
利用TensorFlow训练简单的二分类神经网络模型的方法

利用TensorFlow实现《神经网络与机器学习》一书中4.7模式分类练习
具体问题是将如下图所示双月牙数据集分类。
使用到的工具:
python3.5 tensorflow1.2.1 numpy matplotlib
1.产生双月环数据集
def produceData(r,w,d,num): r1 = r-w/2 r2 = r+w/2 #上半圆 theta1 = np.random.uniform(0, np.pi ,num) X_Col1 = np.random.uniform( r1*np.cos(theta1),r2*np.cos(theta1),num)[:, np.newaxis] X_Row1 = np.random.uniform(r1*np.sin(theta1),r2*np.sin(theta1),num)[:, np.newaxis] Y_label1 = np.ones(num) #类别标签为1 #下半圆 theta2 = np.random.uniform(-np.pi, 0 ,num) X_Col2 = (np.random.uniform( r1*np.cos(theta2),r2*np.cos(theta2),num) + r)[:, np.newaxis] X_Row2 = (np.random.uniform(r1 * np.sin(theta2), r2 * np.sin(theta2), num) -d)[:,np.newaxis] Y_label2 = -np.ones(num) #类别标签为-1,注意:由于采取双曲正切函数作为激活函数,类别标签不能为0 #合并 X_Col = np.vstack((X_Col1, X_Col2)) X_Row = np.vstack((X_Row1, X_Row2)) X = np.hstack((X_Col, X_Row)) Y_label = np.hstack((Y_label1,Y_label2)) Y_label.shape = (num*2 , 1) return X,Y_label
其中r为月环半径,w为月环宽度,d为上下月环距离(与书中一致)
2.利用TensorFlow搭建神经网络模型
2.1 神经网络层添加
def add_layer(layername,inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
with tf.variable_scope(layername,reuse=None):
Weights = tf.get_variable("weights",shape=[in_size, out_size],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", shape=[1, out_size],
initializer=tf.truncated_normal_initializer(stddev=0.1))
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
2.2 利用tensorflow建立神经网络模型
输入层大小:2
隐藏层大小:20
输出层大小:1
激活函数:双曲正切函数
学习率:0.1(与书中略有不同)
(具体的搭建过程可参考莫烦的视频,链接就不附上了自行搜索吧......)
###define placeholder for inputs to network xs = tf.placeholder(tf.float32, [None, 2]) ys = tf.placeholder(tf.float32, [None, 1]) ###添加隐藏层 l1 = add_layer("layer1",xs, 2, 20, activation_function=tf.tanh) ###添加输出层 prediction = add_layer("layer2",l1, 20, 1, activation_function=tf.tanh) ###MSE 均方误差 loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction), reduction_indices=[1])) ###优化器选取 学习率设置 此处学习率置为0.1 train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) ###tensorflow变量初始化,打开会话 init = tf.global_variables_initializer()#tensorflow更新后初始化所有变量不再用tf.initialize_all_variables() sess = tf.Session() sess.run(init)
2.3 训练模型
###训练2000次
for i in range(2000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_label})
3.利用训练好的网络模型寻找分类决策边界
3.1 产生二维空间随机点
def produce_random_data(r,w,d,num): X1 = np.random.uniform(-r-w/2,2*r+w/2, num) X2 = np.random.uniform(-r - w / 2-d, r+w/2, num) X = np.vstack((X1, X2)) return X.transpose()
3.2 用训练好的模型采集决策边界附近的点
向网络输入一个二维空间随机点,计算输出值大于-0.5小于0.5即认为该点落在决策边界附近(双曲正切函数)
def collect_boundary_data(v_xs):
global prediction
X = np.empty([1,2])
X = list()
for i in range(len(v_xs)):
x_input = v_xs[i]
x_input.shape = [1,2]
y_pre = sess.run(prediction, feed_dict={xs: x_input})
if abs(y_pre - 0) < 0.5:
X.append(v_xs[i])
return np.array(X)
3.3 用numpy工具将采集到的边界附近点拟合成决策边界曲线,用matplotlib.pyplot画图
###产生空间随机数据 X_NUM = produce_random_data(10, 6, -4, 5000) ###边界数据采样 X_b = collect_boundary_data(X_NUM) ###画出数据 fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ###设置坐标轴名称 plt.xlabel('x1') plt.ylabel('x2') ax.scatter(x_data[:, 0], x_data[:, 1], marker='x') ###用采样的边界数据拟合边界曲线 7次曲线最佳 z1 = np.polyfit(X_b[:, 0], X_b[:, 1], 7) p1 = np.poly1d(z1) x = X_b[:, 0] x.sort() yvals = p1(x) plt.plot(x, yvals, 'r', label='boundray line') plt.legend(loc=4) #plt.ion() plt.show()
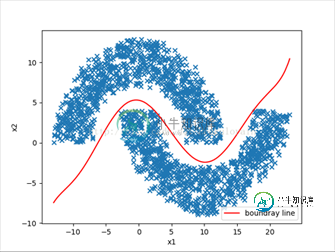
4.效果
5.附上源码Github链接
https://github.com/Peakulorain/Practices.git 里的PatternClassification.py文件
另注:分类问题还是用softmax去做吧.....我只是用这做书上的练习而已。
(初学者水平有限,有问题请指出,各位大佬轻喷)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍tensorflow入门之训练简单的神经网络方法,包括了tensorflow入门之训练简单的神经网络方法的使用技巧和注意事项,需要的朋友参考一下 这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入。也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数。 2.定义神经网络的结
-
本文向大家介绍tensorflow学习笔记之简单的神经网络训练和测试,包括了tensorflow学习笔记之简单的神经网络训练和测试的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了用简单的神经网络来训练和测试的具体代码,供大家参考,具体内容如下 刚开始学习tf时,我们从简单的地方开始。卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始。
-
是否有方法按层(而不是端到端)训练卷积神经网络,以了解每一层对最终架构性能的贡献?
-
在本章中,我们将了解可以使用TensorFlow框架实现的神经网络训练的各个方面。 以下几个建议,可以评估 - 1. 反向传播 反向传播是计算偏导数的简单方法,其中包括最适合神经网络的基本形式的合成。 2. 随机梯度下降 在随机梯度下降中,批处理是示例的总数,用户用于在单次迭代中计算梯度。到目前为止,假设批处理已经是整个数据集。最好的例子是谷歌规模; 数据集通常包含数十亿甚至数千亿个示例。 3.
-
我有一个关于卷积神经网络()训练的问题。 我成功地使用tensorflow训练了一个网络,它获取一个输入图像(1600像素),然后输出三个匹配的类中的一个。 使用不同的培训课程测试网络,效果良好。然而当我给它一个不同的第四个图像(不包含任何经过训练的3个图像)时,它总是返回一个随机匹配到其中一个类。 我的问题是,如何训练网络来分类图像不属于这三个训练图像中的任何一个?类似的例子是,如果我针对mni
-
感谢您查看我的问题。我正在尝试根据一些预训练模型进行图像分类,图像应该分类到40个类。我想使用VGG和Xcept预训练模型将每张图像转换为两个1000维向量,并将它们堆叠到一个1*2000维向量作为我网络的输入,网络有40维输出。网络有2个隐藏层,一个有1024个神经元,另一个有512个神经元。 结构:图像- 然而,使用这种结构,我只能达到大约30%的精度。因此,我的问题是,如何优化网络结构以实现