
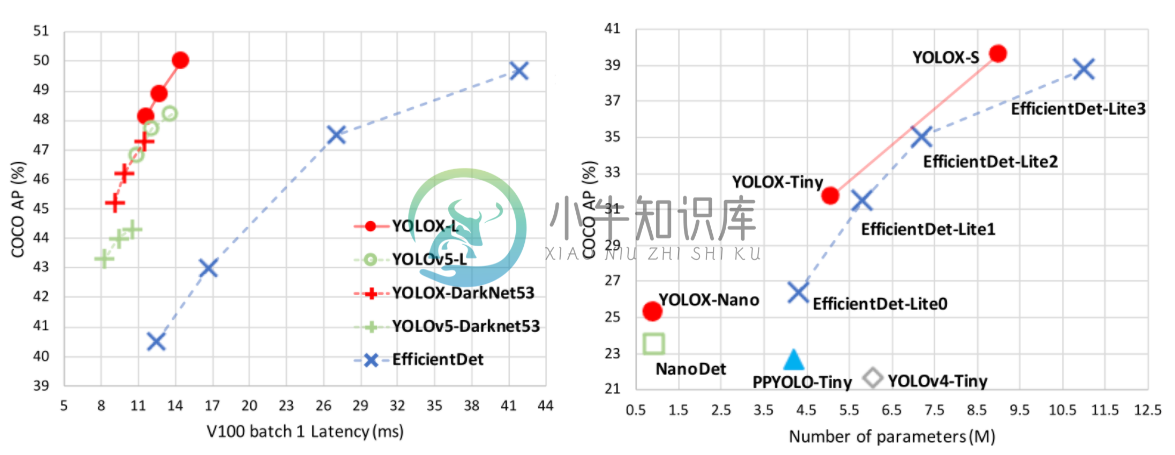
YOLOX 是旷视开源的高性能检测器。旷视的研究者将解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展与 YOLO 进行了巧妙的集成组合,提出了 YOLOX,不仅实现了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。

性能对比:
-
yolox筛选正负样本的方式 yolox采用anchor free的方式,筛选正负样本时包括3个步骤: 初筛根据目标框判断,根据anchor(一个长宽相同的框,和anchor base方法不同)中心点是否落在gt内,也就是计算anchor中心点离gt左右上下4条边的距离是否同时大于0; 初筛根据中心区域判断,寻找anchor中心点是否在gt中心点附近55区域内,判断anchor中心点离55区域的左
-
1.Yolox下载 https://blog.csdn.net/weixin_41869644/article/details/120120471 ps:如果coco数据集无法下载成功,请打开手机热点重试 2. Yolox官方网站 https://yolox.readthedocs.io/en/latest/quick_run.html 3.Yolo训练句的解释 (1) python tools/
-
旷视科技的yolox号称最好的yolo paper: https://arxiv.org/abs/2107.08430 code: https://github.com/Megvii-BaseDetection/YOLOX 安装 Step1. Install YOLOX from source. git clone git@github.com:Megvii-BaseDetection/YOLOX
-
@subpage tutorial_py_face_detection_cn 人脸识别 使用 haar-cascades
-
我正在编写一个应用程序,它需要监听麦克风并给我一个实时的振幅和音调输出。我已经找到了如何进行音高识别的方法。我对fft做了很多研究。找到了Android库TarsosDSP wich,使听音高变得非常简单: 我还研究了如何使用内置android进行振幅检测。GetMaxAmplific()方法。 但我的问题是,我一辈子都不知道如何同时做这两件事。问题是你显然可以运行多个麦克风实例。就像你试图在不同
-
在“锚框”一节中,我们在实验中以输入图像的每个像素为中心生成多个锚框。这些锚框是对输入图像不同区域的采样。然而,如果以图像每个像素为中心都生成锚框,很容易生成过多锚框而造成计算量过大。举个例子,假设输入图像的高和宽分别为561像素和728像素,如果以每个像素为中心生成5个不同形状的锚框,那么一张图像上则需要标注并预测200多万个锚框($561 \times 728 \times 5$)。 减少锚框
-
问题内容: 我有一个根视图控制器,没有将其设置为故事板上的任何视图控制器的自定义类。相反,我所有的视图控制器都将此类子类化。 但是,当在视图控制器上按下tabbaritem时,我似乎正在做某事,该控件是rootviewcontroller的子类,即消息未打印。 问题答案: 您不希望视图控制器的基类是UITabBarDelegate。如果要这样做,则所有视图控制器子类都将是标签栏委托。我认为您想要做
-
使用https://altbeacon.github.io/android-beacon-library/samples.html中的代码试图检测IBeacon发射器,该发射器是iOS8,如下http://blog.passkit.com/configure-iphone-ibeacon-transmiter/,在哪一步出错了,我需要在区域中使用BeaconIdentifier作为mymonito
-
在前面的一些章节中,我们介绍了诸多用于图像分类的模型。在图像分类任务里,我们假设图像里只有一个主体目标,并关注如何识别该目标的类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。 目标检测在多个领域中被广泛使用。例如,在无人驾驶里,我们需要通过识别拍摄到