
Lore 是一个 Python 框架,旨在让工程师更容易接受机器学习,让数据科学家更容易维护机器学习。
功能特性
-
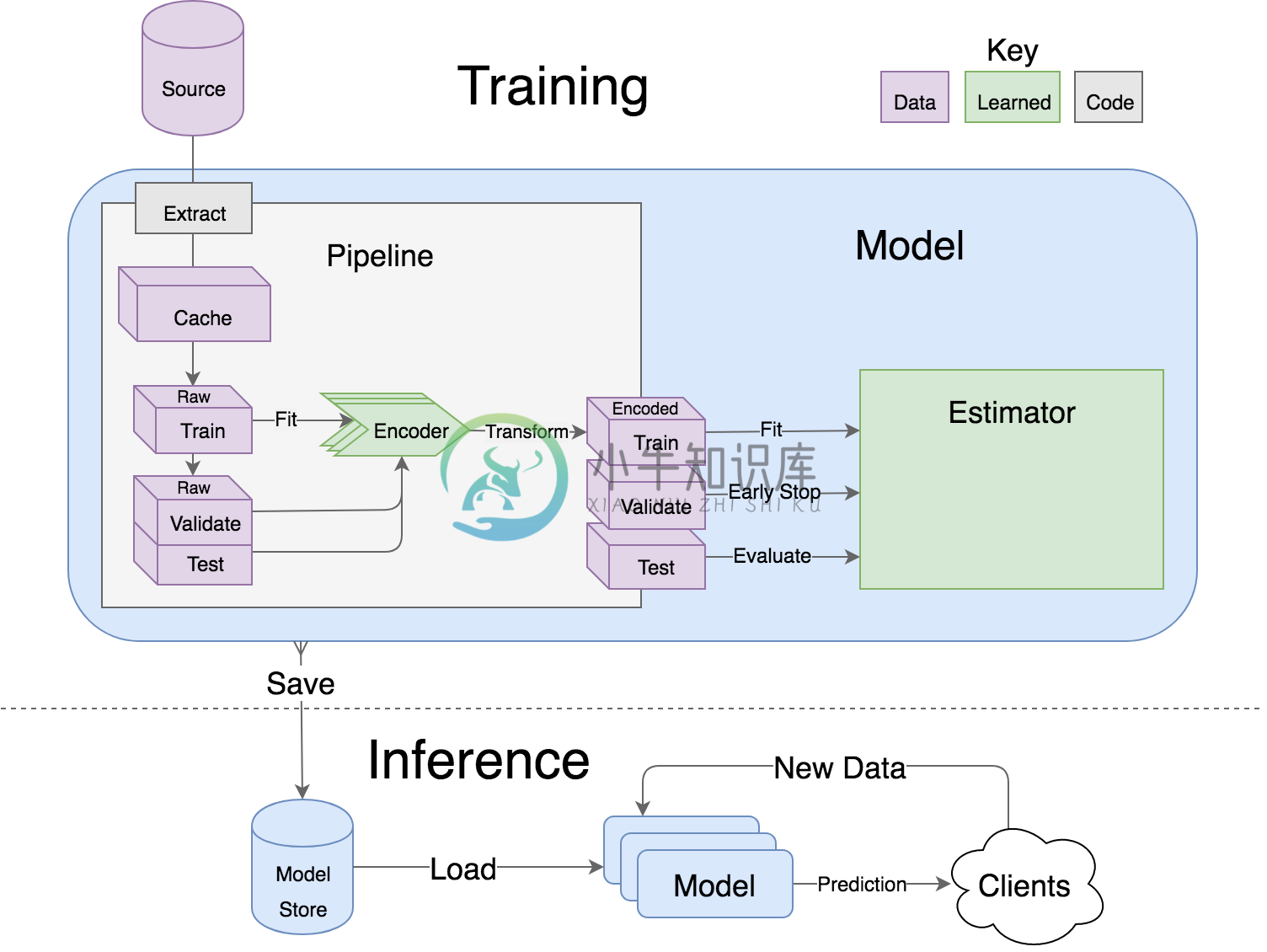
模型支持使用数据管道对估算器进行超参数搜索。他们将有效地利用多个 GPU(如果可用)和几种不同的策略,并且因水平可伸缩性可以保存和分发。
-
支持来自多个软件包的估算器,包括 Keras、XGBoost 和 SciKit Learn。它们都可以通过构建、调试或预测覆盖来进行分类,以完全自定义你的算法和架构,同时还可以从其他很多方面受益。
-
管道可以避免训练和测试之间的信息泄漏,一条管道可以用许多不同的估算器进行实验。如果机器可用 RAM 空间不够,则可使用基于磁盘的管道。
-
转化器标准化高级功能编程。例如,根据美国人口普查数据将美国名字转换为其统计年龄或性别;从自由格式的电话号码字符串中提取地理区号;常见的日期、时间和字符串操作可通过 pandas 得到有效支持。
-
编码器为估算器提供足够的输入,并避免常见的缺失和长尾值问题。经过充分测试,它们可以帮助你避免从垃圾中检索信息。
-
对于流行的 (No)SQL 数据库,整个应用程序以标准化的方式配置 IO 连接,对批量数据进行事务管理和读写优化,而不是使用典型的 ORM 操作。除了用于分发模型和数据集的加密 S3 buckets 之外,连接还共享一个可配置的查询缓存。
-
对开发中的每个应用程序进行依赖关系管理,且可 100%复制到生产环境中。无需手动激活,没有破坏 Python 的环境变量或隐藏的文件。无需 venv、pyenv、pyvenv、virtualenv、virtualenvwrapper、pipenv、conda 相关知识。
-
模型测试可在自己的持续集成环境中进行,允许代码和训练更新持续部署,而不增加基础架构团队的工作量。
-
命令行、Python 控制台、jupyter 笔记本或 IDE 都有工作流支持。每个环境都可以为生产和开发配置可读的日志和时序语句。
-
House of lore House of lore是一种利用small bin的利用方法。 前面我们通过修改unsorted bin与large bin的bk(bk_nextsize)位来造成对”任意“地址的更改。unsorted bin由于修改后,如果无法妥善处理bk指向的chunk的size位、bk位,会造成unsorted bin无法再使用,largebin由于是通过fd_nextsiz
-
# 不要开 debug: false # 更新检测开关 checkUpdate: true # 插件基础配置 general: # 当物品耐久消耗完后,物品是否破损 breakOnDurabilityOff: true # 尽可能使用 RPGInventory 的背包系统 useRPGInventoryIfPossible: true # 使用 SkillAPI 的经验加成 useSkillApi
-
wunai issued server command: /loreitemlevel up [16:06:17] [Server thread/ERROR] [net.minecraft.network.NetHandlerPlayServer]: null org.bukkit.command.CommandException: Unhandled exception executing co
-
# Default config for ItemLoreStats. fileVersion: 607 serverVersion: 1710 checkForUpdates: false#自动检测,true为检测最新版本更新,会一直弹出信息来让你更新,false不检测。 languageFile: language-en usingMcMMO: false usingBarAPI: false
-
fileVersion: 607 #插件版本 serverVersion: 172 #服务器版本 checkForUpdates: false #是否开启自动检查更新 languageFile: language-en #语言文件 usingMcMMO: false #是否使用MCMMOusingBarAPI: true #是否使用BarAPI usingBossBarAPI: false #是否
-
利用思想: 利用smallbin为双向链表,每次malloc取了链表最后一个元素,可以通过更改链表指针,使其分配一个刻意构造的地址 利用难点: 1.需要一个堆溢出或其他方法能够更改到small bin的free chunk的fd和bk指针 2.存在unlink安全检查,需构造好将要malloc出来的位置的chunk(绕过安全检查) 注意:有的触发unlink就是为了得到地址相同的fastbin,从
-
前言 我看了一些网上对于这些技术的解释,但是发现他们大多比较绕,对于理解其中心思想造成了难度,所以 我在这里把他们记录下来,把这些技术的中心思想记下来,作为自己的pwn工具箱,在以后解决pwn问题的 时候能够随时拿出来发挥作用。 我在这里关注的目标是其利用的思想,和其他的一些post不同,利用条件等等这些我个人认为不是能够直 接被总结的,pwn本身的方法多种多样,十分灵活,如果用一些“第一个chu
-
我熟悉算法实现,对机器学习不熟悉,但我在学术和生产之间有差距。 我正在实施推荐系统,学习模型取得了良好的效果,然后我停下来问下一步该怎么办?如何在现有网站上部署它 在学习过程中,我使用了CSV数据集和本地机器,但在线将是拥有数十万用户和数千用户的数据库。所以我认为不可能加载所有数据并向用户推荐东西。 问题是:我将如何在生产中使用我训练过的模型?
-
本文向大家介绍机器学习:知道哪些传统机器学习模型相关面试题,主要包含被问及机器学习:知道哪些传统机器学习模型时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 常见的机器学习算法: 1).回归算法:回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。 常见的回归算法包括:最小二乘法(Ordinary Least Square),逐步式回归(Stepwis
-
有关TensorFlow与其他框架的详细对比可以阅读: https://zhuanlan.zhihu.com/p/25547838 01 TensorFlow的编程模式 编程模式分为两种:命令式编程与符号式编程 前者是我们常用的C++,java等语言的编程风格如下 命令式编程看起来逻辑非常清晰,易于理解。而符号式编程涉及较多的嵌入和优化,如下 执行相同的计算时c,d可以共用内存,使用Tenso
-
Scikit-learn 套件的安装 目前Scikit-learn同时支持Python 2及 3,安装的方式也非常多种。对于初学者,最建议的方式是直接下载 Anaconda Python (https://www.continuum.io/downloads)。同时支持 Windows / OSX/ Linux 等作业系统。相关数据分析套件如Scipy, Numpy, 及图形绘制库 matplot
-
minikube 创建 Kubernetes cluster(单机版)最简单的方法是 minikube。国内网络环境下也可以考虑使用 kubeasz 的 AllInOne 部署。 首先下载 kubectl curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.goog
-
我是ML世界的新手,当阅读关于用训练数据构建模型并最终测试数据以适应要求时,直到这一点我都能够理解,我的问题是一旦测试模型就准备好了 生产部署后是否需要训练/重新训练模型? 如果是这样,做法是什么? 有没有办法持久化假设,以便模型可以使用持久化的结果进行预测? 每天、每周或每月重新训练模型是好的做法吗? 假设spark MLib用于构建模型 让我补充更多细节。当我训练模型时,为了论证,它会在预生产
-
什么是机器学习? 机器学习是自动从数据中提取知识的过程,通常是为了预测新的,看不见的数据。一个典型的例子是垃圾邮件过滤器,用户将传入的邮件标记为垃圾邮件或非垃圾邮件。然后,机器学习算法从数据“学习”预测模型,数据区分垃圾邮件和普通电子邮件。该模型可以预测新电子邮件是否是垃圾邮件。 机器学习的核心是根据数据来自动化决策的概念,无需用户指定如何做出此决策的明确规则。 对于电子邮件,用户不提供垃圾邮件的
-
Python 有着海量的可用于数据分析、统计以及机器学习的库,这使得 Python 成为很多数据科学家所选择的语言。 下面我们列出了一些被广泛使用的机器学习及其他数据科学应用的 Python 包。 Scipy 技术栈 Scipy 技术栈由一大批在数据科学中被广泛使用的核心辅助包构成,可用于统计分析与数据可视化。由于其丰富的功能和简单易用的特性,这一技术栈已经被视作实现大多数数据科学应用的必备品了。