
TextWorld 是微软开源的一个可扩展的引擎,可用于生成和模拟文本游戏。你可以使用它来训练强化学习(RL)代理,以学习语言理解、记忆、规划和探索等。
TextWorld 采用 Python 编写,可视为用于在基于文本的游戏上进行训练和测试强化学习(RL)代理的沙盒环境,它还可运行现有的基于文本的游戏,或用来评估 AI 代理在复杂设置中的表现。
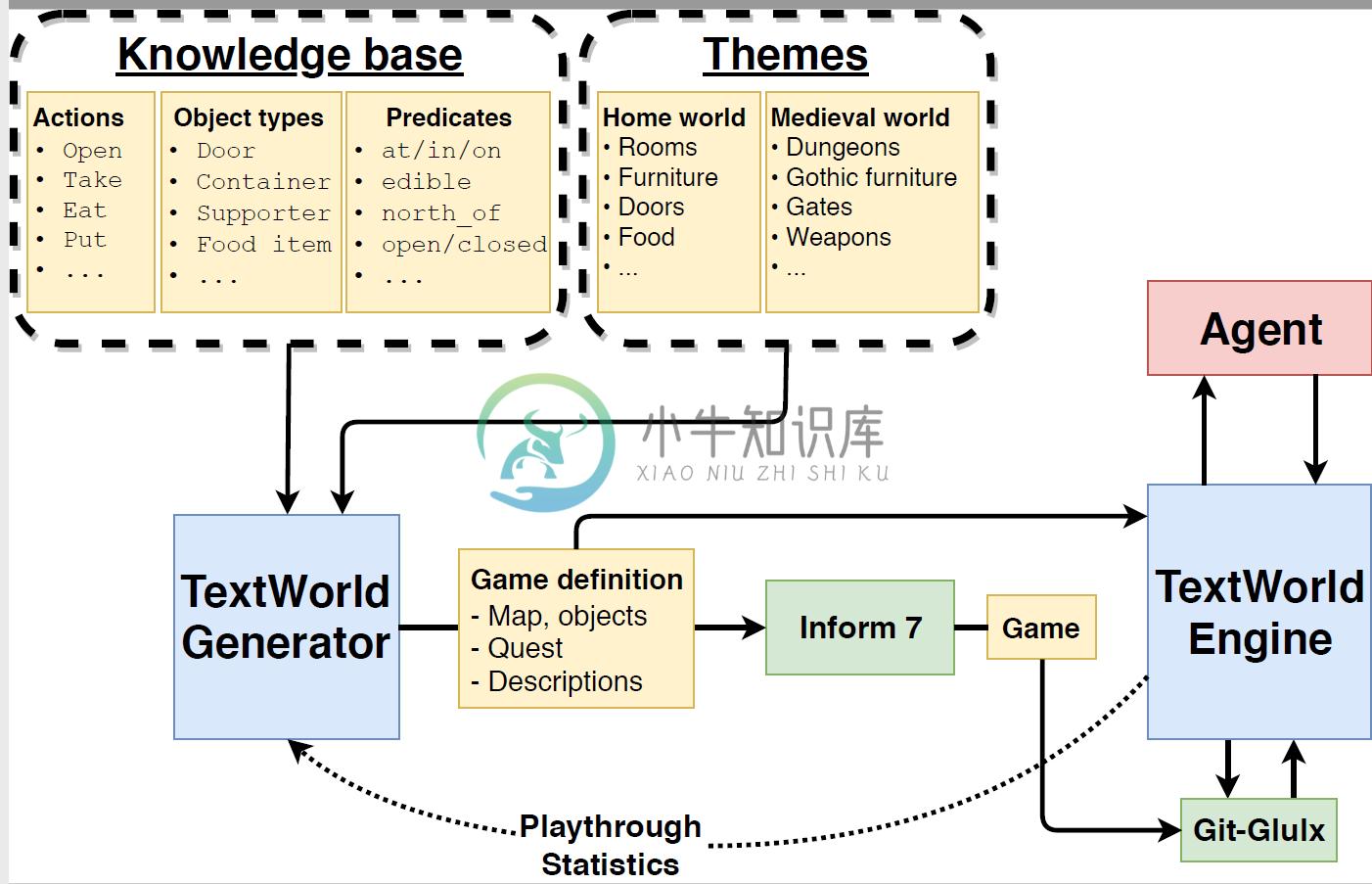
TextWorld 包含两个主要组件:游戏生成器和游戏引擎。游戏生成器将高级游戏规范(例如房间数、对象数、游戏长度和获胜条件)转换为 Inform 7 语言的可执行游戏源代码。游戏引擎是一个简单的推理机器,通过使用简单的算法,如一步向前和向后链接,确保生成的游戏的每一步都是有效的。
-
我计划编写一个国际象棋引擎,它使用深度卷积神经网络来评估国际象棋的位置。我将使用位板来表示棋盘状态,这意味着输入层应该有12*64个神经元用于位置,1个用于玩家移动(0表示黑色,1表示白色)和4个神经元用于铸币权(wks、bks、wqs、bqs)。将有两个隐藏层,每个层有515个神经元,一个输出神经元的值介于-1表示黑色获胜,1表示白色获胜,0表示相等的位置。所有神经元都将使用tanh()激活函数
-
我知道前馈神经网络的基本知识,以及如何使用反向传播算法对其进行训练,但我正在寻找一种算法,以便使用强化学习在线训练神经网络。 例如,我想用人工神经网络解决手推车杆摆动问题。在这种情况下,我不知道应该怎么控制钟摆,我只知道我离理想位置有多近。我需要让安在奖惩的基础上学习。因此,监督学习不是一种选择。 另一种情况类似于蛇游戏,反馈被延迟,并且仅限于进球和反进球,而不是奖励。 我可以为第一种情况想出一些
-
我正在读一本书,Glenn Seemann和David M Bourg的“游戏开发人员的AI”,他们使用视频游戏AI作为基于规则的学习系统的示例。 基本上,玩家有3个可能的移动,并以三次打击的组合命中。人工智能旨在预测玩家的第三次打击。系统的规则是所有可能的三步组合。每个规则都有一个关联的“权重”。每次系统猜错,规则的权重就会降低。当系统必须选择规则时,它会选择权重最高的规则。 这与基于强化学习的
-
主要内容 课程列表 基础知识 专项课程学习 参考书籍 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 MDP和RL介绍8 9 10 11 Berkeley 暂无 链接 MDP简介 暂无 Shaping and policy search in Reinforcement learning 链接 强化学习 UCL An Introduction to Reinforcement Lea
-
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。 Deep Q Learning.
-
新手问题 我正在使用 TensorFlow 编写一个 OpenAI Gym 乒乓球运动员,到目前为止,我已经能够基于随机初始化创建网络,以便它会随机返回以向上或向下移动玩家桨。 时代结束后(在电脑获胜的21场比赛中),我收集了一组观察结果、动作和得分。一场比赛的最后观察得到一个分数,之前的每一次观察都可以根据贝尔曼方程进行评分。 现在我的问题是我还不明白的:我如何计算成本函数,以便它作为反向传播的
-
本文向大家介绍关于机器学习中的强化学习,什么是Q学习?,包括了关于机器学习中的强化学习,什么是Q学习?的使用技巧和注意事项,需要的朋友参考一下 Q学习是一种强化学习算法,其中包含一个“代理”,它采取达到最佳解决方案所需的行动。 强化学习是“半监督”机器学习算法的一部分。将输入数据集提供给强化学习算法时,它会从此类数据集学习,否则会从其经验和环境中学习。 当“强化代理人”执行某项操作时,将根据其是否
-
探索和利用。马尔科夫决策过程。Q 学习,策略学习和深度强化学习。 我刚刚吃了一些巧克力来完成最后这部分。 在监督学习中,训练数据带有来自神一般的“监督者”的答案。如果生活可以这样,该多好! 在强化学习(RL)中,没有这种答案,但是你的强化学习智能体仍然可以决定如何执行它的任务。在缺少现有训练数据的情况下,智能体从经验中学习。在它尝试任务的时候,它通过尝试和错误收集训练样本(这个动作非常好,或者非常