目录实现
有很多算法可以使用这些目录来实现。 但是,选择合适的目录实现算法可能会显着影响系统的性能。
目录实现算法根据它们正在使用的数据结构进行分类。 目前主要使用两种算法。
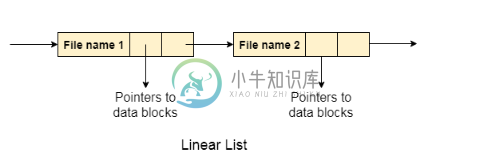
1. 线性列表
在这个算法中,目录中的所有文件都保持为单行列表。 每个文件都包含指向分配给它的数据块的指针和目录中的下一个文件。
特点
在创建新文件时,检查整个列表是否新文件名与现有文件名匹配。 如果它不存在,则可以在开始或结束时创建该文件。 因此,寻找一个唯一的名字是一个大问题,因为遍历整个列表需要时间。
该列表需要在文件的每个操作(创建,删除,更新等)的情况下遍历,因此系统变得低效。
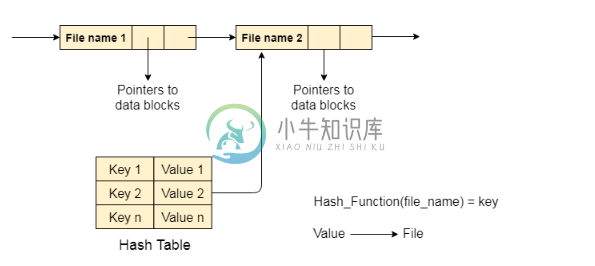
2. 哈希表
要克服目录单链表实现的缺点,有一种替代方法就是哈希表。 这种方法建议使用散列表和链表。
目录中每个文件的键值对都会生成并存储在哈希表中。键可以通过在文件名上应用散列函数来确定,而键指向存储在目录中的相应文件。
现在,搜索变得高效,因为整个列表在每次操作时都不会被搜索到。 只有哈希表项被使用该键检查,并且如果找到的条目然后将使用该值来获取相应的文件。