
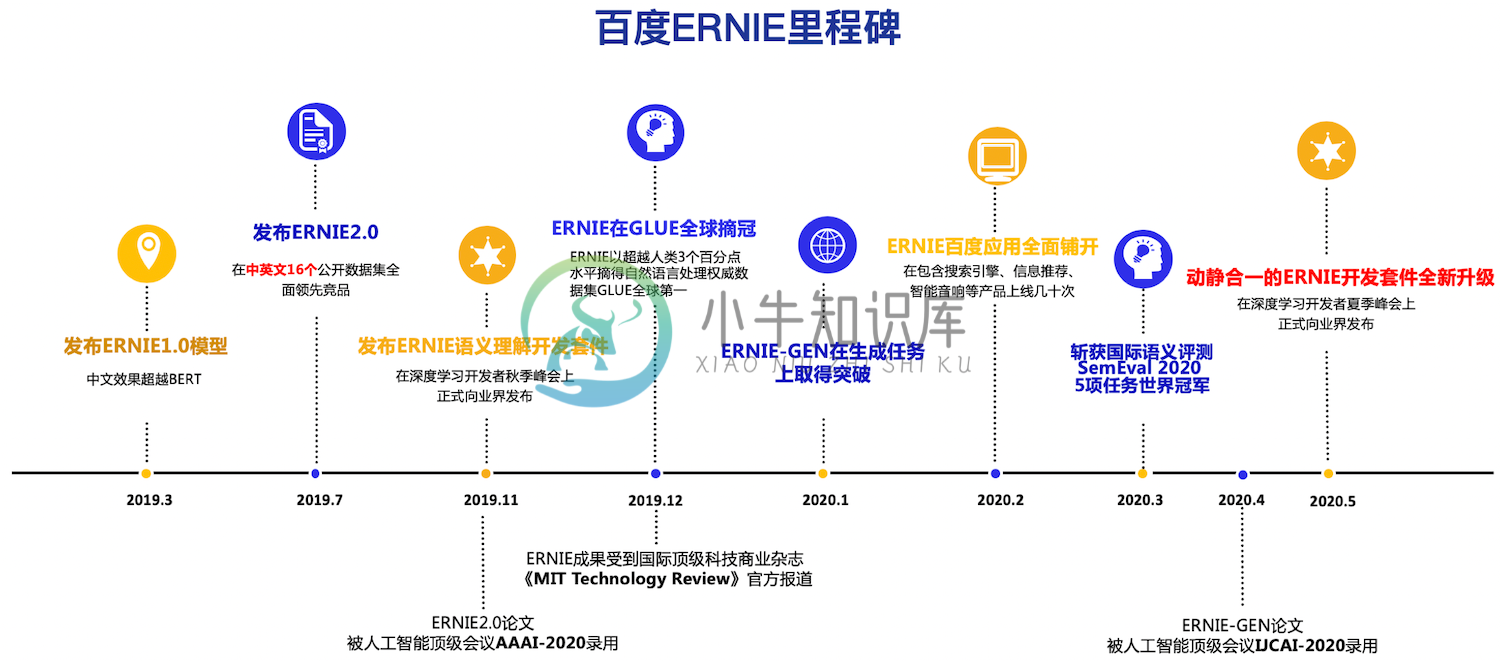
ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在情感分析、文本匹配、自然语言推理、词法分析、阅读理解、智能问答等16个公开数据集上全面显著超越世界领先技术,在国际权威的通用语言理解评估基准GLUE上,得分首次突破90分,获得全球第一。在今年3月落下帷幕的全球最大语义评测SemEval 2020上,ERNIE摘得5项世界冠军, 该技术也被全球顶级科技商业杂志《麻省理工科技评论》官方网站报道,相关创新成果也被国际顶级学术会议AAAI、IJCAI收录。ERNIE在工业界得到了大规模应用,如搜索引擎、新闻推荐、广告系统、语音交互、智能客服等。
提醒: ERNIE老版本代码已经迁移至repro分支,欢迎使用我们全新升级的基于动静结合的新版ERNIE套件进行开发。另外,也欢迎上EasyDL体验更丰富的功能(如ERNIE 2.0、ERNIE 2.1、ERNIE领域模型等)。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
在 ERNIE 2.0 中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0 语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。
-
介绍下ERNIE: 1、介绍ERNIE是什么,解决什么任务: 2、输入输出是什么 3、模型结构是什么:里面的关键点是什么。 1、ERNIE是百度针对bert在中文语料上预训练不足的问题上所提出来的,通过这个模型,中文很多任务可以用ERNIE模型解决。 2、MLM任务,举个例子: ERNIE的输入:比如一句话:哈尔滨是一个冰雪城市。 那么mask掉其中的哈尔滨。通过ERNIE模型的训练之后,我们可以
-
本文向大家介绍基于pytorch 预训练的词向量用法详解,包括了基于pytorch 预训练的词向量用法详解的使用技巧和注意事项,需要的朋友参考一下 如何在pytorch中使用word2vec训练好的词向量 这个方法是在pytorch中将词向量和词对应起来的一个方法. 一般情况下,如果我们直接使用下面的这种: 这种情况下, 因为没有指定训练好的词向量, 所以embedding会帮咱们生成一个随机的词
-
PyTorch开发了与数据交互的标准约定,所以能一致地处理数据,而不论处理图像、文本还是音频。与数据交互的两个主要约定是数据集(dataset)和数据加载器(dataloader)。数据集是一个Python类,使我们能获得提供给神经网络的数据。数据加载器则从数据集向网络提供数据。
-
我计划编写一个国际象棋引擎,它使用深度卷积神经网络来评估国际象棋的位置。我将使用位板来表示棋盘状态,这意味着输入层应该有12*64个神经元用于位置,1个用于玩家移动(0表示黑色,1表示白色)和4个神经元用于铸币权(wks、bks、wqs、bqs)。将有两个隐藏层,每个层有515个神经元,一个输出神经元的值介于-1表示黑色获胜,1表示白色获胜,0表示相等的位置。所有神经元都将使用tanh()激活函数
-
尝试一周,能改变一些旧习 一个一个练,反复的使用即可 不求多,以下练熟悉即可 practice makes prefect~ 放弃鼠标 全键盘和触摸板,你可以么? 从熟悉快捷键开始 全屏 专心写代码,减少干扰 ctrl + command + f 放大到全屏 设置Workbench主菜单快捷键,快速切换 设置Workbench主菜单快捷键,然后就有了command + 1到4的快捷键,快速切换,效
-
问题内容: 我想知道是否有可能保存经过部分训练的Keras模型并在再次加载模型后继续进行训练。 这样做的原因是,将来我将拥有更多的训练数据,并且我不想再次对整个模型进行训练。 我正在使用的功能是: 编辑1:添加了完全正常的示例 对于10个纪元后的第一个数据集,最后一个纪元的损失将为0.0748,精度为0.9863。 保存,删除和重新加载模型后,第二个数据集上训练的模型的损失和准确性分别为0.171
-
我只是用TensorFlow训练了一个三层的softmax神经网络。它来自吴恩达的课程,3.11TensorFlow。我修改代码是为了查看每个历元的测试和训练精度。 当我增加学习率时,成本在1.9左右,而准确率保持1.66...7不变。我发现学习率越高,它发生的频率就越高。当learing_rate在0.001左右时,有时会出现这种情况。当learing_rate在0.0001附近时,这种情况不会
-
我知道前馈神经网络的基本知识,以及如何使用反向传播算法对其进行训练,但我正在寻找一种算法,以便使用强化学习在线训练神经网络。 例如,我想用人工神经网络解决手推车杆摆动问题。在这种情况下,我不知道应该怎么控制钟摆,我只知道我离理想位置有多近。我需要让安在奖惩的基础上学习。因此,监督学习不是一种选择。 另一种情况类似于蛇游戏,反馈被延迟,并且仅限于进球和反进球,而不是奖励。 我可以为第一种情况想出一些
-
本文向大家介绍解决tensorflow训练时内存持续增加并占满的问题,包括了解决tensorflow训练时内存持续增加并占满的问题的使用技巧和注意事项,需要的朋友参考一下 记录一次小白的tensorflow学习过程,也为有同样困扰的小白留下点经验。 先说我出错和解决的过程。在做风格迁移实验时,使用预加载权重的VGG19网络正向提取中间层结果,结果因为代码不当,在遍历图片提取时内存持续增长,导致提取