
第6章 Git
作者:Susan Potter,翻译:张吉
原文:http://www.aosabook.org/en/git.html
6.1 Git概述
Git能够让不同的协作者通过一个点对点的仓库网络对数据内容(通常是代码,当然不仅限于代码)进行维护。它支持分布式的工作流程,能够让数据内容临时分离,并最终合并到一起。
本章将阐述Git的内部实现是如何提供以上功能的,以及它和其他版本控制系统(VCS)的区别。
6.2 Git起源
为了更好地理解Git的设计思想,我们有必要先了解一下Git项目的发源地——Linux内核开发社区——所面临的问题。
Linux内核开发与其他商业软件项目有很大不同,因为它的开发者众多,且每个开发者的参与程度和对Linux内核代码的理解有很大差异。多年以来,内核代码一直都是以Tar压缩文件以及补丁的形式维护的,而当时的核心开发团队一直在寻找一个能够满足他们各方面需求的版本控制系统。
Git就是在这样的背景下于2005年作为一款开源软件诞生的。当时,Linux内核代码通过两种版本控制系统进行维护,BitKeeper和CVS,分别由两组核心开发团队使用。BitKeeper相较于当时颇为流行的CVS,提供了一种不同的历史展示方式。
当BitKeeper的所有者BitMover决定收回Linux内核开发人员的使用许可时,Linux Torvalds紧急开启了一个项目,也就是后来的Git。一开始,他通过编写一组Shell脚本来帮助他将邮件中的补丁按顺序应用到代码中。这组原始脚本能够在代码合并过程中迅速中断,让维护者能够进行人工干预,修改代码,然后继续合并。
从项目开始之初,Torvalds就为Git制定了一个目标——要和CVS的做法完全相反——同时还包含了以下三条设计目标:
- 支持分布式的协作流程,类似BitKeeper
- 预防代码错乱
- 高性能
这些设计目标都被实现了,我会在下文中通过解析Git的各种做法来阐述,包括在内容管理中使用有向无环图(DAG),头指针引用,对象模型,远程协议,以及Git如何追踪合并树。
虽然Git设计之初受到了很多BitKeeper的影响,但是两者还是有根本上的区别的,如Git提供了更多分布式和本地开发流程,这点是BitKeeper做不到的。Monotone,2003年启动的一个开源分布式版本控制系统,也对Git的早期开发产生了影响。
分布式版本控制系统在提供更灵活的工作流程的同时,往往会增加它的复杂程度。分布式模型的独特优点有:
- 能够线下进行增量提交
- 开发者可以决定自己的代码何时能够开放出来
- 能够线下浏览历史
- 可以将工作成果发布到不同的仓库,以不同的分支、不同的提交粒度展现出来
在Git项目的开发期间,诞生了其他三个开源分布式版本控制系统(其中Mercurial可以参见《开源软件架构》的第一卷)。这些分布式版本控制系统(dVCS)都提供了非常灵活的工作流程,这是先前的集中式版本控制系统做不到的。注意:Subversion有一款插件名为SVK,由不同的开发者维护,提供了服务器之间的同步功能。
目前流行的dVCS包括Bazaar, Darcs, Fossil, Git, Mercurial, 以及Veracity。
6.3 版本控制系统的设计
现在让我们回过头来看看Git之外的其他版本控制系统是如何设计的。通过比较他们和Git之间的区别,可以帮助我们去理解Git在架构设计中的选择。
版本控制系统通常有三项核心功能(需求):
- 保存内容
- 记录变更历史(包括具体的合并信息)
- 向协作者分发内容和变更历史
注意:第三项并不是所有版本控制系统的核心功能。
保存内容
在VCS中保存内容,最普遍的做法是保存增量的修改,或使用有向无环图(DAG)。
增量修改可以反映出两个版本之间的内容差异,以及一些额外的信息。使用有向无环图保存内容则是将特定对象构造成一种树状结构,作为某一次提交的快照保存下来(树状结构中未发生变化的对象是可以重用的)。Git使用有向无环图来保存内容,它所使用的不同对象类型会在本文的“对象数据库”一节中有所描述。
提交和合并的历史
在保存历史、记录变化方面,大部分VCS使用以下方式之一:
- 线性历史
- 有向无环图
Git使用的还是有向无环图,这次则是用来保存历史。每次提交包含了它父节点的元信息——Git中的一次提交可以拥有0个或多个父节点(理论上没有个数限制)。例如,Git仓库的第一次提交就没有父节点,而一次三头合并则有三个父节点。
Git和SVN线性提交的另一个重要区别是Git可以直接进行分支的创建,并记录下大部分合并历史。
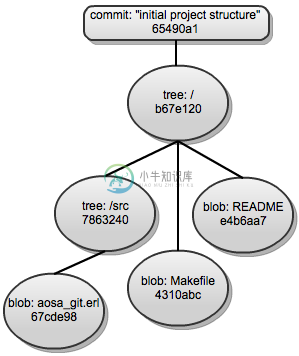
图6.1:Git中有向无环图示例
通过采用有向无环图保存内容,Git能够提供完整的分支功能。一个文件的历史会通过它所处的目录结构位置和根节点关联起来,并最终和一个提交节点关联。这个提交节点又会有一个或多个父节点。这种组织方式提供了以下两个特性,让我们能够更好地在Git浏览文件历史和内容:
- 当内容节点(文件或目录)在有向无环图中有相同的标识(Git中以SHA码表示),即使它们处于不同的提交节点,也能保证它们的内容是一致的,从而使得Git在差异比对时更为高效。
- 在对两个分支进行合并时,实质上是在对两个有向无环图节点进行合并。有向无环图能够让Git更为高效地判断出他们共同的父节点。
内容分发
版本控制系统在向协作者分发内容时通常有以下三种做法:
- 仅限本地:某些版本控制系统没有上文提到的第三项需求。
- 中央服务器:版本库的所有改动都必须在一个中央版本库中进行,也只有这个版本库会记录历史。
- 分布式模型:虽然分布式模型中也会有一个中央仓库供协作者“推送”自己的改动,但协作者可以在本地进行提交,并稍后再推送到远程。
为了展示以上设计模式的优点和不足,我们设想这样一个应用场景:一个SVN仓库和一个Git仓库,有着相同的内容(即Git默认分支的头指针指向的内容和SVN仓库最新的trunk分支内容一致)。一个名叫Alex的开发者在本地检出了一份SVN代码,以及克隆了一个Git版本库。
假设Alex在本地对一个1M大小的文件进行了修改,并进行了提交。提交后本地更新了元信息,远程服务器则是将文件的差异记录了下来。
Git下则有所不同。Alex对文件的变动首先会在本地进行记录,然后再“推送”到远程的公共仓库,这样文件的改动就能被其他开发者看到了。文件内容的变动记录在不同的版本库之中的表示方式是完全一致的。除了本地提交之外,Git会为变动后的文件创建一个对象来保存它(包括其完整的内容),然后逐层为该文件的父目录创建对象,直至仓库根目录。接下来Git会创建一个有向无环图,从刚才新创建的根目录节点开始,指向各个二进制单元(期间会重用那些内容没有改变的二进制单元),并使用新创建的二进制单元去替代那些变动的部分(一个二进制单元通常用来表示一个文件)。
到此为止,本次提交还是只保存在Alex克隆下来的本地仓库中。当Alex将这个提交推送到远程仓库后,远程仓库会验证这次提交是否能应用到当前分支中,然后这些对象将会按照原样保存下来,如同在本地仓库中创建的一样。
在Git中会有很多可变动的部分,有些对用户是透明的,有些则需要用户显示地指定这些内容是否需要分享出来,或是只在本地保存。虽然增加了复杂性,但也提供给团队开发者更大的自由度,得以更好地控制工作流程和发布内容,这在“Git起源”一节中已经有所阐述。
在SVN中,开发者不会忘记将变动内容提交至远程仓库。从效率上讲,SVN仅保存变动内容的方式会比Git保存文件每个版本的完整内容要来得高效,但是之后我们会讲述Git其实已经通过某种方式对此进行了优化。
6.4 工具包
如今,Git已然形成一个生态系统,在各种操作系统上(包括Windows)都开发出了大量命令行和图界面工具,而他们大部分都是构建在Git核心工具包之上的。
由于Git是Linus发起和开发的,它又立足于Linux社区,因此Git工具包的设计理念和传统的Unix命令行工具相仿。
Git工具包分为两个部分:底层命令和上层命令。底层命令提供了基本的内容追踪手段,以及直接操纵有向无环图。上层命令则是用户主要接触的命令,用以维护仓库,以及在多个仓库间进行协作。
虽然Git工具包提供了足够多的命令来操纵仓库,但是开发者们还是抱怨Git没有提供类库以供调用。Git命令最终会执行die()方法,使得GUI和Web界面在使用它时必须启动一个新的进程,效率较低。
不过这一问题已经得到处理,我会在本文的“当前进展和未来规划”一节加以阐述。
6.5 版本库、暂存区、工作区
让我们开始深入研究一下Git吧,了解其中几个关键概念。
首先让我们在本地创建一个Git版本库。在类Unix系统下,我们可以执行以下命令:
$ mkdir testgit
$ cd testgit
$ git init
这样我们就在testgit目录中初始化了一个新的版本库。我们可以建立分支、提交、创建里程碑、和远程Git仓库进行交互。我们甚至可以和其他类型的版本控制系统进行交互,只需要借助若干git命令即可。
git init命令会在testgit目录下创建一个名为.git的子目录。我们来看一下这个目录的结构:
tree .git/
.git/
|-- HEAD
|-- config
|-- description
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-commit.sample
| |-- post-receive.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- pre-rebase.sample
| |-- prepare-commit-msg.sample
| |-- update.sample
|-- info
| |-- exclude
|-- objects
| |-- info
| |-- pack
|-- refs
|-- heads
|-- tags
.git目录默认创建在工作区的根目录下,也就是testgit。它包含了以下几种类型的文件和目录:
- 配置文件:
.git/config、.git/description、.git/info/exclude,这些文件会用来配置本地仓库。 - 钩子:
.git/hooks目录下的脚本可以在Git运作的各个环节中得到执行。 - 暂存区:
.git/index文件(它并没有在上述目录结构中显示出来)会用来保存工作区准备提交的内容。 - 对象数据库:
.git/objects是默认的Git对象数据库存放目录,囊括了本地仓库的所有文件内容和指针。对象一经创建则不能修改。 - 引用:
.git/refs目录用来存放本地和远程仓库的分支、里程碑、头指针等信息。“引用”表示指向某个对象指针,通常是tag和commit类型。引用之所以放置在对象数据库之外,是为了让他们能够随版本库的演进而变化。特殊的引用可以指向其他引用,如HEAD。
.git目录是真正意义上的版本库。工作区指的是包含所有工作文件的目录,它通常是.git目录的父目录。如果你需要创建一个没有工作区的远程仓库,可以使用git init --bare命令。它会直接在根目录下生成Git仓库的各类文件,而不是放置在一个子目录中。
另一个较为重要的文件是Git暂存区:.git/index。它在工作区和本地版本库之间增加了一个缓冲区,可以将需要提交的内容暂存在这里,最后一起提交。即使你对很多文件进行了修改,通过暂存区可以将它们作为一次完整的提交,并加注合理的注释。如果想将工作区某些文件的部分修改保存至暂存区,可以使用git add -p命令。
Git暂存区里的内容默认保存在单个文件中。版本库、暂存区、工作区的存放位置都是可以通过环境变量来进行配置的。
我们有必要了解一下以上三个区域的文件是如何进行交互的,以几个核心的Git命令举例:
git checkout [branch]这条命令会将HEAD引用指向指定分支的引用(如
refs/heads/master),并用该引用指向的内容替换掉暂存区和工作区中的内容。git add [files]这条命令会检验工作区中指定的文件和暂存区是否一致,若不一致则更新暂存区。版本库不会发生变化。
为了深入挖掘其中的原理,让我们看看.git目录下的文件都发生了哪些变化:
$ GIT_DIR=$PWD/.git
$ cat $GIT_DIR/HEAD
ref: refs/heads/master
$ MY_CURRENT_BRANCH=$(cat .git/HEAD | sed 's/ref: //g')
$ cat $GIT_DIR/$MY_CURRENT_BRANCH
cat: .git/refs/heads/master: No such file or directory
这里会返回一个错误信息,因为我们还没有在Git仓库中进行过任何提交,因此不会存在任何分支,包括默认分支master。
让我们进行一次提交,这时master分支会自动创建:
$ git commit -m "Initial empty commit" --allow-empty
$ git branch
* master
$ cat $GIT_DIR/$MY_CURRENT_BRANCH
3bce5b130b17b7ce2f98d17b2998e32b1bc29d68
$ git cat-file -p $(cat $GIT_DIR/$MY_CURRENT_BRANCH)
输出的内容就是Git对象数据库中保存的信息了。
6.6 对象数据库
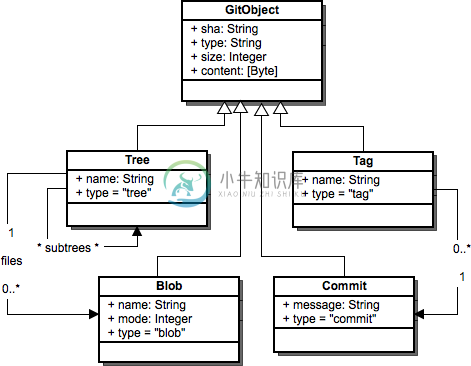
图6.2:Git对象
Git有四种基本对象类型,版本库中的所有内容都是由这些基本对象类型构成的。每种对象类型包含以下属性:类型、大小、内容。这四种基本对象类型是:
- 树:用来表示目录结构,树中的元素可以是另一棵树或是一个二进制单元。
- 二进制单元:表示一个文件。
- 提交:提交会指向一个根节点树对象,并保存父提交的信息和其他基本信息。
- 里程碑:里程碑有一个名称,并指向版本库中的一个提交对象。
所有的基本对象类型使用SHA码来标识,它是一种40位的十六进制字符串,含有以下特性:
- 如果两个对象是一致的,则SHA码一致。
- 如果两个对象不一致,则SHA码也不一致。
- 如果只是拷贝了对象的一部分,或者对象的数据发生了其他更改,只需重新计算其SHA码就能区别开来。
前两种属性使得Git能够实施它的分布式模型(Git的第二个目标),第三种属性则是杜绝了数据混乱(第三个目标)。
6.7 存储和压缩技术
Git是通过压缩数据内容来解决存储大小的问题的,它使用一个索引文件来标识对象内容在压缩文件中的实际位置。

图6.3:压缩文件和它对应的索引文件
我们可以使用git count-objects来查看版本库中未经压缩的对象数量,然后让Git对未压缩的对象进行压缩,删除冗余的对象等。
Git对象的压缩方式进行过升级。过去,压缩文件和索引文件的CRC校验码会全部保存在索引文件中,这就无法检测出压缩对象中存在的数据混乱,因为后续压缩过程中不会再进行校验。新版本(Version 2)的压缩格式中将每个压缩对象的CRC校验码都保存了下来,从而解决了这一问题。同时,新版格式允许压缩文件大于4GB,这在以前是不支持的。为了更快地检测压缩文件是否损坏,文件末尾会保存一个20个字节的SHA1码,对压缩文件中所有对象的SHA码进行排序和校验。新版压缩格式的主要目的是为了满足Git设计目标中的杜绝数据混乱。
对于远程传输,Git会计算同步版本库(或分支)需要传输的提交和文件内容,生成相应的压缩文件,通过指定协议进行传输。
6.8 记录合并历史
上文我有提到过,Git和其它类RCS的版本控制系统的最大区别在于对合并历史的记录。如SVN将文件和目录结构的改动用线性提交来表示,版本号高的内容一定会覆盖版本号低的内容。因此,SVN不能直接提供分支功能,而是使用一种人为规定的目录结构来实现:
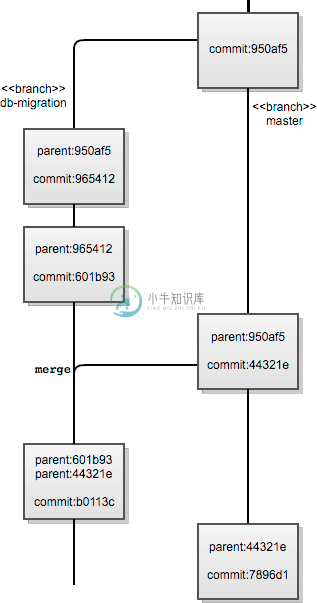
图6.4:合并历史的图形表示
首先让我们用一个示例来说明要维护多个分支会多么麻烦,而且在某些场景下是有局限性的。
SVN中的“分支”通常放置在branches/branch-name,它和主干分支trunk(相当于 master )目录同级。我们假设这个分支和主干分支是并行开发的。
举例来说,我们可能需要修改某个软件的数据库连接类型。在此过程中,我们想要将其他分支(非trunk)的内容合并到当前分支中。合并完成后(可能需要手工合并),我们继续修改。全部完成后,我们需要将branches/branch-name分支合并到trunk中。在类似SVN的线性历史版本控制系统中,我们无法得知其他分支的内容是否已经包含在trunk中了。
而对于以有向无环图为基础的版本控制系统(如Git)来说,就能很好地处理这种应用场景。如果某个分支不含没有合并至当前分支(如db-migration)的“提交”,我们就可以通过“提交”对象的继承关系来确定db-migration分支包含了那个分支的HEAD引用。由于“提交”对象可以包含零个或多个父提交,因此就能通过db-migration中的那次合并提交的信息来确定当前HEAD包含了两个分支中的内容。同理,当将db-migration合并至master分支时也能确认这些关系。
然而有一个问题无论是使用有向无环图还是线性提交都无法解决的,就是判断某个提交是否存在于每个分支中。例如上述例子中,我们假设已经将每个分支的提交都合并到各个分支去了。并不是所有情况下都是如此。
对于较为简单的情况,Git可以将其它分支的“提交”拣选(cherry-pick)到当前分支中,当然前提是这次提交必须是能够直接应用进来的。
6.9 下一步做什么?
上文提到,Git采用来自Unix世界的工具包设计理念,因此非常适合用来编写脚本。但是,当需要在长时间运行的应用程序或服务中内嵌Git工具库的话就不太容易了。虽然目前流行的IDE都提供了Git图形化界面,但开发这些工具所需花费的精力还是比其他版本控制系统要多,因为它们提供了便于使用的链接库。
为了解决这个问题,Shawn Pearce(来自谷歌开源程序办公室)率先实现了一个可供链接的Git类库,且发布协议较为宽松,因此没有阻碍该类库的推广。这个类库的名字是libgit2。一开始它并不流行,直到一个名叫Vincent Marti的学生在谷歌编程夏令营中使用了它。从那以后,Vincent和Github持续对libgit2类库贡献代码,并为其他语言编写了相应类库,包括Ruby,Python,PHP,.NET,Lua,Object-C等。
Shawn Pearce还开启了一个名为JGit的BSD项目,使用纯Java语言实现,能够对Git版本库进行基本的操作。该类库现在由Eclipse基金会维护,用于Eclipse IDE的Git插件中。
还有其他一些有趣的周边项目,带有实验性质,使用各类数据源来保存Git对象,如:
- jgit_cassandra 使用Apache Cassandra作为Git对象数据库。它是一种混合型的数据源,提供了动态的BigTable式的数据模型。
- jgit_hbase 能够将Git对象保存在HBase中,一种KV型分布式数据库。
- libgit2-backends 由libgit2项目衍生而来,致力于提供其他种类的数据源,如Memcached,Redis,SQLite,MySQL。
以上这些都是独立于Git核心工具包之外的项目。
如你所见,我们可以用各种方式来使用Git,它的表现形式不再只有命令行这一种了,而是成为一种版本控制系统的协议。
在本文撰写之时,这些项目都还没有发布稳定版本,所以还是有很多工作要做,但整体看来未来是光明的。
6.10 经验教训
在软件设计中,任何一个决定都有正反两面。作为一个在日常工作中大量使用Git,并且还为Git对象数据库开发了周边软件的程序员,我觉得Git目前的组织方式非常棒。因此,下文提到的“经验教训”更多的是来自其他开发者对于Git目前设计方式的不满,主要归咎于Git核心开发者当初做出的决定。
最常见的问题在于Git相较于其他CVS不能很好地和IDE进行整合,因为Git是基于工具包设计的,整合起来会比较具有挑战性。
早期Git的实现是采用shell脚本的方式,不能很好地跨平台,特别是对于Windows操作系统。虽然我相信Git开发者不会因为这个问题而寝食难安,但这的确阻碍了Git在大型公司内的推广。现在,有一个名为Git for Windows的项目由志愿者发起,及时地将最新的Git开发成果移植到Windows平台上。
Git工具包的设计方式所带来的另一个间接影响是,他的底层命令繁多,会让初学者陷入困境,难以理解Git出错时抛出的异常信息,最后无可适从。这就使得Git在某些开发团队中的推广受到阻碍。
即便如此,我仍然对Git核心项目以及其周边项目的开发充满信心。