然后让此可执行文件在新的环境中执行。执行环境完全从shell环境复制而来,只是在信号处理和重定向的文件打开关闭等方面有少许修改。
3.6.4. 任务控制
shell在前台执行命令时,必须等待命令返回才能执行下一条命令,但shell还可以在后台执行命令,然后立刻读入下一条命令。任务控制(Job control)指在前台和后台之间切换进程(正在执行的命令),以及挂起(suspend)和恢复(resume)执行的能力。为实现这个功能,Bash引入了任务(job)的概念,任务本质上指的是被一个或多个进程执行的某个命令。比如,管道为每个管道元素创建一个进程,它们共同构成一个任务。进程组可以将多个分离的进程组合成单个任务。终端绑定了一个进程组ID,这同时也是前台进程组的ID。
shell使用一些简单的数据结构来实现任务控制。用一个结构体就能表达一个子进程,包括了进程ID,状态和终止时的返回状态。管道只不过是这个进程结构体的简单链表。任务(job)的结构更加简单,包括进程列表,一些任务状态(运行,挂起,退出,等等),以及任务进程组的ID。进程列表通常只有一个进程,只有管道才会导致一个任务包含多个进程。如果一个进程ID和任务进程组ID相同,则此ID成为这个进程组的领导(leader)。当前任务集合存于一个数组中,这种实现方式在概念上和实际的表现形式是比较接近的。任务的状态和退出状态由其成员进程的相应状态组合而成。
和shell中其他部分一样,实现任务控制的复杂性在于登记(bookkeeping)。shell必须把进程归入正确的进程组中,并保证子进程的创建也要同步进行。因为终端的进程组决定了前台任务,终端的进程组必须要设置正确(如果前台任务没有归入shell的进程组,那么shell将无法读入终端输入)。因为任务如此依赖于进程,实现复杂命令并不是那么显然,比如while和for循环可以作为一个整体来停止或启动,其他shell很少能做到这一点。
3.6.5. 复合命令
复合命令包含了一个或多个简单的命令,里面往往还带有一些关键字(比如if或while)。这保证了shell的强大编程能力。
复合命令的实现没有什么特别的地方。解析器为各个命令构造相应的对象,然后遍历这些对象。每个复合命令都使用一个C函数来实现,它的功能包括执行恰当的展开,执行特定的命令,根据命令的返回值来变更执行流程。以实现for命令的函数为例。首先它会展开in关键字后面的单词列表,该函数随后遍历这些单词,在for循环中赋给相应的变量并执行。for命令的执行不会受子命令返回值得影响,但是break和continue这两个内置命令会改变循环的执行过程。一旦列表中所有的单词都已经处理完,for命令就会返回。从这个例子可以看出来,命令的实现和语法的描述是非常相近的。
3.7. 经验教训
3.7.1. 什么是重要的
参与到Bash项目中已经有20多年,在这期间我也获益良多。最重要的一点是一定要保留详细的修改日志,其重要性怎么强调都不过份。通过阅读修改日志来回忆起当初的想法,感觉是很好的。甚至你还可以将某个修改与一个bug报告联系起来,然后编写一个重现bug的测试用例或提出一些建议。
如果条件允许,我建议在项目之初就考虑全面的回归测试。Bash拥有数千个测试用例,覆盖了差不多所有的非交互性功能。我考虑过测试交互式功能,其实Posix标准的一致性测试套件中就有交互性测试,只是并没有将这个测试框架发布出来(我认为很有必要)。
标准很重要,Bash受益于它是一个标准的实现。参与到你正在实现的软件的标准化过程中来也是非常重要的。在讨论相关功能和行为时,标准往往是最终的参考依据。当然,前提是这是一个好的标准。
外部标准重要,内部标准同样重要。我很幸运地接触到了GNU项目的诸多标准,它们包含了大量关于设计和实现方面的好且实用的建议。
好的文档同样非常关键。如果你希望别人使用你的软件,全面并清晰的文档就是必要的。一个成功的软件必须拥有大量的文档,因而开发者提供权威的版本就显得非常重要。
优秀的软件随处可见,那就充分利用起来吧。比如,gnulib中包含了大量的有用的函数,你尽可以把它们"抠"出来。BSD各个版本和Mac OS X就是这么干的。Picasso说过:好的艺术家靠的是偷,说的就是这个道理。
参与用户社区,但是准备挨骂,有时候这并不好受。活跃的用户社区好处是显然的,但是这些人可能会非常情绪化,不要太当真就好。
3.7.2. 如果可以重来
Bash拥有数百万用户,我知道后向兼容有多么地重要。在某种意义上,后向兼容意味着永远不用向用户说抱歉。但是,这个世界远不是这么简单。事实上,我不得不一直做一些破坏兼容性的修改,比如修正一个不好的决定,修改一个错误的设计,或者更正shell不同部分之间的不兼容性,这些都是情有可原的修改,但是几乎都会引起一些用户的抱怨。我早就应该对当兼容性分级处理的。
Bash的发展一直都没有特别的开放,我已经习惯于里程碑发布形式(比如 bash-4.2)并由个人提交补丁。我的理由是:我需要适应开发商们更长的发布周期(相对于自由软件和开源世界),而且我也有过beta版本传播地过于广泛的不快回忆。当然,如果一切都要重来,我还是会考虑更快的发布频率,比如可以使用一个公开的源码仓库。
不真正动手去做是完不成任何事的。有一件事我已经考虑了很久,却一直没去做,那就是将Bash的解析器重写为递归下降(recursive-descent)的方式,以取代bison。以前,我以为为了遵守Posix标准,这件事就非得做,但是后来我只需要少量修改就解决了这个问题。如果当时就从头写起,大概现在我已经实现了一个新的解析器,那么很多问题都会变得简单得多。
3.8. 结论
Bash是一个优秀和复杂的大型免费软件。经历了超过二十年的良性发展,已经变得成熟和强大。现在,Bash几乎远处不在,数百万人每天都在使用,虽然有些人可能还浑然不知。
从Stephen Bourne写出第七版Unix中的shell开始,Bash就一直受到多方的影响。其中最重要的影响来自于Posix标准,它形成了shell很重要的一部分行为。然而兼容性和标准化难以两全,实现起来是非常头痛的事。
Bash受益于GNU项目,因为GNU项目提供了一个Bash赖以生存的开发生态环境。没有GNU就不会有Bash。Bash还得益于活跃并朝气蓬勃的用户社区,用户的反馈成就了今天的Bash,这也是自由软件的精髓所在。
术语表
- alternation: 某种编程语言中的结构,翻译成替换。在Perl中alternation指一个字符串集合中的任选一个。
- word: 指shell中的的一个字符串(以空格等非打印字符分隔),翻译成单词。根据上下文的不同,word具有两种含义。广义上讲,所有连续的可打印字符串都可以视为word,但具体到shell中,word又可指狭义的不含特殊字符的字符串。两种含义在文中都有出现,但以后者为主。
- expansion: 展开。类似于变量取值,将包含特殊字符和结构的字符序列经过一次或多次替换得到一个新的字符串
- pipe/pipeline: 管道, 将一些命令串连起来(用
|符号),前一个命令的输出构成后一个命令的输出。另外一种语义是:shell的内部流程,翻译成流水线。 - 数据与命令: 文中这两个概念容易混淆。因为所有的shell命令或脚本都是以字符串形式存在,因此都可以视为shell解释器的输入数据。但是,这些shell命令或脚本从编程语言的角度来看,又是以语句为基本单元的,这样的语句可被称为命令。而shell中最基本的命令则包括内置命令和文件命令, 从这个意义上看, 一个语句包含了命令和命令的参数,而这些参数又可视为命令的数据。
- primitive: 原语
- token: 记号
- metacharacter: 元字符
- builtin: 内置命令
- parser: 解析器
- lexical analysis: 词法分析
- local: 本地设置
- prompt: 提示符
脚注
- 大部分情况下, 只包含了一个这样的字符.
- 内置命令
exec是这条规则的例外情况