Spark Take函数
在Spark中,take函数的行为类似于数组。它接收一个整数值(比方说,n)作为参数,并返回数据集的前n个元素的数组。
Take函数示例
在此示例中,返回现有数据集的前n个元素。要在Scala模式下打开Spark,请按照以下命令操作。
$ spark-shell

在此示例中,检索数据集的第一个元素。要在Scala模式下打开Spark,请按照以下命令操作。
$ spark-shell
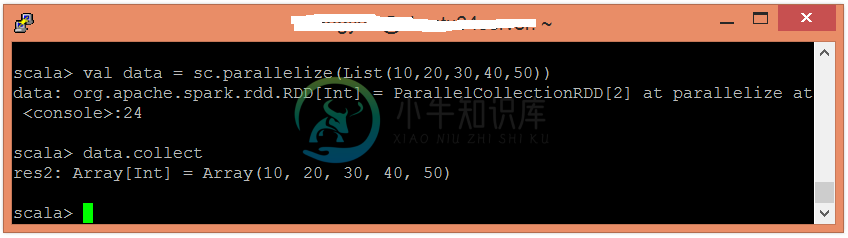
使用并行化集合创建RDD。
scala> val data = sc.parallelize(List(10,20,30,40,50))
现在,可以使用以下命令读取生成的结果。
scala> data.collect
应用take()函数来检索数据集一个元素。
scala> val takefunc = data.take()
